A Konwolucyjna sieć neuronowa (CNN) to rodzaj architektury sieci neuronowej głębokiego uczenia się powszechnie stosowanej w przetwarzaniu obrazu komputerowego. Widzenie komputerowe to dziedzina sztucznej inteligencji, która umożliwia komputerowi zrozumienie i interpretację obrazu lub danych wizualnych.
Jeśli chodzi o uczenie maszynowe, Sztuczne sieci neuronowe spisać się naprawdę dobrze. Sieci neuronowe są używane w różnych zbiorach danych, takich jak obrazy, dźwięk i tekst. Różne typy sieci neuronowych są wykorzystywane do różnych celów, na przykład do przewidywania sekwencji słów, których używamy Rekurencyjne sieci neuronowe dokładniej an LSTM , podobnie do klasyfikacji obrazów używamy sieci Convolution Neural. Na tym blogu zbudujemy podstawowy element CNN.
W zwykłej sieci neuronowej istnieją trzy typy warstw:
- Warstwy wejściowe: Jest to warstwa, w której przekazujemy dane wejściowe do naszego modelu. Liczba neuronów w tej warstwie jest równa całkowitej liczbie cech w naszych danych (liczbie pikseli w przypadku obrazu).
- Ukryta warstwa: Dane wejściowe z warstwy wejściowej są następnie przekazywane do warstwy ukrytej. Może istnieć wiele ukrytych warstw w zależności od naszego modelu i rozmiaru danych. Każda warstwa ukryta może mieć różną liczbę neuronów, która jest na ogół większa niż liczba cech. Dane wyjściowe każdej warstwy są obliczane poprzez mnożenie macierzy wyników poprzedniej warstwy przez możliwe do nauczenia wagi tej warstwy, a następnie dodanie możliwych do nauczenia odchyleń, a następnie funkcję aktywacji, która sprawia, że sieć jest nieliniowa.
- Warstwa wyjściowa: Dane wyjściowe z warstwy ukrytej są następnie podawane do funkcji logistycznej, takiej jak sigmoid lub softmax, która przekształca dane wyjściowe każdej klasy na wynik prawdopodobieństwa każdej klasy.
Dane są wprowadzane do modelu, a dane wyjściowe z każdej warstwy są uzyskiwane w powyższym kroku wyprzedzający , następnie obliczamy błąd za pomocą funkcji błędu. Niektóre typowe funkcje błędu to entropia krzyżowa, błąd straty kwadratowej itp. Funkcja błędu mierzy wydajność sieci. Następnie propagujemy wstecznie do modelu, obliczając pochodne. Ten krok nazywa się Konwolucyjna sieć neuronowa (CNN) to rozszerzona wersja sztuczne sieci neuronowe (ANN) który jest głównie używany do wyodrębnienia funkcji ze zbioru danych macierzy przypominającej siatkę. Na przykład wizualne zbiory danych, takie jak obrazy lub filmy, w których wzorce danych odgrywają rozległą rolę.
Architektura CNN
Konwolucyjna sieć neuronowa składa się z wielu warstw, takich jak warstwa wejściowa, warstwa splotowa, warstwa łączenia i warstwy w pełni połączone.

Prosta architektura CNN
wiek Pete'a Davidsona
Warstwa splotowa stosuje filtry do obrazu wejściowego w celu wyodrębnienia cech, warstwa łączenia próbkuje obraz w dół, aby ograniczyć obliczenia, a warstwa w pełni połączona dokonuje ostatecznej prognozy. Sieć uczy się optymalnych filtrów poprzez propagację wsteczną i opadanie gradientu.
Jak działają warstwy splotowe
Splotowe sieci neuronowe lub sieci neuronowe to sieci neuronowe o wspólnych parametrach. Wyobraź sobie, że masz obraz. Można go przedstawić jako prostopadłościan mający jego długość, szerokość (wymiar obrazu) i wysokość (tj. kanał, ponieważ obrazy zazwyczaj mają kanały czerwony, zielony i niebieski).
Teraz wyobraź sobie, że bierzesz mały fragment tego obrazu i uruchamiasz małą sieć neuronową, zwaną filtrem lub jądrem, z, powiedzmy, K wyjść i reprezentacją ich w pionie. Teraz przesuń tę sieć neuronową po całym obrazie, w rezultacie otrzymamy kolejny obraz o różnych szerokościach, wysokościach i głębokościach. Zamiast samych kanałów R, G i B mamy teraz więcej kanałów, ale mniejszą szerokość i wysokość. Ta operacja nazywa się Skręt . Jeśli rozmiar fragmentu jest taki sam jak rozmiar obrazu, będzie to zwykła sieć neuronowa. Z powodu tej małej łaty mamy mniej ciężarków.
