Kolejka priorytetowa to abstrakcyjny typ danych, który zachowuje się podobnie do normalnej kolejki, z tą różnicą, że każdy element ma pewien priorytet, tj. element o najwyższym priorytecie zajmie pierwsze miejsce w kolejce priorytetowej. Priorytet elementów w kolejce priorytetowej określi kolejność usuwania elementów z kolejki priorytetowej.
Kolejka priorytetowa obsługuje tylko porównywalne elementy, co oznacza, że elementy są ułożone w kolejności rosnącej lub malejącej.
rozmiary czcionek w lateksie
Załóżmy na przykład, że mamy pewne wartości, takie jak 1, 3, 4, 8, 14, 22, umieszczone w kolejce priorytetowej z narzuconą kolejnością wartości od najmniejszej do największej. Dlatego liczba 1 będzie miała najwyższy priorytet, a liczba 22 będzie miała najniższy priorytet.
Charakterystyka kolejki priorytetowej
Kolejka priorytetowa jest rozszerzeniem kolejki, które ma następujące cechy:
- Z każdym elementem kolejki priorytetowej jest powiązany jakiś priorytet.
- Element o wyższym priorytecie zostanie usunięty przed usunięciem niższego priorytetu.
- Jeżeli dwa elementy w kolejce priorytetowej mają ten sam priorytet, zostaną one uporządkowane zgodnie z zasadą FIFO.
Przyjrzyjmy się kolejce priorytetowej na przykładzie.
Mamy kolejkę priorytetową zawierającą następujące wartości:
1, 3, 4, 8, 14, 22
Wszystkie wartości są ułożone w kolejności rosnącej. Teraz będziemy obserwować jak będzie wyglądać kolejka priorytetowa po wykonaniu następujących operacji:
Rodzaje kolejek priorytetowych
Istnieją dwa typy kolejek priorytetowych:
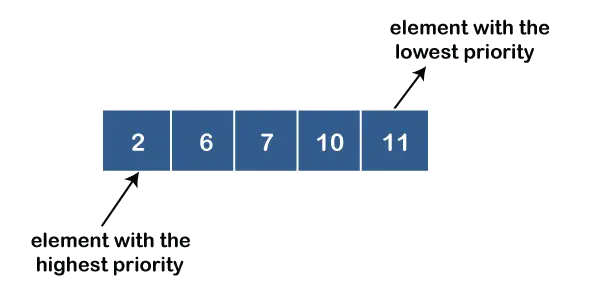

Reprezentacja kolejki priorytetowej
Teraz zobaczymy, jak przedstawić kolejkę priorytetową za pomocą listy jednokierunkowej.
Kolejkę priorytetową utworzymy korzystając z poniższej listy, w której INFORMACJE lista zawiera elementy danych, PRN lista zawiera numery priorytetów każdego elementu danych dostępnych w pliku INFORMACJE list, a LINK zasadniczo zawiera adres następnego węzła.

Stwórzmy krok po kroku kolejkę priorytetową.
czyszczenie pamięci podręcznej npm
W przypadku kolejki priorytetowej za wyższy priorytet uważa się numer o niższym priorytecie, tj. niższy numer priorytetu = wyższy priorytet.
Krok 1: Na liście niższy numer priorytetu to 1, którego wartość danych wynosi 333, zatem zostanie on wstawiony na listę jak pokazano na poniższym schemacie:
Krok 2: Po wstawieniu 333 wyższy priorytet ma priorytet numer 2, a wartości danych skojarzonych z tym priorytetem to 222 i 111. Zatem dane te zostaną wstawione w oparciu o zasadę FIFO; dlatego najpierw zostanie dodane 222, a następnie 111.
Krok 3: Po wstawieniu elementów o priorytecie 2 kolejnym wyższym numerem priorytetu jest 4, a elementy danych powiązane z 4 numerami priorytetu to 444, 555, 777. W tym przypadku elementy zostaną wstawione w oparciu o zasadę FIFO; dlatego najpierw zostanie dodane 444, następnie 555, a następnie 777.
Krok 4: Po wstawieniu elementów o priorytecie 4 kolejnym wyższym numerem priorytetu jest 5, a wartość związana z priorytetem 5 to 666, zatem zostanie wstawiona na końcu kolejki.

Implementacja kolejki priorytetowej
Kolejkę priorytetową można zaimplementować na cztery sposoby, które obejmują tablice, listę połączoną, strukturę danych sterty i drzewo wyszukiwania binarnego. Struktura danych sterty jest najskuteczniejszym sposobem implementacji kolejki priorytetowej, dlatego w tym temacie zaimplementujemy kolejkę priorytetową przy użyciu struktury danych sterty. Teraz najpierw rozumiemy powód, dla którego sterta jest najbardziej efektywną metodą spośród wszystkich innych struktur danych.
Analiza złożoności przy użyciu różnych implementacji
| Realizacja | dodać | Usunąć | zerkać |
| Połączona lista | O(1) | NA) | NA) |
| Kopia binarna | O(zaloguj się) | O(zaloguj się) | O(1) |
| Drzewo wyszukiwania binarnego | O(zaloguj się) | O(zaloguj się) | O(1) |
Co to jest sterta?
Sterta to oparta na drzewie struktura danych, która tworzy kompletne drzewo binarne i spełnia właściwość sterty. Jeśli A jest węzłem nadrzędnym B, wówczas A jest uporządkowane względem węzła B dla wszystkich węzłów A i B na stercie. Oznacza to, że wartość węzła nadrzędnego może być większa lub równa wartości węzła podrzędnego lub wartość węzła nadrzędnego może być mniejsza lub równa wartości węzła podrzędnego. Dlatego możemy powiedzieć, że istnieją dwa rodzaje kopców:


