- Redshift to szybka i wydajna, w pełni zarządzana usługa hurtowni danych w chmurze o skali petabajtów.
- Klienci mogą korzystać z Redshift za jedyne 0,25 dolara za godzinę, bez zobowiązań i kosztów początkowych, a także skalować do petabajta lub więcej za 1000 dolarów za terabajt rocznie.
OLAP
OLAP jest System przetwarzania danych analitycznych online używany przez Przesunięcie ku czerwieni .
Przykład transakcji OLAP:
Załóżmy, że chcemy obliczyć zysk netto dla produktu radia cyfrowego dla regionu EMEA i Pacyfiku. Wymaga to pobrania dużej liczby rekordów. Poniżej znajdują się zapisy wymagane do obliczenia zysku netto:
- Suma radiotelefonów sprzedanych w regionie EMEA.
- Suma radiotelefonów sprzedanych na Pacyfiku.
- Koszt jednostkowy radia w każdym regionie.
- Cena sprzedaży każdego radia
- Cena sprzedaży – koszt jednostkowy
Aby pobrać rekordy podane powyżej, wymagane są złożone zapytania. Bazy danych hurtowni danych wykorzystują inną architekturę typów zarówno z perspektywy bazy danych, jak i warstwy infrastruktury.
Konfiguracja przesunięcia ku czerwieni
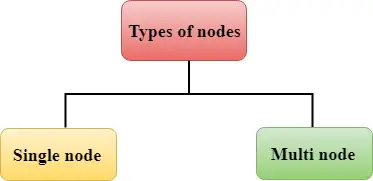
Redshift składa się z dwóch typów węzłów:
Pojedynczy węzeł: Pojedynczy węzeł przechowuje do 160 GB.
Wielowęzłowe: Wielowęzeł to węzeł składający się z więcej niż jednego węzła. Jest dwojakiego rodzaju:
Zarządza połączeniami klientów i odbiera zapytania. Węzeł wiodący odbiera zapytania od aplikacji klienckich, analizuje je i opracowuje plany wykonania. Koordynuje równoległą realizację tych planów z węzłem obliczeniowym i łączy wyniki pośrednie wszystkich węzłów, a następnie zwraca wynik końcowy do aplikacji klienckiej.
Węzeł obliczeniowy wykonuje plany wykonania, a następnie wyniki pośrednie są wysyłane do węzła lidera w celu agregacji przed wysłaniem z powrotem do aplikacji klienckiej. Może mieć do 128 węzłów obliczeniowych.
Przyjrzyjmy się koncepcji węzła lidera i węzłów obliczeniowych na przykładzie.