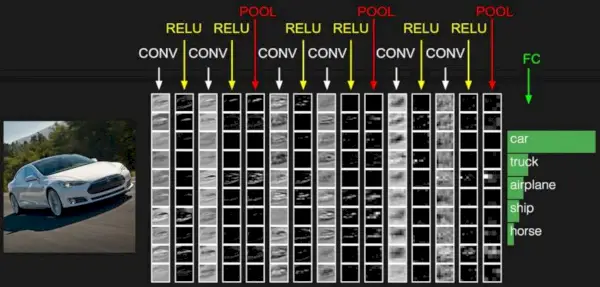
Źródło obrazu: Deep Learning Udacity
Porozmawiajmy teraz o odrobinie matematyki związanej z całym procesem splotu.
- Warstwy splotu składają się z zestawu dających się nauczyć filtrów (lub jąder) o małych szerokościach i wysokościach oraz tej samej głębokości co objętość wejściowa (3, jeśli warstwą wejściową jest wejściowy obraz).
- Na przykład, jeśli musimy uruchomić splot na obrazie o wymiarach 34x34x3. Możliwy rozmiar filtrów może wynosić axax3, gdzie „a” może mieć dowolną wartość, np. 3, 5 lub 7, ale jest mniejsza w porównaniu z wymiarem obrazu.
- Podczas przejścia do przodu przesuwamy każdy filtr krok po kroku przez całą głośność wejściową, gdzie wywoływany jest każdy krok krok (które mogą mieć wartość 2, 3 lub nawet 4 w przypadku obrazów wielowymiarowych) i obliczyć iloczyn skalarny między wagami jądra a łatą z objętości wejściowej.
- Kiedy przesuwamy nasze filtry, otrzymamy wyjście 2-D dla każdego filtra i połączymy je razem, w wyniku czego otrzymamy objętość wyjściową o głębokości równej liczbie filtrów. Sieć nauczy się wszystkich filtrów.
Warstwy używane do budowy ConvNets
Kompletna architektura sieci neuronowych Convolution jest również znana jako covnets. Covnets to sekwencja warstw, a każda warstwa przekształca jedną objętość w drugą poprzez funkcję różniczkowalną.
Rodzaje warstw: zbiory danych
Weźmy przykład, uruchamiając covnets na obrazie o wymiarach 32 x 32 x 3.
- Warstwy wejściowe: Jest to warstwa, w której przekazujemy dane wejściowe do naszego modelu. W CNN zazwyczaj danymi wejściowymi będzie obraz lub sekwencja obrazów. Warstwa ta przechowuje surowe dane wejściowe obrazu o szerokości 32, wysokości 32 i głębokości 3.
- Warstwy splotowe: Jest to warstwa używana do wyodrębnienia obiektu z wejściowego zbioru danych. Do obrazów wejściowych stosuje zestaw możliwych do nauczenia się filtrów, zwanych jądrami. Filtry/jądra to mniejsze matryce, zwykle o kształcie 2×2, 3×3 lub 5×5. przesuwa się po danych obrazu wejściowego i oblicza iloczyn skalarny między wagą jądra a odpowiednią poprawką obrazu wejściowego. Dane wyjściowe tej warstwy nazywane są mapami obiektów. Załóżmy, że użyjemy łącznie 12 filtrów dla tej warstwy, otrzymamy objętość wyjściową o wymiarach 32 x 32 x 12.
- Warstwa aktywacji: Dodając funkcję aktywacji do wyjścia poprzedniej warstwy, warstwy aktywacji dodają nieliniowość do sieci. zastosuje elementową funkcję aktywacji do wyjścia warstwy splotu. Niektóre typowe funkcje aktywacji to wznawiać : maks. (0, x), Podejrzany , Nieszczelny RELU itp. Objętość pozostaje niezmieniona, stąd objętość wyjściowa będzie miała wymiary 32 x 32 x 12.
- Warstwa łącząca: Warstwa ta jest okresowo wstawiana w sieci, a jej główną funkcją jest zmniejszanie wielkości objętości, co sprawia, że obliczenia szybko zmniejszają pamięć, a także zapobiegają nadmiernemu dopasowaniu. Dwa popularne typy warstw łączenia to maksymalne łączenie I średnie łączenie . Jeśli użyjemy maksymalnej puli z filtrami 2 x 2 i krokiem 2, uzyskana objętość będzie miała wymiar 16x16x12.
