Algorytmy regresji i klasyfikacji to algorytmy uczenia się nadzorowanego. Obydwa algorytmy służą do przewidywania w uczeniu maszynowym i współpracują z oznaczonymi zbiorami danych. Różnica między obydwoma polega na tym, jak są one wykorzystywane do różnych problemów związanych z uczeniem maszynowym.
Główna różnica między algorytmami regresji i klasyfikacji, do której wykorzystywane są algorytmy regresji przewidzieć ciągłość wartości takie jak cena, wynagrodzenie, wiek itp. oraz algorytmy klasyfikacji przewidzieć/klasyfikować wartości dyskretne takie jak mężczyzna czy kobieta, prawda czy fałsz, spam czy nie spam itp.
Rozważ poniższy diagram:
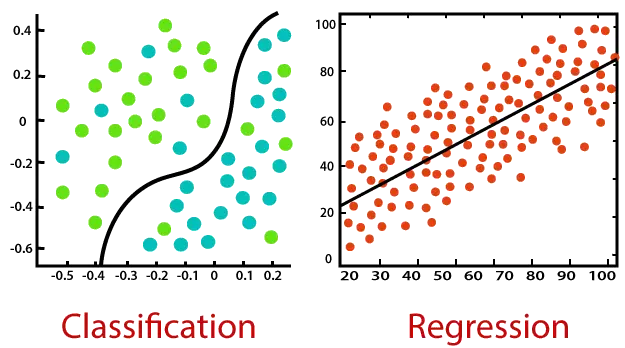
Klasyfikacja:
Klasyfikacja to proces znajdowania funkcji, która pomaga w podzieleniu zbioru danych na klasy w oparciu o różne parametry. W klasyfikacji program komputerowy jest szkolony na zbiorze danych szkoleniowych i na podstawie tego szkolenia kategoryzuje dane na różne klasy.
Zadaniem algorytmu klasyfikacji jest znalezienie funkcji mapującej, która mapuje wejście (x) na dyskretne wyjście (y).
Przykład: Najlepszym przykładem zrozumienia problemu klasyfikacji jest wykrywanie spamu w wiadomościach e-mail. Model jest szkolony na podstawie milionów e-maili pod kątem różnych parametrów i za każdym razem, gdy otrzymuje nowy e-mail, identyfikuje, czy jest on spamem, czy nie. Jeśli wiadomość e-mail jest spamem, jest przenoszona do folderu Spam.
Rodzaje algorytmów klasyfikacji ML:
Algorytmy klasyfikacyjne można dalej podzielić na następujące typy:
- Regresja logistyczna
- K-Najbliżsi sąsiedzi
- Wsparcie maszyn wektorowych
- Jądro SVM
- Naiwny Bayes
- Klasyfikacja drzewa decyzyjnego
- Klasyfikacja losowego lasu
Regresja:
Regresja to proces znajdowania korelacji między zmiennymi zależnymi i niezależnymi. Pomaga w przewidywaniu zmiennych ciągłych, takich jak przewidywanie Trendy marketowe , przewidywanie cen domów itp.
Zadaniem algorytmu regresji jest znalezienie funkcji mapującej, która mapuje zmienną wejściową (x) na ciągłą zmienną wyjściową (y).
Przykład: Załóżmy, że chcemy prognozować pogodę, więc w tym celu użyjemy algorytmu regresji. W przypadku przewidywania pogody model jest szkolony na danych z przeszłości, a po zakończeniu uczenia może z łatwością przewidzieć pogodę na przyszłe dni.
Rodzaje algorytmów regresji:
- Prosta regresja liniowa
- Wielokrotna regresja liniowa
- Regresja wielomianowa
- Regresja wektora pomocniczego
- Regresja drzewa decyzyjnego
- Losowa regresja lasu
Różnica między regresją a klasyfikacją
| Algorytm regresji | Algorytm klasyfikacji |
|---|---|
| W regresji zmienna wyjściowa musi mieć charakter ciągły lub wartość rzeczywistą. | W klasyfikacji zmienna wyjściowa musi być wartością dyskretną. |
| Zadaniem algorytmu regresji jest odwzorowanie wartości wejściowej (x) na ciągłą zmienną wyjściową (y). | Zadaniem algorytmu klasyfikacji jest odwzorowanie wartości wejściowej (x) na dyskretną zmienną wyjściową (y). |
| Algorytmy regresji są stosowane w przypadku danych ciągłych. | Algorytmy klasyfikacji są używane z danymi dyskretnymi. |
| W regresji staramy się znaleźć najlepszą linię dopasowania, która pozwala dokładniej przewidzieć wynik. | W Klasyfikacji staramy się znaleźć granicę decyzyjną, która może podzielić zbiór danych na różne klasy. |
| Algorytmy regresji można wykorzystać do rozwiązywania problemów regresyjnych, takich jak prognozowanie pogody, przewidywanie cen domów itp. | Algorytmy klasyfikacji można wykorzystać do rozwiązywania problemów z klasyfikacją, takich jak identyfikacja wiadomości spamowych, rozpoznawanie mowy, identyfikacja komórek nowotworowych itp. |
| Algorytm regresji można dalej podzielić na regresję liniową i nieliniową. | Algorytmy klasyfikacji można podzielić na klasyfikator binarny i klasyfikator wieloklasowy. |