Testowanie regresyjne to technika testowania czarnej skrzynki. Służy do uwierzytelnienia. Zmiana kodu w oprogramowaniu nie ma wpływu na istniejącą funkcjonalność produktu. Testowanie regresyjne pozwala upewnić się, że produkt działa poprawnie z nową funkcjonalnością, poprawkami błędów lub wszelkimi zmianami w istniejącej funkcji.
Testowanie regresyjne jest rodzajem Testowanie oprogramowania . Przypadki testowe są wykonywane ponownie, aby sprawdzić, czy poprzednia funkcjonalność aplikacji działa poprawnie, a nowe zmiany nie spowodowały żadnych błędów.
Testy regresyjne można przeprowadzić na nowej kompilacji, gdy nastąpi znacząca zmiana w oryginalnej funkcjonalności. Zapewnia to, że kod nadal działa, nawet gdy zachodzą zmiany. Regresja oznacza ponowne przetestowanie tych części aplikacji, które pozostały niezmienione.
Testy regresyjne nazywane są także metodą weryfikacji. Przypadki testowe są często zautomatyzowane. Przypadki testowe muszą być wykonywane wiele razy, a ręczne uruchamianie tego samego przypadku testowego jest czasochłonne i żmudne.
Przykład testów regresyjnych
Tutaj zajmiemy się przypadkiem efektywnego zdefiniowania testów regresyjnych:
Rozważmy produkt Y, w którym jedną z funkcjonalności jest uruchamianie potwierdzenia, akceptacji i wysyłki e-maili. Należy również przetestować, aby upewnić się, że zmiana w kodzie nie ma na nich wpływu. Testowanie regresyjne nie zależy od żadnego języka programowania, takiego jak Jawa , C++ , C# itp. Ta metoda służy do testowania produktu pod kątem modyfikacji lub ewentualnych aktualizacji. Daje pewność, że jakakolwiek zmiana w produkcie nie będzie miała wpływu na istniejący moduł produktu. Sprawdź, czy usunięte błędy i nowo dodane funkcje nie spowodowały żadnych problemów w poprzedniej działającej wersji Oprogramowania.
Kiedy możemy przeprowadzić testy regresyjne?
Testy regresyjne przeprowadzamy za każdym razem, gdy modyfikuje się kod produkcyjny.
Testy regresyjne możemy przeprowadzić w następującym scenariuszu:
1. Kiedy do aplikacji dodano nową funkcjonalność.
Przykład:
Na stronie internetowej dostępna jest funkcja logowania, która pozwala użytkownikom logować się wyłącznie za pomocą poczty elektronicznej. Teraz udostępniamy nową funkcję logowania za pomocą Facebooka.
2. Kiedy istnieje potrzeba zmiany.
Przykład:
Zapamiętaj hasło usunięte ze strony logowania, które obowiązywało wcześniej.
3. Kiedy wada została usunięta
Przykład:
Załóżmy, że przycisk logowania nie działa na stronie logowania, a tester zgłasza błąd informujący, że przycisk logowania jest uszkodzony. Gdy błąd zostanie naprawiony przez programistów, tester testuje go, aby upewnić się, że przycisk logowania działa zgodnie z oczekiwaniami. Jednocześnie tester testuje inną funkcjonalność związaną z przyciskiem logowania.
4. Gdy zostanie rozwiązany problem z wydajnością
Przykład:
Ładowanie strony głównej zajmuje 5 sekund, skracając czas ładowania do 2 sekund.
a b c liczby
5. Kiedy następuje zmiana otoczenia
Przykład:
Kiedy aktualizujemy bazę danych z MySql do Oracle.
Jak przeprowadzić testy regresyjne?
Potrzeba testowania regresyjnego pojawia się, gdy konserwacja oprogramowania obejmuje ulepszenia, korekcję błędów, optymalizację i usuwanie istniejących funkcji. Modyfikacje te mogą mieć wpływ na funkcjonalność systemu. W tym przypadku konieczne staje się testowanie regresji.
