A Menedżer pobierania to w zasadzie program komputerowy przeznaczony do pobierania samodzielnych plików z Internetu. Tutaj stworzymy prosty Menedżer pobierania za pomocą wątków w Pythonie. Korzystając z wielowątkowości, plik można pobrać w postaci fragmentów jednocześnie z różnych wątków. Aby to zaimplementować, stworzymy proste narzędzie wiersza poleceń, które akceptuje adres URL pliku, a następnie go pobiera.
Wymagania wstępne: Komputer z systemem Windows i zainstalowanym językiem Python.
Organizować coś
Pobierz poniższe pakiety z wiersza poleceń.
podwójnie połączona lista
1. Pakiet Click: Click to pakiet Pythona umożliwiający tworzenie pięknych interfejsów wiersza poleceń z minimalną ilością kodu. To zestaw do tworzenia interfejsu wiersza poleceń.
kliknij instalację pip
2. Pakiet żądań: W tym narzędziu pobierzemy plik na podstawie adresu URL (adresów HTTP). Requests to biblioteka HTTP napisana w Pythonie, która umożliwia wysyłanie żądań HTTP. Możesz dodawać nagłówki z wieloczęściowych plików danych i parametrów za pomocą prostych słowników Pythona i uzyskiwać dostęp do danych odpowiedzi w ten sam sposób.
żądania instalacji pip
3. Pakiet Threading: Do pracy z wątkami potrzebujemy pakietu Threading.
pip zainstaluj wątek
Realizacja
Notatka:
Aby ułatwić zrozumienie, program został podzielony na części. Upewnij się, że podczas uruchamiania programu nie brakuje Ci żadnej części kodu.
Krok 1: Zaimportuj wymagane pakiety
Pakiety te zapewniają narzędzia niezbędne do obsługi żądań sieciowych danych wejściowych z wiersza poleceń i tworzenia wątków.
Pythonimport click import requests import threading
Krok 2: Utwórz funkcję obsługi
Każdy wątek wykona tę funkcję, aby pobrać określoną część pliku. Funkcja ta odpowiada za żądanie tylko określonego zakresu bajtów i zapisanie ich we właściwym miejscu w pliku.
arraylist posortowane JavaPython
def Handler(start end url filename): headers = {'Range': f'bytes={start}-{end}'} r = requests.get(url headers=headers stream=True) with open(filename 'r+b') as fp: fp.seek(start) fp.write(r.content)
Krok 3: Zdefiniuj główną funkcję za pomocą kliknięcia
Zamienia funkcję w narzędzie wiersza poleceń. Określa sposób interakcji użytkowników ze skryptem z wiersza poleceń.
Python#Note: This code will not work on online IDE @click.command(help='Downloads the specified file with given name using multi-threading') @click.option('--number_of_threads' default=4 help='Number of threads to use') @click.option('--name' type=click.Path() help='Name to save the file as (with extension)') @click.argument('url_of_file' type=str) def download_file(url_of_file name number_of_threads):
Krok 4: Ustaw nazwę pliku i określ rozmiar pliku
Potrzebujemy rozmiaru pliku, aby podzielić pobieranie między wątki i upewnić się, że serwer obsługuje pobieranie na odległość.
Python r = requests.head(url_of_file) file_name = name if name else url_of_file.split('/')[-1] try: file_size = int(r.headers['Content-Length']) except: print('Invalid URL or missing Content-Length header.') return
Krok 5: Wstępnie przydziel miejsce na pliki
Wstępne przydzielanie zapewnia, że plik ma prawidłowy rozmiar, zanim zapiszemy fragmenty w określonych zakresach bajtów.
Python part = file_size // number_of_threads with open(file_name 'wb') as fp: fp.write(b'�' * file_size)
Krok 6: Utwórz wątki
Wątkom przypisuje się określone zakresy bajtów do równoległego pobierania.
Python threads = [] for i in range(number_of_threads): start = part * i end = file_size - 1 if i == number_of_threads - 1 else (start + part - 1) t = threading.Thread(target=Handler kwargs={ 'start': start 'end': end 'url': url_of_file 'filename': file_name }) threads.append(t) t.start()
Krok 7: Dołącz do wątków
Zapewnia zakończenie wszystkich wątków przed zakończeniem programu.
Python for t in threads: t.join() print(f'{file_name} downloaded successfully!') if __name__ == '__main__': download_file()
Kod:
Pythonimport click import requests import threading def Handler(start end url filename): headers = {'Range': f'bytes={start}-{end}'} r = requests.get(url headers=headers stream=True) with open(filename 'r+b') as fp: fp.seek(start) fp.write(r.content) @click.command(help='Downloads the specified file with given name using multi-threading') @click.option('--number_of_threads' default=4 help='Number of threads to use') @click.option('--name' type=click.Path() help='Name to save the file as (with extension)') @click.argument('url_of_file' type=str) def download_file(url_of_file name number_of_threads): r = requests.head(url_of_file) if name: file_name = name else: file_name = url_of_file.split('/')[-1] try: file_size = int(r.headers['Content-Length']) except: print('Invalid URL or missing Content-Length header.') return part = file_size // number_of_threads with open(file_name 'wb') as fp: fp.write(b'�' * file_size) threads = [] for i in range(number_of_threads): start = part * i # Make sure the last part downloads till the end of file end = file_size - 1 if i == number_of_threads - 1 else (start + part - 1) t = threading.Thread(target=Handler kwargs={ 'start': start 'end': end 'url': url_of_file 'filename': file_name }) threads.append(t) t.start() for t in threads: t.join() print(f'{file_name} downloaded successfully!') if __name__ == '__main__': download_file()
Skończyliśmy część kodowania i teraz postępuj zgodnie z poleceniami pokazanymi poniżej, aby uruchomić plik .py.
operator reszty Pythona
python filename.py –-helpWyjście:
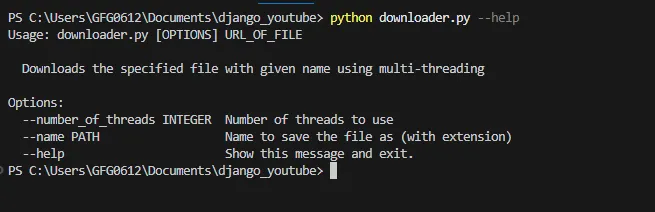 python nazwapliku.py –-help
python nazwapliku.py –-help
To polecenie pokazuje użycie narzędzia polecenia kliknięcia i opcje, które narzędzie może zaakceptować. Poniżej znajduje się przykładowe polecenie, w którym próbujemy pobrać plik obrazu jpg z adresu URL, podając także nazwę i liczbę_wątków.
 przykładowe polecenie pobierania pliku jpg
przykładowe polecenie pobierania pliku jpgPo pomyślnym uruchomieniu wszystkiego będziesz mógł zobaczyć swój plik (w tym przypadku flower.webp) w katalogu folderów, jak pokazano poniżej:
 informator
informatorWreszcie udało nam się z tym skończyć i jest to jeden ze sposobów zbudowania prostego, wielowątkowego menedżera pobierania w Pythonie.