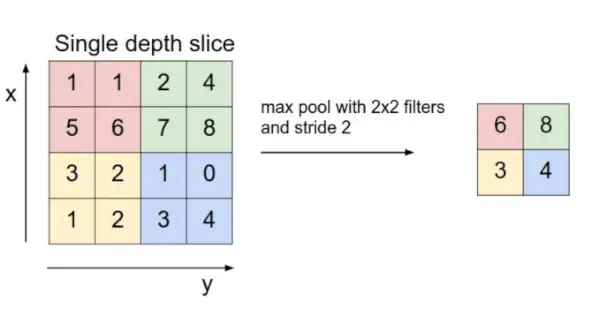
Źródło obrazu: cs231n.stanford.edu
- Spłaszczenie: Powstałe mapy obiektów są spłaszczane do jednowymiarowego wektora po splocie i łączeniu warstw, dzięki czemu można je przekazać do całkowicie połączonej warstwy w celu kategoryzacji lub regresji.
- W pełni połączone warstwy: Pobiera dane wejściowe z poprzedniej warstwy i oblicza ostateczne zadanie klasyfikacji lub regresji.
Źródło obrazu: cs231n.stanford.edu
wątek.zniszcz
- Warstwa wyjściowa: Dane wyjściowe z w pełni połączonych warstw są następnie wprowadzane do funkcji logistycznej do zadań klasyfikacyjnych, takich jak sigmoid lub softmax, która przekształca dane wyjściowe każdej klasy na wynik prawdopodobieństwa każdej klasy.
Przykład:
Rozważmy obraz i zastosujmy warstwę splotu, warstwę aktywacji i operację warstwy łączenia, aby wyodrębnić cechę wewnętrzną.
Obraz wejściowy:
Obraz wejściowy
Krok:
- zaimportuj niezbędne biblioteki
- ustawić parametr
- zdefiniuj jądro
- Załaduj obraz i wydrukuj go.
- Sformatuj obraz
- Zastosuj operację warstwy splotu i wykreśl obraz wyjściowy.
- Zastosuj operację warstwy aktywacyjnej i wykreśl obraz wyjściowy.
- Zastosuj operację warstwy łączenia i wykreśl obraz wyjściowy.
Python3
# import the necessary libraries> import> numpy as np> import> tensorflow as tf> import> matplotlib.pyplot as plt> from> itertools>import> product> > # set the param> plt.rc(>'figure'>, autolayout>=>True>)> plt.rc(>'image'>, cmap>=>'magma'>)> > # define the kernel> kernel>=> tf.constant([[>->1>,>->1>,>->1>],> >[>->1>,>8>,>->1>],> >[>->1>,>->1>,>->1>],> >])> > # load the image> image>=> tf.io.read_file(>'Ganesh.webp'plain'>)> image>=> tf.io.decode_jpeg(image, channels>=>1>)> image>=> tf.image.resize(image, size>=>[>300>,>300>])> > # plot the image> img>=> tf.squeeze(image).numpy()> plt.figure(figsize>=>(>5>,>5>))> plt.imshow(img, cmap>=>'gray'>)> plt.axis(>'off'>)> plt.title(>'Original Gray Scale image'>)> plt.show();> > > # Reformat> image>=> tf.image.convert_image_dtype(image, dtype>=>tf.float32)> image>=> tf.expand_dims(image, axis>=>0>)> kernel>=> tf.reshape(kernel, [>*>kernel.shape,>1>,>1>])> kernel>=> tf.cast(kernel, dtype>=>tf.float32)> > # convolution layer> conv_fn>=> tf.nn.conv2d> > image_filter>=> conv_fn(> >input>=>image,> >filters>=>kernel,> >strides>=>1>,># or (1, 1)> >padding>=>'SAME'>,> )> > plt.figure(figsize>=>(>15>,>5>))> > # Plot the convolved image> plt.subplot(>1>,>3>,>1>)> > plt.imshow(> >tf.squeeze(image_filter)> )> plt.axis(>'off'>)> plt.title(>'Convolution'>)> > # activation layer> relu_fn>=> tf.nn.relu> # Image detection> image_detect>=> relu_fn(image_filter)> > plt.subplot(>1>,>3>,>2>)> plt.imshow(> ># Reformat for plotting> >tf.squeeze(image_detect)> )> > plt.axis(>'off'>)> plt.title(>'Activation'>)> > # Pooling layer> pool>=> tf.nn.pool> image_condense>=> pool(>input>=>image_detect,> >window_shape>=>(>2>,>2>),> >pooling_type>=>'MAX'>,> >strides>=>(>2>,>2>),> >padding>=>'SAME'>,> >)> > plt.subplot(>1>,>3>,>3>)> plt.imshow(tf.squeeze(image_condense))> plt.axis(>'off'>)> plt.title(>'Pooling'>)> plt.show()> |
ile zer jest w 1 miliardzie
>
>
Wyjście :

Oryginalny obraz w skali szarości
Wyjście
Zalety konwolucyjnych sieci neuronowych (CNN):
- Dobrze wykrywa wzorce i cechy w obrazach, filmach i sygnałach audio.