Testowanie regresyjne można przeprowadzić przy użyciu następujących technik:
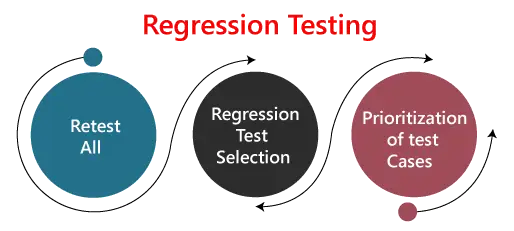
1. Przetestuj ponownie wszystko:
Re-Test jest jedną z metod przeprowadzania testów regresyjnych. W tym podejściu wszystkie zestawy przypadków testowych powinny zostać wykonane ponownie. Tutaj możemy zdefiniować ponowny test jako sytuację, w której test się nie powiedzie, i ustalimy, że przyczyną niepowodzenia jest błąd oprogramowania. Usterka zgłoszona, możemy spodziewać się nowej wersji oprogramowania, w której usterka została naprawiona. W takim przypadku będziemy musieli ponownie wykonać test, aby potwierdzić, że usterka została naprawiona. Nazywa się to ponownym testowaniem. Niektórzy będą nazywać to testowaniem potwierdzającym.
Ponowne badanie jest bardzo kosztowne, ponieważ wymaga ogromnego czasu i zasobów.
2. Test regresji Wybór:
- W tej technice zostanie wykonany wybrany zestaw przypadków testowych, a nie cały zestaw przypadków testowych.
- Wybrany przypadek testowy jest podzielony na dwa przypadki
- Przypadki testowe wielokrotnego użytku.
- Przestarzałe przypadki testowe.
- Przypadki testowe wielokrotnego użytku można wykorzystać w kolejnym cyklu regresji.
- Przestarzałych przypadków testowych nie można wykorzystać w kolejnym cyklu regresji.
3. Priorytetyzacja przypadków testowych:
Nadaj priorytet przypadkowi testowemu w zależności od wpływu biznesowego, krytycznej i często używanej funkcjonalności. Wybór przypadków testowych zmniejszy zestaw testów regresyjnych.
Jakie są narzędzia do testowania regresyjnego?
Testowanie regresyjne jest istotną częścią procesu kontroli jakości; podczas wykonywania regresji możemy napotkać następujące wyzwania:
Ciąg boolowski Java
Wykonanie testów regresyjnych zajmuje dużo czasu. Testowanie regresyjne polega na ponownym uruchomieniu istniejących testów, więc testerzy nie są podekscytowani ponownym przeprowadzaniem testu.
Testowanie regresyjne jest również złożone, gdy istnieje potrzeba aktualizacji dowolnego produktu; listy testowe również rosną.
Testowanie regresyjne zapewnia, że istniejące funkcje produktu nadal działają. Komunikacja na temat testów regresyjnych z liderem nietechnicznym może być trudnym zadaniem. Dyrektor chce, aby produkt rozwijał się i poinwestował znaczną ilość czasu w testy regresyjne, aby upewnić się, że działanie istniejących funkcji może być trudne.
Proces testowania regresyjnego
Proces testowania regresyjnego można przeprowadzić na całym obszarze buduje i wydania .
Testy regresyjne w kompilacjach
Za każdym razem, gdy błąd zostanie naprawiony, ponownie testujemy błąd i jeśli istnieje jakiś moduł zależny, przystępujemy do testów regresyjnych.

Na przykład , Jak przeprowadzamy testy regresyjne, jeśli mamy różne kompilacje, jak Budowa 1, Budowa 2 i Budowa 3 , które mają różne scenariusze.
Kompilacja 1
- W pierwszej kolejności klient zapewni potrzeby biznesowe.
- Następnie zespół programistów zaczyna opracowywać funkcje.
- Następnie zespół testowy rozpocznie pisanie przypadków testowych; na przykład piszą 900 przypadków testowych dla wydania nr 1 produktu.
- Następnie zaczną wdrażać przypadki testowe.
- Po wydaniu produktu klient przeprowadza jedną rundę testów akceptacyjnych.
- I na koniec produkt zostaje przeniesiony na serwer produkcyjny.
Kompilacja 2
- Teraz klient prosi o dodanie 3-4 dodatkowych (nowych) funkcji, a także podaje wymagania dotyczące nowych funkcji.
- Zespół programistów rozpoczyna opracowywanie nowych funkcji.
- Następnie zespół testowy rozpocznie pisanie przypadku testowego dla nowych funkcji i napisze około 150 nowych przypadków testowych. Dlatego łączna liczba napisanych przypadków testowych wynosi 1050 dla obu wydań.
- Teraz zespół testowy rozpoczyna testowanie nowych funkcji przy użyciu 150 nowych przypadków testowych.
- Po zakończeniu zaczną testować stare funkcje za pomocą 900 przypadków testowych, aby sprawdzić, czy dodanie nowej funkcji uszkodziło stare funkcje, czy nie.