Obie sterty są stertami binarnymi, ponieważ każda ma dokładnie dwa węzły podrzędne.
Operacje w kolejce priorytetowej
Typowe operacje, które możemy wykonać na kolejce priorytetowej, to wstawianie, usuwanie i podglądanie. Zobaczmy, jak możemy zachować strukturę danych sterty.
Jeśli wstawimy element do kolejki priorytetowej, przesunie się on do pustego miejsca, patrząc od góry do dołu i od lewej do prawej.
Jeśli element nie znajduje się we właściwym miejscu, jest porównywany z węzłem nadrzędnym; jeśli okaże się, że jest niewłaściwa, elementy są zamieniane. Proces ten trwa do momentu umieszczenia elementu we właściwej pozycji.


Jak wiemy, w maksymalnej stercie maksymalnym elementem jest węzeł główny. Kiedy usuniemy węzeł główny, utworzy się puste miejsce. Ostatni wstawiony element zostanie dodany w tym pustym slocie. Następnie element ten jest porównywany z węzłami potomnymi, tj. lewym i prawym dzieckiem, i zamieniany z mniejszym z nich. Porusza się w dół drzewa, aż do przywrócenia właściwości sterty.
Zastosowania kolejki priorytetowej
Poniżej przedstawiono zastosowania kolejki priorytetowej:
Java równa się
- Jest używany w algorytmie najkrótszej ścieżki Dijkstry.
- Jest używany w algorytmie prima
- Jest stosowany w technikach kompresji danych, takich jak kod Huffmana.
- Jest używany w sortowaniu sterty.
- Jest również używany w systemie operacyjnym, np. przy planowaniu priorytetów, równoważeniu obciążenia i obsłudze przerwań.
Program tworzący kolejkę priorytetową przy użyciu maksymalnej sterty binarnej.
#include #include int heap[40]; int size=-1; // retrieving the parent node of the child node int parent(int i) { return (i - 1) / 2; } // retrieving the left child of the parent node. int left_child(int i) { return i+1; } // retrieving the right child of the parent int right_child(int i) { return i+2; } // Returning the element having the highest priority int get_Max() { return heap[0]; } //Returning the element having the minimum priority int get_Min() { return heap[size]; } // function to move the node up the tree in order to restore the heap property. void moveUp(int i) { while (i > 0) { // swapping parent node with a child node if(heap[parent(i)] <heap[i]) 2 { int temp; temp="heap[parent(i)];" heap[parent(i)]="heap[i];" heap[i]="temp;" } updating the value of i to function move node down tree in order restore heap property. void movedown(int k) index="k;" getting location left child if (left heap[index]) right (right k is not equal (k !="index)" heap[index]="heap[k];" heap[k]="temp;" movedown(index); removing element maximum priority removemax() r="heap[0];" heap[0]="heap[size];" size="size-1;" movedown(0); inserting a queue insert(int p) + 1; heap[size]="p;" up maintain property moveup(size); from at given i. delete(int i) stored ith shifted root moveup(i); having removemax(); main() elements insert(20); insert(19); insert(21); insert(18); insert(12); insert(17); insert(15); insert(16); insert(14); printf('elements are : '); for(int printf('%d ',heap[i]); delete(2); deleting whose 2. printf('
elements after max="get_Max();" printf('
the which highest %d: ',max); min="get_Min();" minimum %d',min); return 0; < pre> <p> <strong>In the above program, we have created the following functions:</strong> </p> <ul> <tr><td>int parent(int i):</td> This function returns the index of the parent node of a child node, i.e., i. </tr><tr><td>int left_child(int i):</td> This function returns the index of the left child of a given index, i.e., i. </tr><tr><td>int right_child(int i):</td> This function returns the index of the right child of a given index, i.e., i. </tr><tr><td>void moveUp(int i):</td> This function will keep moving the node up the tree until the heap property is restored. </tr><tr><td>void moveDown(int i):</td> This function will keep moving the node down the tree until the heap property is restored. </tr><tr><td>void removeMax():</td> This function removes the element which is having the highest priority. </tr><tr><td>void insert(int p):</td> It inserts the element in a priority queue which is passed as an argument in a function <strong>.</strong> </tr><tr><td>void delete(int i):</td> It deletes the element from a priority queue at a given index. </tr><tr><td>int get_Max():</td> It returns the element which is having the highest priority, and we know that in max heap, the root node contains the element which has the largest value, and highest priority. </tr><tr><td>int get_Min():</td> It returns the element which is having the minimum priority, and we know that in max heap, the last node contains the element which has the smallest value, and lowest priority. </tr></ul> <p> <strong>Output</strong> </p> <img src="//techcodeview.com/img/ds-tutorial/03/what-is-priority-queue-9.webp" alt="Priority Queue"> <hr></heap[i])>