- normalna()
dnorm(x, mean, sd)>pnorm()
pnorm(x, mean, sd)>qnorma()
qnorm(p, mean, sd)>rnorm()
rnorm(n, mean, sd)>Gdzie,
– X reprezentuje zbiór danych wartości – znaczy (x) reprezentuje średnią zbioru danych X . Domyślna wartość to 0.>– SD(x) reprezentuje odchylenie standardowe zbioru danych X . Domyślna wartość to 1.>– N to liczba obserwacji. – P jest wektorem prawdopodobieństw
Funkcje generujące rozkład normalny w R
normalna()
dnorm()> funkcja w programowaniu w języku R mierzy funkcję gęstości rozkładu. W statystykach mierzy się to poniższym wzorem:>Gdzie,
 jest podły i
jest podły i 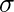 jest odchyleniem standardowym. Składnia:
jest odchyleniem standardowym. Składnia: dnorm(x, mean, sd)>Przykład:
# creating a sequence of values> # between -15 to 15 with a difference of 0.1> x>=> seq(>->15>,>15>, by>=>0.1>)> > y>=> dnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file>=>'dnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>Wyjście:
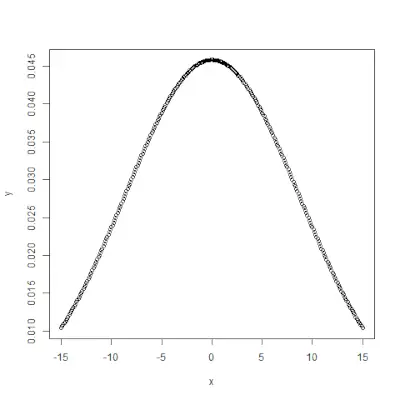
pnorm()
pnorm()> funkcja jest dystrybuantą skumulowaną, która mierzy prawdopodobieństwo, że liczba losowa X przyjmie wartość mniejszą lub równą x, tj. w statystyce jest ona wyrażana przez->Składnia:
pnorm(x, mean, sd)>Przykład:
# creating a sequence of values> # between -10 to 10 with a difference of 0.1> x <>-> seq(>->10>,>10>, by>=>0.1>)> > y <>-> pnorm(x, mean>=> 2.5>, sd>=> 2>)> > # output to be present as PNG file> png(>file>=>'pnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>Wyjście :
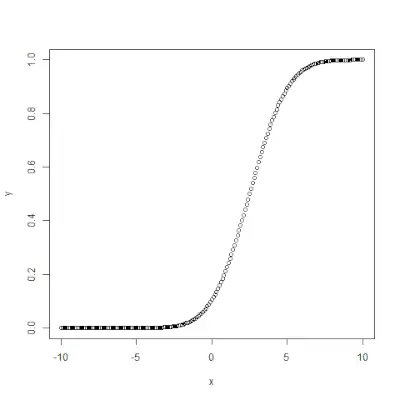
qnorma()
qnorm()> funkcja jest odwrotnością pnorm()>funkcjonować. Przyjmuje wartość prawdopodobieństwa i daje wynik odpowiadający wartości prawdopodobieństwa. Jest to przydatne przy znajdowaniu percentyli rozkładu normalnego. Składnia: qnorm(p, mean, sd)>Przykład:
# Create a sequence of probability values> # incrementing by 0.02.> x <>-> seq(>0>,>1>, by>=> 0.02>)> > y <>-> qnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file> => 'qnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # Save the file.> dev.off()> |
>
>Wyjście:
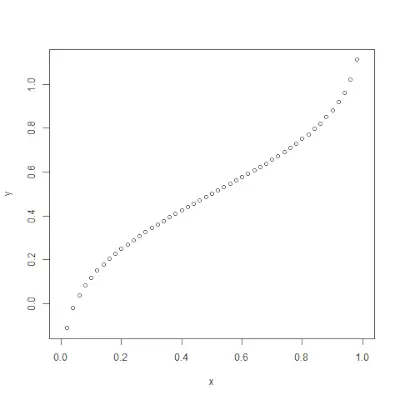
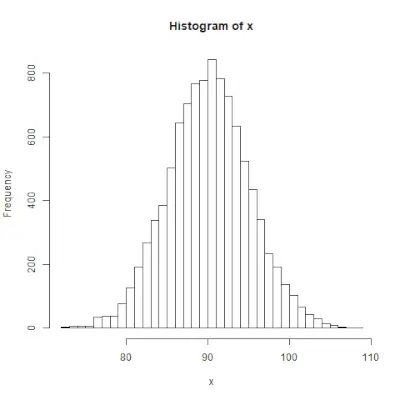
rnorm()
rnorm()> funkcja w programowaniu w R służy do generowania wektora liczb losowych o rozkładzie normalnym. Składnia: rnorm(x, mean, sd)>Przykład:
# Create a vector of 1000 random numbers> # with mean=90 and sd=5> x <>-> rnorm(>10000>, mean>=>90>, sd>=>5>)> > # output to be present as PNG file> png(>file> => 'rnormExample.webp'>)> > # Create the histogram with 50 bars> hist(x, breaks>=>50>)> > # Save the file.> dev.off()> |
>
>Wyjście :