- Tutaj testowanie starych funkcji jest znane jako Testowanie regresyjne .
- Po przetestowaniu wszystkich funkcji (Nowego i Starego) produkt zostaje przekazany klientowi, po czym ten przeprowadza testy akceptacyjne.
- Po zakończeniu testów akceptacyjnych produkt trafia na serwer produkcyjny.
Kompilacja 3
- Po drugiej wersji klient chce usunąć jedną z funkcji, np. Sprzedaż.
- Następnie usunie wszystkie przypadki testowe należące do modułu sprzedażowego (około 120 przypadków testowych).
- Następnie przetestuj drugą funkcję, aby sprawdzić, czy wszystkie pozostałe funkcje działają poprawnie po usunięciu przypadków testowych modułu sprzedaży, a proces ten odbywa się w ramach testów regresyjnych.
Notatka:
- Testowanie stabilnych funkcji, aby upewnić się, że nie działają one z powodu zmian. Tutaj zmiany oznaczają, że modyfikację, dodanie, naprawienie błędów lub usunięcie .
- Ponowne wykonanie tych samych przypadków testowych w różnych kompilacjach lub wydaniach ma na celu zapewnienie, że zmiany (modyfikacja, dodanie, naprawienie błędów lub usunięcie) nie wprowadzają błędów do stabilnych funkcji.
Testowanie regresyjne w całej wersji
Proces testowania regresyjnego rozpoczyna się za każdym razem, gdy pojawia się nowa wersja tego samego projektu, ponieważ nowa funkcja może mieć wpływ na stare elementy z poprzednich wersji.
Aby zrozumieć proces testowania regresyjnego, wykonamy poniższe kroki:
Krok 1
Nie ma testów regresyjnych Wydanie nr 1 ponieważ w wydaniu nr 1 nie ma żadnych modyfikacji, ponieważ samo wydanie jest nowe.
Krok 2
Koncepcja testów regresyjnych zaczyna się od Wydanie nr 2 kiedy klient daje trochę nowe wymagania .
Krok 3
Po zapoznaniu się z nowymi wymaganiami (modyfikacją funkcji) oni (programiści i inżynierowie testujący) zrozumieją potrzeby przed przejściem do analiza wpływu .
Krok 4
Po zapoznaniu się z nowymi wymaganiami przeprowadzimy jedną rundę analiza wpływu aby uniknąć głównego ryzyka, ale tutaj pojawia się pytanie, kto przeprowadzi analizę wpływu?
Krok 5
Analizę wpływu przeprowadza firma klient na ich podstawie Wiedza biznesowa , deweloper na ich podstawie wiedza o kodowaniu , a co najważniejsze, robi to przez inżynier testów ponieważ mają znajomość produktu .
Uwaga: jeśli zrobi to jedna osoba, może ona nie objąć wszystkich obszarów wpływu, dlatego uwzględniamy wszystkie osoby, aby móc objąć maksymalny obszar wpływu, a analizę wpływu należy przeprowadzić na wczesnych etapach publikacji.
Krok 6
Gdy już skończymy z obszar uderzenia , następnie programista przygotuje plik obszar oddziaływania (dokument) , oraz klient przygotuje również dokument dotyczący obszaru oddziaływania abyśmy mogli osiągnąć maksymalny zakres analizy wpływu .
Krok 7
Po zakończeniu analizy wpływu programista, klient i inżynier testowy prześlą plik Raporty# dokumentów obszaru oddziaływania do Przewód . W międzyczasie inżynier testowy i programista są zajęci pracą nad nowym przypadkiem testowym.
Krok 8
Gdy lider testowy otrzyma raporty #, zrobi to konsolidować raporty i przechowywane w Repozytorium wymagań przypadków testowych dla wydania nr 1.
Uwaga: Repozytorium przypadków testowych: Tutaj będziemy zapisywać wszystkie przypadki testowe wydań.
Krok 9
Następnie Lider Testów skorzysta z pomocy RTM i wybierze niezbędne elementy przypadek testu regresyjnego z repozytorium przypadków testowych , a pliki te zostaną umieszczone w folderze Zestaw testów regresji .
Notatka:
- Lider testowy zapisze przypadek testu regresyjnego w zestawie testów regresyjnych, aby uniknąć dalszych nieporozumień.

Krok 10
Następnie, gdy inżynier testowy zakończy pracę nad nowymi przypadkami testowymi, zajmie się tym kierownik testowy przypisz przypadek testowy regresji do inżyniera testowego.