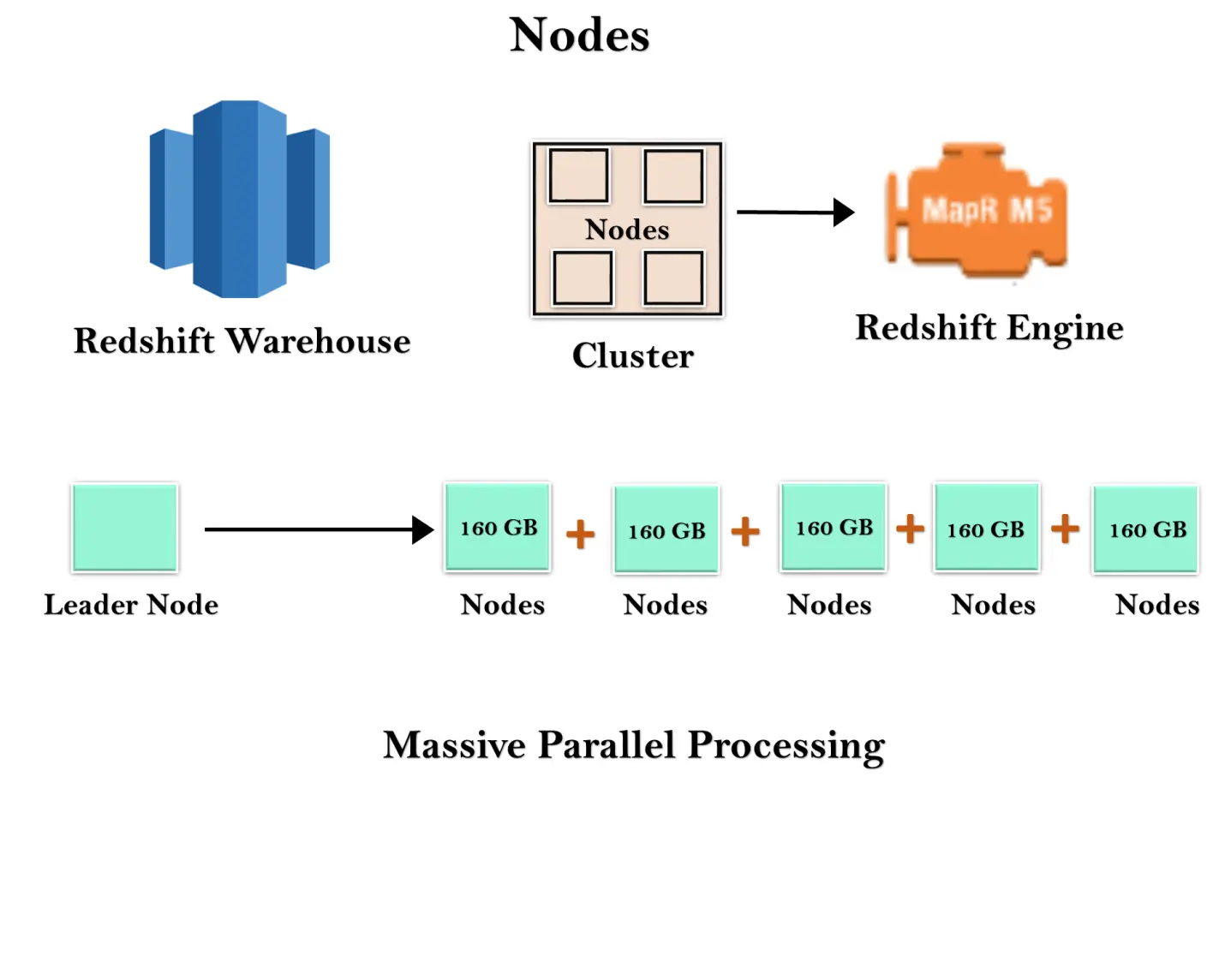
Magazyn przesunięcia ku czerwieni to zbiór zasobów obliczeniowych zwanych węzłami, które są zorganizowane w grupę zwaną klastrem. Każdy klaster działa w silniku Redshift Engine, który zawiera jedną lub więcej baz danych.
Kiedy uruchamiasz instancję Redshift, zaczyna się ona od pojedynczego węzła o rozmiarze 160 GB. Jeśli chcesz się rozwijać, możesz dodać dodatkowe węzły, aby skorzystać z przetwarzania równoległego. Masz węzeł wiodący, który zarządza wieloma węzłami. Węzeł wiodący obsługuje połączenie klienta oraz węzły obliczeniowe. Przechowuje dane w węzłach obliczeniowych i wykonuje zapytanie.
Dlaczego Redshift jest 10 razy szybszy
Redshift jest 10 razy szybszy z następujących powodów:
Zamiast przechowywać dane w postaci serii wierszy, Amazon Redshift organizuje dane według kolumn. Systemy oparte na wierszach idealnie nadają się do przetwarzania transakcji, natomiast systemy oparte na kolumnach idealnie nadają się do przechowywania danych i analiz, gdzie zapytania często obejmują agregacje wykonywane na dużych zbiorach danych. Ponieważ przetwarzane są tylko kolumny objęte zapytaniami, a dane kolumnowe są przechowywane na nośniku pamięci sekwencyjnie, systemy oparte na kolumnach wymagają mniejszej liczby operacji we/wy, co poprawia wydajność zapytań.
Kolumnowe magazyny danych można skompresować znacznie bardziej niż magazyny danych oparte na wierszach, ponieważ podobne dane są przechowywane sekwencyjnie na dysku. Amazon Redshift wykorzystuje wiele technik kompresji i często może osiągnąć znaczną kompresję w porównaniu z tradycyjnymi magazynami danych relacyjnych.
Amazon Redshift nie wymaga indeksów ani widoków zmaterializowanych, dlatego wymaga mniej miejsca niż tradycyjne systemy relacyjnych baz danych. Podczas ładowania danych do pustej tabeli Amazon Redshift automatycznie próbkuje dane i wybiera najbardziej odpowiednią technikę kompresji.
