W prawdziwym świecie nie każde dane, na których pracujemy, mają zmienną docelową. Tego rodzaju danych nie można analizować za pomocą algorytmów uczenia się nadzorowanego. Potrzebujemy pomocy algorytmów nienadzorowanych. Jednym z najpopularniejszych rodzajów analizy w ramach uczenia się bez nadzoru jest segmentacja klientów w przypadku reklam ukierunkowanych lub w obrazowaniu medycznym w celu znalezienia nieznanych lub nowych zainfekowanych obszarów oraz w wielu innych przypadkach użycia, które omówimy w dalszej części tego artykułu.
Spis treści
- Co to jest klastrowanie?
- Rodzaje klastrowania
- Zastosowania klastrowania
- Rodzaje algorytmów grupowania
- Zastosowania klastrowania w różnych dziedzinach:
- Często zadawane pytania (FAQ) dotyczące klastrowania
Co to jest klastrowanie?
Zadanie grupowania punktów danych na podstawie ich wzajemnego podobieństwa nazywa się grupowaniem lub analizą skupień. Metoda ta jest zdefiniowana w gałęzi Uczenie się bez nadzoru , którego celem jest uzyskanie spostrzeżeń z nieoznakowanych punktów danych, czyli w przeciwieństwie do Nadzorowana nauka nie mamy zmiennej docelowej.
Klastrowanie ma na celu utworzenie grup jednorodnych punktów danych z heterogenicznego zbioru danych. Ocenia podobieństwo w oparciu o metrykę, taką jak odległość euklidesowa, podobieństwo cosinusowe, odległość Manhattanu itp., a następnie grupuje punkty o najwyższym wyniku podobieństwa.
Na przykład na poniższym wykresie wyraźnie widać, że istnieją 3 gromady kołowe tworzące się na podstawie odległości.
jak przekonwertować z int na string w Javie
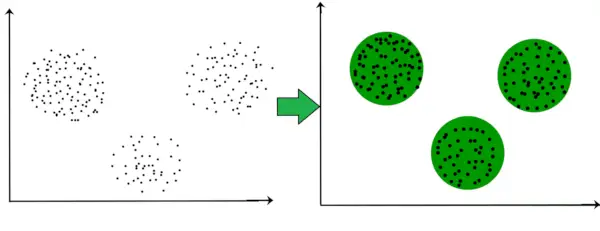
Nie jest już konieczne, aby utworzone klastry miały kształt okrągły. Kształt klastrów może być dowolny. Istnieje wiele algorytmów, które dobrze sprawdzają się przy wykrywaniu klastrów o dowolnym kształcie.
porównaj z metodą Java
Na przykład na poniższym wykresie widać, że utworzone klastry nie mają kształtu okrągłego.

Rodzaje klastrowania
Ogólnie rzecz biorąc, istnieją 2 typy grupowania, które można zastosować w celu zgrupowania podobnych punktów danych:
- Klastrowanie twarde: W tego typu grupowaniu każdy punkt danych należy całkowicie lub nie do klastra. Załóżmy na przykład, że istnieją 4 punkty danych i musimy je zgrupować w 2 klastry. Zatem każdy punkt danych będzie należeć do klastra 1 lub klastra 2.
| Punkty danych | Klastry |
|---|---|
| A | C1 |
| B | C2 |
| C | C2 |
| D | C1 |
- Klastrowanie miękkie: W tego typu grupowaniu zamiast przypisywać każdy punkt danych do osobnego klastra, ocenia się prawdopodobieństwo lub prawdopodobieństwo, że ten punkt będzie tym klastrem. Załóżmy na przykład, że istnieją 4 punkty danych i musimy je zgrupować w 2 klastry. Będziemy więc oceniać prawdopodobieństwo, że punkt danych należy do obu klastrów. Prawdopodobieństwo to jest obliczane dla wszystkich punktów danych.
| Punkty danych | Prawdopodobieństwo C1 | Prawdopodobieństwo C2 |
| A | 0,91 | 0,09 |
| B | 0,3 | 0,7 |
| C | 0,17 | 0,83 |
| D | 1 | 0 |
Zastosowania klastrowania
Zanim zaczniemy od typów algorytmów grupowania, omówimy przypadki użycia algorytmów grupowania. Algorytmy klastrowania są wykorzystywane głównie do:
- Segmentacja rynku – Firmy korzystają z klastrów, aby grupować swoich klientów i używać ukierunkowanych reklam, aby przyciągnąć więcej odbiorców.