Krok 11
Kiedy wszystkie przypadki testów regresyjnych i nowe funkcje są stabilny i przechodzi , a następnie sprawdź obszar uderzenia za pomocą przypadku testowego do czasu, aż będzie trwały dla starych funkcji i nowych funkcji, a następnie zostanie przekazany klientowi.

Rodzaje testów regresyjnych
Wyróżnia się następujące rodzaje testów regresyjnych:
- Testowanie regresji jednostkowej [URT]
- Regionalne testy regresyjne [RRT]
- Pełne lub pełne testowanie regresji [FRT]

1) Testowanie regresji jednostkowej [URT]
W tym przypadku przetestujemy tylko zmienioną jednostkę, a nie obszar uderzenia, ponieważ może to mieć wpływ na elementy tego samego modułu.
Przykład 1
W poniższej aplikacji i w pierwszej kompilacji programista opracowuje plik Szukaj przycisk, który akceptuje 1-15 znaków . Następnie inżynier testowy testuje przycisk Szukaj za pomocą narzędzia technika projektowania przypadków testowych .

Teraz klient wprowadza pewne modyfikacje w wymaganiu, a także żąda, aby plik Przycisk wyszukiwania może zaakceptować 1-35 znaków . Inżynier testowy przetestuje tylko przycisk Szukaj, aby sprawdzić, czy zajmuje on od 1 do 35 znaków i nie sprawdza żadnych dalszych funkcji pierwszej kompilacji.
Przykład2
Mamy tutaj Zbuduj B001 , a defekt zostanie zidentyfikowany, a raport zostanie dostarczony programiście. Deweloper naprawi błąd i wyśle wraz z kilkoma nowymi funkcjami, które zostaną opracowane w drugiej części Zbuduj B002 . Następnie inżynier testowy przeprowadzi test dopiero po naprawieniu wady.
- Inżynier testowy zidentyfikuje, że kliknięcie przycisku Składać przycisk powoduje przejście do pustej strony.
- Jest to wada i jest wysyłana do programisty w celu jej naprawienia.
- Kiedy nowa kompilacja będzie zawierać poprawki błędów, inżynier testowy przetestuje tylko przycisk Prześlij.
- I tutaj nie będziemy sprawdzać innych funkcji pierwszej kompilacji i przechodzić do testowania nowych funkcji przesłanych w drugiej kompilacji.
- Jesteśmy pewni, że naprawienie Składać nie będzie miał wpływu na inne funkcje, dlatego testujemy tylko naprawiony błąd.

Dlatego możemy powiedzieć, że testując tylko zmienioną funkcję, nazywamy ją Testowanie regresji jednostkowej .
2) Regionalne testy regresyjne [RRT]
W tym przypadku przetestujemy modyfikację wraz z obszarem lub obszarami oddziaływania, tzw Regionalne testy regresyjne . Tutaj testujemy obszar wpływu, ponieważ jeśli istnieją niezawodne moduły, będzie to miało wpływ również na inne moduły.
Na przykład:
Na poniższym obrazku widzimy, że mamy cztery różne moduły, takie jak Moduł A, moduł B, moduł C i moduł D , które programiści udostępniają do testów podczas pierwszej kompilacji. Teraz inżynier testowy zidentyfikuje błędy Moduł D . Raport o błędzie jest wysyłany do programistów, a zespół programistów naprawia te defekty i wysyła drugą kompilację.

W drugiej kompilacji naprawiono poprzednie defekty. Teraz inżynier testowy rozumie, że naprawienie błędów w module D wpłynęło na niektóre funkcje Moduł A i moduł C . Dlatego inżynier testowy najpierw testuje Moduł D, w którym naprawiono błąd, a następnie sprawdza obszary wpływu Moduł A i moduł C . Dlatego to badanie nazywa się Regionalne testy regresyjne.
Podczas wykonywania testów regresji regionalnej możemy napotkać następujący problem:
polecenie linii AutoCAD
Problem:
W pierwszej kompilacji klient przesyła pewne modyfikacje wymagań, a także chce dodać nowe funkcje do produktu. Potrzeby kierowane są do obu zespołów, tj. rozwojowego i testującego.
Po otrzymaniu wymagań zespół programistów rozpoczyna modyfikację, a także opracowuje nowe funkcje w oparciu o potrzeby.