- Odporny na translację, rotację i niezmienność skalowania.
- Kompleksowe szkolenie, bez konieczności ręcznego wyodrębniania funkcji.
- Potrafi przetwarzać duże ilości danych i osiągać wysoką dokładność.
Wady konwolucyjnych sieci neuronowych (CNN):
- Szkolenie jest kosztowne obliczeniowo i wymaga dużej ilości pamięci.
- Może być podatny na nadmierne dopasowanie, jeśli nie zostanie użyta wystarczająca ilość danych lub odpowiednia regularyzacja.
- Wymaga dużej ilości oznaczonych danych.
- Interpretowalność jest ograniczona, trudno zrozumieć, czego nauczyła się sieć.
Często zadawane pytania (FAQ)
1: Co to jest konwolucyjna sieć neuronowa (CNN)?
Konwolucyjna sieć neuronowa (CNN) to rodzaj sieci neuronowej głębokiego uczenia się, która dobrze nadaje się do analizy obrazów i wideo. Sieci CNN wykorzystują szereg warstw splotu i łączenia w celu wyodrębnienia cech z obrazów i filmów, a następnie wykorzystują te funkcje do klasyfikowania lub wykrywania obiektów lub scen.
zastosowań systemu operacyjnego
2: Jak działają CNN?
Sieci CNN działają poprzez zastosowanie serii warstw splotu i łączenia do obrazu wejściowego lub wideo. Warstwy splotu wyodrębniają cechy z danych wejściowych, przesuwając mały filtr, czyli jądro, na obraz lub wideo i obliczając iloczyn skalarny między filtrem a danymi wejściowymi. Następnie warstwy pulujące zmniejszają próbkowanie danych wyjściowych warstw splotu, aby zmniejszyć wymiarowość danych i zwiększyć ich wydajność obliczeniową.
3: Jakie są typowe funkcje aktywacji stosowane w CNN?
Niektóre typowe funkcje aktywacji stosowane w CNN obejmują:
- Prostowana jednostka liniowa (ReLU): ReLU to nienasycająca funkcja aktywacji, która jest wydajna obliczeniowo i łatwa do wytrenowania.
- Leaky Rectified Linear Unit (Leaky ReLU): Leaky ReLU to wariant ReLU, który umożliwia przepływ niewielkiej ilości ujemnego gradientu przez sieć. Może to pomóc w zapobieganiu śmierci sieci podczas uczenia.
- Parametryczna wyprostowana jednostka liniowa (PReLU): PReLU jest uogólnieniem Leaky ReLU, które umożliwia poznanie nachylenia ujemnego gradientu.
4: Jaki jest cel stosowania wielu warstw splotu w CNN?
Korzystanie z wielu warstw splotu w CNN umożliwia sieci uczenie się coraz bardziej złożonych funkcji na podstawie wejściowego obrazu lub wideo. Pierwsze warstwy splotu uczą się prostych cech, takich jak krawędzie i narożniki. Głębsze warstwy splotu uczą się bardziej złożonych cech, takich jak kształty i obiekty.
5: Jakie są popularne techniki regularyzacji stosowane w CNN?
Aby zapobiec nadmiernemu dopasowaniu danych szkoleniowych przez CNN, stosuje się techniki regularyzacji. Niektóre typowe techniki regularyzacji stosowane w CNN obejmują:
- Porzucenie: Porzucenie losowo usuwa neurony z sieci podczas treningu. Zmusza to sieć do uczenia się bardziej niezawodnych funkcji, które nie są zależne od żadnego pojedynczego neuronu.
- Regularyzacja L1: Regularyzacja L1 reguluje bezwzględna wartość wag w sieci. Może to pomóc w zmniejszeniu liczby obciążników i zwiększeniu wydajności sieci.
- Regularyzacja L2: Regularyzacja L2 reguluje kwadrat wag w sieci. Może to również pomóc w zmniejszeniu liczby obciążników i zwiększeniu wydajności sieci.
6: Jaka jest różnica między warstwą splotu a warstwą łączenia?
Warstwa splotu wyodrębnia funkcje z obrazu wejściowego lub wideo, podczas gdy warstwa łączenia zmniejsza próbkowanie danych wyjściowych warstw splotu. Warstwy splotu korzystają z szeregu filtrów w celu wyodrębnienia cech, podczas gdy warstwy łączenia wykorzystują różne techniki próbkowania danych w dół, takie jak łączenie maksymalne i łączenie średnie.