- Analiza sieci społecznościowej – Witryny mediów społecznościowych wykorzystują Twoje dane, aby zrozumieć Twoje zachowanie podczas przeglądania i zapewnić Ci ukierunkowane rekomendacje znajomych lub rekomendacje treści.
- Obrazowanie medyczne – lekarze korzystają z klastrowania, aby znaleźć chore obszary na obrazach diagnostycznych, takich jak zdjęcia rentgenowskie.
- Wykrywanie anomalii – Aby znaleźć wartości odstające w strumieniu zbioru danych w czasie rzeczywistym lub prognozować oszukańcze transakcje, możemy zastosować klastrowanie w celu ich identyfikacji.
- Uprość pracę z dużymi zbiorami danych — każdy klaster otrzymuje identyfikator klastra po zakończeniu tworzenia klastrów. Teraz możesz zredukować cały zestaw funkcji zestawu funkcji do jego identyfikatora klastra. Klastrowanie jest skuteczne, gdy może reprezentować skomplikowany przypadek z prostym identyfikatorem klastra. Korzystając z tej samej zasady, grupowanie danych może uprościć złożone zbiory danych.
Istnieje znacznie więcej przypadków użycia klastrowania, ale istnieją pewne główne i powszechne przypadki użycia klastrowania. W dalszej części omówimy algorytmy klastrowania, które pomogą Ci wykonać powyższe zadania.
Rodzaje algorytmów grupowania
Na poziomie powierzchni klastrowanie pomaga w analizie danych nieustrukturyzowanych. Wykresy, najkrótsza odległość i gęstość punktów danych to tylko niektóre z elementów wpływających na tworzenie się klastrów. Grupowanie to proces określania powiązania obiektów w oparciu o metrykę zwaną miarą podobieństwa. Metryki podobieństwa łatwiej jest zlokalizować w mniejszych zestawach funkcji. Tworzenie miar podobieństwa staje się coraz trudniejsze w miarę wzrostu liczby cech. W zależności od rodzaju algorytmu grupowania wykorzystywanego w eksploracji danych, do grupowania danych ze zbiorów danych stosuje się kilka technik. W tej części opisano techniki grupowania. Różne typy algorytmów grupowania to:
przekonwertuj int na ciąg Java
- Klastrowanie oparte na środkach ciężkości (metody partycjonowania)
- Klastrowanie oparte na gęstości (metody oparte na modelu)
- Klastrowanie oparte na łączności (klastrowanie hierarchiczne)
- Klastrowanie oparte na dystrybucji
Pokrótce omówimy każdy z tych typów.
1. Metody partycjonowania to najprostsze algorytmy grupowania. Grupują punkty danych na podstawie ich bliskości. Ogólnie rzecz biorąc, miarą podobieństwa wybraną dla tych algorytmów jest odległość euklidesowa, odległość Manhattanu lub odległość Minkowskiego. Zbiory danych są podzielone na z góry określoną liczbę klastrów, a do każdego klastra odwołuje się wektor wartości. W porównaniu z wartością wektorową zmienna danych wejściowych nie wykazuje żadnej różnicy i przyłącza się do klastra.