Teraz lider testów wysyła e-mail do klientów i pyta ich, jakie obszary wpływu zostaną dotknięte po dokonaniu niezbędnych modyfikacji. Dzięki temu klient będzie miał pomysł, które funkcje trzeba przetestować jeszcze raz. Wyśle także e-mail do zespołu programistów, aby dowiedzieć się, na które wszystkie obszary aplikacji będą miały wpływ zmiany i dodanie nowych funkcji.
W podobny sposób klient wysyła e-mail do zespołu testującego z listą obszarów wpływu. Dlatego też kierownik testów zbierze listę skutków od klienta, zespołu programistów i zespołu testującego.
Ten Lista wpływów jest wysyłany do wszystkich inżynierów testujących, którzy przeglądają listę i sprawdzają, czy ich funkcje zostały zmodyfikowane, a jeśli tak, to tak testy regresji regionalnej . Wszystkie obszary uderzenia i obszary zmodyfikowane są testowane przez odpowiednich inżynierów. Każdy inżynier testowy testuje tylko te funkcje, na które modyfikacja mogła mieć wpływ.
Problem z powyższym podejściem polega na tym, że lider testów może nie mieć pełnego obrazu obszarów wpływu, ponieważ zespół programistów i klient mogą nie mieć zbyt wiele czasu na cofanie swoich e-maili.
Rozwiązanie
Aby rozwiązać powyższy problem, wykonamy poniższy proces:
Kiedy pojawi się nowa kompilacja z najnowszymi funkcjami i poprawkami błędów, zespół testowy zorganizuje spotkanie, podczas którego omówią, czy powyższa modyfikacja ma wpływ na ich funkcje. Dlatego zrobią jedną rundę Analiza wpływu i wygeneruj Lista wpływów . Na tej konkretnej liście inżynier testujący stara się ująć maksymalne prawdopodobne obszary uderzenia, co również zmniejsza ryzyko wystąpienia defektów.
Kiedy pojawi się nowa wersja, zespół testowy zastosuje poniższą procedurę:
- Przeprowadzą testy dymne, aby sprawdzić podstawową funkcjonalność aplikacji.
- Następnie przetestują nowe funkcje.
- Następnie sprawdzą zmienione funkcje.
- Po zakończeniu sprawdzania zmienionych funkcji inżynier testowy ponownie przetestuje błędy.
- Następnie sprawdzą obszar oddziaływania, wykonując regionalne testy regresyjne.
Wady stosowania testów regresji jednostkowej i regionalnej
Poniżej przedstawiono niektóre wady stosowania testów regresji jednostkowej i regionalnej:
- Możemy przegapić jakiś obszar oddziaływania.
- Możliwe, że zidentyfikujemy niewłaściwy obszar oddziaływania.
Uwaga: Można powiedzieć, że główna praca, jaką wykonujemy w zakresie regionalnych testów regresyjnych, doprowadzi nas do uzyskania większej liczby defektów. Jeśli jednak z takim samym zaangażowaniem będziemy pracować nad pełnym testowaniem regresyjnym, otrzymamy mniejszą liczbę defektów. Dlatego możemy tutaj ustalić, że zwiększenie wysiłku testowego nie pomoże nam uzyskać większej liczby defektów.
3) Pełne testy regresyjne [FRT]
Podczas drugiej i trzeciej wersji produktu klient prosi o dodanie 3-4 nowych funkcji, a także wymaga usunięcia niektórych usterek z poprzedniej wersji. Następnie zespół testujący przeprowadzi analizę wpływu i ustali, że powyższa modyfikacja doprowadzi nas do przetestowania całego produktu.
Dlatego możemy powiedzieć, że testowanie zmodyfikowane funkcje I wszystkie pozostałe (stare) funkcje nazywa się Pełne testy regresyjne .

Kiedy przeprowadzamy pełne testy regresyjne?
FRT wykonamy, gdy spełnimy następujące warunki:
- Kiedy modyfikacja ma miejsce w pliku źródłowym produktu. Na przykład , JVM jest plikiem głównym aplikacji JAVA i jeśli w JVM nastąpi jakakolwiek zmiana, testowany będzie cały program JAVA.
- Kiedy musimy wykonać n-liczbę zmian.
Notatka:
Testowanie regresji regionalnej jest idealnym podejściem do testów regresji, ale problem polega na tym, że podczas wykonywania testów regresji regionalnej możemy przeoczyć wiele defektów.
I tutaj rozwiążemy ten problem za pomocą następującego podejścia:
- Po przekazaniu wniosku do testów inżynier testowy przetestuje pierwsze 10–14 cykli i wykona RRT .