Amazon Redshift automatycznie dystrybuuje dane i ładuje zapytanie do różnych węzłów. Amazon Redshift ułatwia dodawanie nowych węzłów do hurtowni danych, co pozwala nam osiągnąć większą wydajność zapytań w miarę rozwoju hurtowni danych.
Funkcje przesunięcia ku czerwieni
Funkcje Redshift podano poniżej:
pełna forma i d e
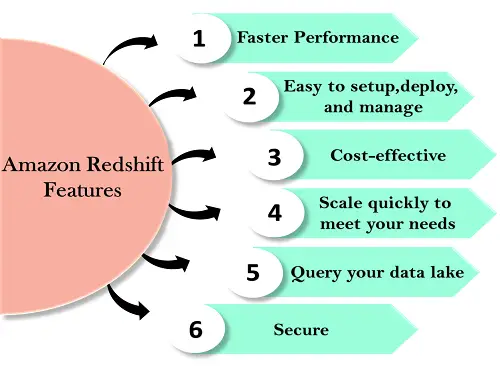
Redshift jest prosty w konfiguracji i obsłudze. Możesz wdrożyć nową hurtownię danych za pomocą zaledwie kilku kliknięć w konsoli AWS, a Redshift automatycznie zapewni Ci infrastrukturę. W AWS wszystkie zadania administracyjne są zautomatyzowane, takie jak kopie zapasowe i replikacja, musisz skupić się na swoich danych, a nie na administracji.
Redshift automatycznie tworzy kopię zapasową danych w S3. Można także replikować migawki w S3 w innym regionie na potrzeby odzyskiwania po awarii.
Amazon Redshift to najbardziej opłacalna usługa hurtowni danych, ponieważ płacisz tylko za to, z czego korzystasz.
Jego koszty zaczynają się od 0,25 USD za godzinę bez zobowiązań i kosztów początkowych i można je skalować do 250 USD za terabajt rocznie.
Amazon Redshift to jedyna usługa hurtowni danych oferująca ceny na żądanie bez kosztów początkowych, a także ceny instancji zarezerwowanych, które pozwalają zaoszczędzić do 75% przy okresie 1–3 lat.
Możesz wybrać jeden z dwóch węzłów, aby zoptymalizować przesunięcie ku czerwieni.
Gęsty węzeł obliczeniowy może tworzyć hurtownie danych o wysokiej wydajności, wykorzystując szybkie procesory, dużą ilość pamięci RAM i dyski półprzewodnikowe.
Jeśli chcesz obniżyć koszty, możesz skorzystać z węzła Gęste magazynowanie. Tworzy opłacalną hurtownię danych przy użyciu większego dysku twardego.
Amazon Redshift automatycznie skaluje w górę lub w dół węzły w zależności od potrzeb. Za pomocą kilku kliknięć w konsoli AWS lub pojedynczego wywołania API można łatwo zmienić liczbę węzłów w hurtowni danych.
Jest to funkcja Redshift, która umożliwia uruchamianie zapytań względem eksabajtów danych w Amazon S3. Amazon S3 to bezpieczne i ekonomiczne rozwiązanie do przechowywania nieograniczonej ilości danych w otwartym formacie.
Jest to funkcja Redshift, która oznacza, że wiele zapytań może uzyskać dostęp do tych samych danych w Amazon S3. Umożliwia uruchamianie zapytań w wielu węzłach niezależnie od złożoności zapytania lub ilości danych.
Amazon Redshift to jedyna hurtownia danych, która służy do wysyłania zapytań do jeziora danych Amazon S3 bez ładowania danych. Zapewnia to elastyczność poprzez przechowywanie często używanych danych w Redshift oraz nieustrukturyzowanych lub rzadko używanych danych w Amazon S3.
Za pomocą kilku ustawień parametrów możesz ustawić Redshift tak, aby używał protokołu SSL do zabezpieczania danych. Możesz także włączyć szyfrowanie, wszystkie dane zapisane na dysku zostaną zaszyfrowane.
Amazon Redshift zapewnia kolumnowe przechowywanie danych, kompresję i przetwarzanie równoległe, aby zmniejszyć ilość operacji we/wy potrzebnych do wykonywania zapytań. Poprawia to wydajność zapytań.