Podstawową wadą tych algorytmów jest wymóg, abyśmy ustalili liczbę klastrów k w sposób intuicyjny lub naukowy (przy użyciu metody Elbow), zanim jakikolwiek system uczenia maszynowego grupującego zacznie alokować punkty danych. Mimo to nadal jest to najpopularniejszy rodzaj klastrowania. K-oznacza I K-medoidy klastrowanie to kilka przykładów tego typu grupowania.
przetwarzanie hackerskie
2. Klastrowanie oparte na gęstości (metody oparte na modelu)
Klastrowanie oparte na gęstości, metoda oparta na modelu, znajduje grupy na podstawie gęstości punktów danych. W przeciwieństwie do grupowania opartego na centroidach, które wymaga predefiniowania liczby klastrów i jest wrażliwe na inicjalizację, grupowanie oparte na gęstości automatycznie określa liczbę klastrów i jest mniej podatne na pozycje początkowe. Doskonale radzą sobie z klastrami o różnych rozmiarach i formach, dzięki czemu idealnie nadają się do zbiorów danych o nieregularnych kształtach lub nakładających się klastrach. Metody te zarządzają zarówno gęstymi, jak i rzadkimi obszarami danych, koncentrując się na gęstości lokalnej i umożliwiają rozróżnianie klastrów o różnej morfologii.
Natomiast grupowanie oparte na środkach ciężkości, takie jak k-średnie, ma problemy ze znalezieniem klastrów o dowolnym kształcie. Ze względu na ustawioną liczbę wymagań dotyczących klastrów i wyjątkową wrażliwość na początkowe pozycjonowanie centroidów wyniki mogą się różnić. Co więcej, tendencja podejść opartych na środkach ciężkości do tworzenia klastrów kulistych lub wypukłych ogranicza ich zdolność do obsługi klastrów skomplikowanych lub o nieregularnym kształcie. Podsumowując, grupowanie oparte na gęstości przezwycięża wady technik opartych na centroidach, autonomicznie wybierając rozmiary klastrów, będąc odpornym na inicjalizację i skutecznie przechwytując klastry o różnych rozmiarach i formach. Najpopularniejszym algorytmem klastrowania opartym na gęstości jest DBSCAN .
3. Klastrowanie oparte na łączności (klastrowanie hierarchiczne)
Metoda łączenia powiązanych punktów danych w klastry hierarchiczne nazywana jest grupowaniem hierarchicznym. Każdy punkt danych jest początkowo brany pod uwagę jako oddzielny klaster, który następnie jest łączony z klastrami, które są najbardziej podobne, w celu utworzenia jednego dużego klastra zawierającego wszystkie punkty danych.
Zastanów się, jak możesz uporządkować kolekcję przedmiotów na podstawie ich podobieństwa. Każdy obiekt zaczyna się jako własny klaster u podstawy drzewa, gdy stosuje się grupowanie hierarchiczne, które tworzy dendrogram, strukturę przypominającą drzewo. Najbliższe pary klastrów są następnie łączone w większe skupienia po tym, jak algorytm sprawdzi, jak podobne są do siebie obiekty. Kiedy każdy obiekt znajdzie się w jednym klastrze na szczycie drzewa, proces łączenia zostanie zakończony. Eksplorowanie różnych poziomów szczegółowości to jedna z najfajniejszych rzeczy w klastrowaniu hierarchicznym. Aby uzyskać określoną liczbę skupień, możesz wybrać opcję wycięcia dendrogram na określonej wysokości. Im bardziej podobne są dwa obiekty w klastrze, tym są one bliżej. Można to porównać do klasyfikowania przedmiotów według ich drzew genealogicznych, gdzie najbliżsi krewni są skupieni razem, a szersze gałęzie oznaczają bardziej ogólne powiązania. Istnieją 2 podejścia do grupowania hierarchicznego:
- Klastrowanie dzielące : Jest to podejście odgórne, w którym wszystkie punkty danych traktujemy jako część jednego dużego klastra, a następnie klaster ten dzieli się na mniejsze grupy.
- Klastrowanie aglomeracyjne : Opiera się na podejściu oddolnym, w tym przypadku wszystkie punkty danych traktujemy jako część indywidualnych klastrów, a następnie klastry te łączy się w jeden duży klaster ze wszystkimi punktami danych.