- Następnie w 15 cyklu wykonujemy FRT. I znowu przez następne 10-15 cykli tak robimy Regionalne testy regresyjne , a dla 31. cyklu robimy pełne testy regresyjne i będziemy to kontynuować.
- Ale przez ostatnie dziesięć cykli wydawnictwa będziemy występować tylko pełne testy regresyjne .
Dlatego jeśli zastosujemy powyższe podejście, możemy uzyskać więcej defektów.
Wady wielokrotnego ręcznego wykonywania testów regresyjnych:
- Produktywność spadnie.
- Jest to trudne zadanie.
- Nie ma spójności w wykonywaniu testów.
- Wydłuża się także czas wykonania testu.
Dlatego postawimy na automatyzację, aby uporać się z tymi problemami; kiedy mamy n-liczbę cyklu testu regresji, przejdziemy do proces testowania regresji automatycznej .
Zautomatyzowany proces testowania regresyjnego
Generalnie decydujemy się na automatyzację zawsze, gdy istnieje wiele wydań, cykl regresji lub gdy zadanie jest powtarzalne.
Proces automatycznego testowania regresji można przeprowadzić w następujących krokach:
Notatka 1:
Proces testowania aplikacji za pomocą niektórych narzędzi nazywany jest testowaniem automatycznym.
Załóżmy, że jeśli weźmiemy jeden przykładowy przykład a Moduł logowania , a następnie w jaki sposób możemy przeprowadzić testy regresyjne.
W tym przypadku logowania można dokonać na dwa sposoby, które są następujące:

Ręcznie: W tym przypadku przeprowadzimy regresję tylko raz i dwa razy.
Automatyzacja: W tym przypadku wykonamy automatyzację wiele razy, ponieważ musimy napisać skrypty testowe i wykonać wykonanie.
Uwaga 2: W czasie rzeczywistym, jeśli napotkaliśmy pewne problemy, takie jak:
| Kwestie | Obsługiwać |
|---|---|
| Nowe funkcje | Inżynier testów ręcznych |
| Regresja funkcji testowych | Inżynier testów automatycznych |
| Pozostałe (110 funkcji + wydanie nr 1) | Inżynier testów ręcznych |
Krok 1
Kiedy wystartuje nowa wersja, nie stawiamy na automatyzację, ponieważ nie ma koncepcji testów regresyjnych i przypadku testów regresyjnych, tak jak to zrozumieliśmy w powyższym procesie.
Krok 2
Kiedy zaczyna się nowa wersja i ulepszenia, mamy dwa zespoły, tj. zespół zajmujący się ręcznym i zespół ds. automatyzacji.
Krok 3
wiosna i wiosna mvc
Zespół ręczny przejrzy wymagania, a także zidentyfikuje obszar wpływu i przekaże zestaw testów wymagań do zespołu automatyki.
Krok 4
Teraz zespół zajmujący się manualem rozpoczyna pracę nad nowymi funkcjami, a zespół automatyzujący rozpocznie opracowywanie skryptu testowego, a także rozpocznie automatyzację przypadku testowego, co oznacza, że przypadki testowe regresji zostaną przekonwertowane na skrypt testowy.
Krok 5
Zanim oni (zespół automatyzujący) zaczną automatyzować przypadek testowy, przeanalizują również, które wszystkie przypadki można zautomatyzować, czy nie.
Krok 6
Na podstawie analizy rozpoczną automatyzację, czyli konwersję wszystkich przypadków testów regresyjnych na skrypt testowy.
Krok 7
Podczas tego procesu skorzystają z pomocy Przypadki regresji ponieważ nie mają tak dobrej wiedzy o produkcie jak narzędzie i aplikacja .
Krok 8
Gdy skrypt testowy będzie gotowy, rozpoczną wykonywanie tych skryptów w nowej aplikacji [stara funkcja]. Ponieważ skrypt testowy jest pisany przy pomocy funkcji regresji lub starej funkcji.
Krok 9
Po zakończeniu realizacji otrzymujemy inny status, np Zdany/nieudany .
Krok 10
Jeśli status jest nieprawidłowy, co oznacza, że należy go ponownie potwierdzić ręcznie, i jeśli błąd istnieje, zostanie on zgłoszony odpowiedniemu programiście. Kiedy programista naprawi ten błąd, błąd musi zostać ponownie przetestowany wraz z obszarem Impact przez inżyniera ds. testów ręcznych, a także ponownie wykonany skrypt przez inżyniera ds. testów automatycznych.
Krok 11
Proces ten trwa do momentu, aż wszystkie nowe funkcje zostaną przekazane, a funkcja regresji zostanie przekazana.

Korzyści z przeprowadzania testów regresyjnych za pomocą testów automatycznych:
- Skrypt testowy może być ponownie używany w wielu wersjach.
- Mimo że liczba przypadków testowych regresji zwiększa się w każdym wydaniu i nie musimy zwiększać zasobów automatyzacji, ponieważ niektóre przypadki regresji są już zautomatyzowane w porównaniu z poprzednią wersją.
- To jest proces oszczędzający czas ponieważ wykonanie jest zawsze szybsze niż metoda ręczna.
Jak wybrać przypadki testowe do testów regresyjnych?
Stwierdzono to podczas kontroli branżowej. Kilka usterek zgłoszonych przez klienta wynikało z poprawek błędów w ostatniej chwili. Tworzenie efektów ubocznych i tym samym wybór przypadku testowego do testów regresyjnych jest sztuką, a nie łatwym zadaniem.
Test regresji można wykonać poprzez:
lista metod Java
- Przypadek testowy, który ma częste defekty
- Funkcjonalności bardziej widoczne dla użytkowników.
- Przypadki testowe weryfikują podstawowe cechy produktu.
- Wszystkie przypadki testów integracyjnych
- Wszystkie złożone przypadki testowe
- Przypadki testowe wartości brzegowych
- Przykład udanych przypadków testowych
- Niepowodzenie przypadków testowych
Narzędzia do testowania regresji
Jeśli Oprogramowanie ulega częstym zmianom, koszty testów regresyjnych również rosną. W takich przypadkach ręczne wykonanie przypadków testowych wydłuża czas i koszty wykonywania testów. W takim przypadku najlepszym wyborem będą testy automatyczne. Czas trwania automatyzacji zależy od liczby przypadków testowych, które można ponownie wykorzystać w kolejnych cyklach regresji.
Poniżej znajdują się podstawowe narzędzia używane do testów regresyjnych:
Selen
Selenium jest narzędziem typu open source. To narzędzie służące do automatycznego testowania aplikacji internetowej. Do testów regresyjnych w przeglądarce użyto selenu. Selen używany do testu regresji na poziomie interfejsu użytkownika dla aplikacji internetowych.
Studio Ranorex
Wszystko w jednej automatyzacji testów regresyjnych dla aplikacji komputerowych, internetowych i mobilnych z wbudowanym sterownikiem internetowym Selenium. Ranorex Studio zawiera pełne środowisko IDE oraz narzędzia do bezkodowej automatyzacji.
Szybki test profesjonalny (QTP)
QTP to zautomatyzowane narzędzie testujące używane do testów regresyjnych i funkcjonalnych. Jest to narzędzie oparte na danych i słowach kluczowych. Do automatyzacji wykorzystano język VBScript. Jeśli otworzymy narzędzie QTP, zobaczymy trzy przyciski, które są Nagrywaj, odtwarzaj i zatrzymuj . Przyciski te pomagają rejestrować każde kliknięcie i czynność wykonaną w systemie komputerowym. Rejestruje czynności i odtwarza je.

Racjonalny tester funkcjonalny (RTF)
Rational tester funkcjonalny to narzędzie Java służące do automatyzacji przypadków testowych aplikacji. RTF służy do automatyzacji przypadków testów regresyjnych, a także integruje się z racjonalnym testerem funkcjonalnym.
Więcej informacji na temat narzędzi do testów regresyjnych i automatycznych można znaleźć pod poniższym linkiem:
https://www.javatpoint.com/automation-testing-tool
Testowanie regresyjne i zarządzanie konfiguracją
Zarządzanie konfiguracją w testach regresyjnych staje się koniecznością w środowiskach Agile, gdzie kod jest stale modyfikowany. Aby zapewnić prawidłowy test regresji, musimy wykonać następujące kroki:
- Zmiany w kodzie podczas fazy testów regresyjnych są niedozwolone.
- Przypadek testu regresyjnego musi obejmować zmiany programisty, na które nie mają one wpływu.
- Baza danych używana do testów regresyjnych musi być izolowana; zmiany w bazie danych są niedozwolone.
Różnice między ponownym testowaniem a testowaniem regresyjnym
Ponowne testowanie Testowanie oznacza ponowne przetestowanie funkcjonalności lub błędu, aby upewnić się, że kod został naprawiony. Jeżeli nie ustawiono, wady nie muszą być ponownie otwierane. Jeśli zostanie naprawiony, wada zostanie zamknięta.
Ponowne testowanie to rodzaj testów przeprowadzanych w celu sprawdzenia, czy przypadki testowe, które nie powiodły się w ostatecznym wykonaniu, pomyślnie przechodzą po naprawieniu defektów.
Testowanie regresyjne oznacza testowanie aplikacji po zmianie kodu, aby upewnić się, że nowy kod nie ma wpływu na inne części Oprogramowania.
Testowanie regresyjne to rodzaj testów przeprowadzanych w celu sprawdzenia, czy kod nie zmienił istniejącej funkcjonalności aplikacji.
Różnice pomiędzy ponownym testowaniem a testowaniem regresyjnym są następujące:
| Ponowne testowanie | Testowanie regresyjne |
|---|---|
| Ponowne testowanie jest przeprowadzane w celu zapewnienia, że przypadki testowe, które zakończyły się niepowodzeniem w ostatecznym wykonaniu, zostaną zaliczone po naprawieniu defektów. | Testy regresyjne przeprowadza się w celu potwierdzenia, czy zmiana kodu nie miała wpływu na istniejące funkcje. |
| Ponowne testowanie działa w celu usunięcia usterek. | Celem testów regresyjnych jest upewnienie się, że zmiany w kodzie nie mają negatywnego wpływu na istniejącą funkcjonalność. |
| Weryfikacja defektów jest częścią ponownego testowania. | Testowanie regresyjne nie obejmuje weryfikacji defektów |
| Priorytet ponownego testowania jest wyższy niż testowania regresyjnego, dlatego przeprowadza się go przed testowaniem regresyjnym. | W zależności od rodzaju projektu i dostępności zasobów testy regresyjne mogą być równoległe do ponownego testowania. |
| Ponowny test to zaplanowane testowanie. | Testowanie regresyjne jest testowaniem ogólnym. |
| Nie możemy zautomatyzować przypadków testowych do ponownego testowania. | Możemy przeprowadzić automatyzację testów regresyjnych; testowanie ręczne może być kosztowne i czasochłonne. |
| Ponowne testowanie dotyczy nieudanych przypadków testowych. | Testowanie regresyjne dotyczy zaliczonych przypadków testowych. |
| Ponowne testowanie upewnia się, że pierwotna usterka została naprawiona. | Testy regresyjne sprawdzają, czy nie występują nieoczekiwane skutki uboczne. |
| Ponowne testowanie powoduje wykonanie defektów z tymi samymi danymi i tym samym środowiskiem, z innymi danymi wejściowymi, w nowej kompilacji. | Testowanie regresyjne ma miejsce wtedy, gdy w istniejącym projekcie następuje modyfikacja lub zmiany stają się obowiązkowe. |
| Ponownego testowania nie można wykonać przed rozpoczęciem testowania. | Testowanie regresyjne pozwala uzyskać przypadki testowe ze specyfikacji funkcjonalnej, samouczków i podręczników użytkownika oraz raportów o defektach w odniesieniu do naprawionego problemu. |
Zalety testów regresyjnych
Zalety testów regresyjnych to:
- Testy regresyjne podnoszą jakość produktu.
- Zapewnia, że wszelkie poprawki lub zmiany błędów nie będą miały wpływu na istniejącą funkcjonalność produktu.
- Narzędzia do automatyzacji można wykorzystać do testów regresyjnych.
- Daje pewność, że rozwiązane problemy nie pojawią się ponownie.
Wady testów regresyjnych
Testowanie regresyjne ma kilka zalet, choć ma też wady.
- Testowanie regresyjne należy przeprowadzać w przypadku małych zmian w kodzie, ponieważ nawet niewielka zmiana w kodzie może spowodować problemy w istniejącej funkcjonalności.
- Jeśli w projekcie nie wykorzystano automatyzacji do testowania, powtarzanie testu będzie czasochłonnym i żmudnym zadaniem.
Wniosek
Testowanie regresyjne jest jednym z istotnych aspektów, ponieważ pomaga dostarczyć produkt wysokiej jakości, który pozwala organizacjom zaoszczędzić czas i pieniądze. Pomaga zapewnić produkt wysokiej jakości, upewniając się, że jakakolwiek zmiana w kodzie nie wpływa na istniejącą funkcjonalność.
Do automatyzacji przypadków testów regresyjnych dostępnych jest kilka narzędzi do automatyzacji. Narzędzie powinno mieć możliwość aktualizacji zestaw testowy ponieważ zestaw testów regresyjnych wymaga częstej aktualizacji.