4. Klastrowanie oparte na dystrybucji
Korzystając z grupowania opartego na dystrybucji, punkty danych są generowane i organizowane zgodnie z ich skłonnością do wpadania w ten sam rozkład prawdopodobieństwa (taki jak Gaussa, dwumian lub inny) w danych. Elementy danych są pogrupowane przy użyciu rozkładu prawdopodobieństwa opartego na rozkładach statystycznych. Uwzględnione są obiekty danych, które mają większe prawdopodobieństwo znalezienia się w klastrze. Jest mniejsze prawdopodobieństwo, że punkt danych zostanie włączony do klastra, im dalej będzie się znajdował od centralnego punktu klastra, który istnieje w każdym klastrze.
Istotną wadą podejść gęstościowych i opartych na granicach jest konieczność określenia a priori klastrów dla niektórych algorytmów, a przede wszystkim zdefiniowania postaci klastrów dla większości algorytmów. Musi być wybrany co najmniej jeden parametr dostrajający lub hiperparametr, a wykonanie tej czynności powinno być proste, a błędne ustawienie może mieć nieprzewidziane konsekwencje. Klastrowanie oparte na dystrybucji ma zdecydowaną przewagę nad podejściami opartymi na klastrowaniu bliskości i centroidach pod względem elastyczności, dokładności i struktury klastrów. Kluczową kwestią jest to, aby tego uniknąć nadmierne dopasowanie , wiele metod grupowania działa tylko z danymi symulowanymi lub wyprodukowanymi lub gdy większość punktów danych z pewnością należy do ustalonego rozkładu. Najpopularniejszym algorytmem klastrowania opartym na dystrybucji jest Model mieszaniny Gaussa .
Zastosowania klastrowania w różnych dziedzinach:
- Marketing: Można go używać do charakteryzowania i odkrywania segmentów klientów w celach marketingowych.
- Biologia: Można go stosować do klasyfikacji różnych gatunków roślin i zwierząt.
- Biblioteki: Służy do grupowania różnych książek na podstawie tematów i informacji.
- Ubezpieczenie: Służy do zapoznania się z klientami, ich polityką i identyfikacją oszustw.
- Planowanie miasta: Służy do tworzenia grup domów i badania ich wartości na podstawie ich położenia geograficznego i innych czynników.
- Badania dotyczące trzęsień ziemi: Poznając obszary dotknięte trzęsieniem ziemi, możemy określić strefy niebezpieczne.
- Przetwarzanie obrazu : Grupowanie można wykorzystać do grupowania podobnych obrazów, klasyfikowania obrazów na podstawie zawartości i identyfikowania wzorców w danych obrazu.
- Genetyka: Klastrowanie służy do grupowania genów o podobnych wzorcach ekspresji i identyfikowania sieci genów współpracujących ze sobą w procesach biologicznych.
- Finanse: Klastrowanie służy do identyfikacji segmentów rynku na podstawie zachowań klientów, identyfikacji wzorców w danych giełdowych i analizy ryzyka w portfelach inwestycyjnych.
- Obsługa klienta: Klastrowanie służy do grupowania zapytań i skarg klientów w kategorie, identyfikowania typowych problemów i opracowywania ukierunkowanych rozwiązań.
- Produkcja : Klastrowanie służy do grupowania podobnych produktów, optymalizacji procesów produkcyjnych i identyfikowania defektów w procesach produkcyjnych.
- Diagnoza medyczna: Grupowanie służy do grupowania pacjentów z podobnymi objawami lub chorobami, co pomaga w postawieniu trafnej diagnozy i określeniu skutecznego leczenia.
- Wykrywanie oszustw: Klastrowanie służy do identyfikowania podejrzanych wzorców lub anomalii w transakcjach finansowych, co może pomóc w wykrywaniu oszustw lub innych przestępstw finansowych.
- Analiza ruchu: Klastrowanie służy do grupowania podobnych wzorców danych o ruchu, takich jak godziny szczytu, trasy i prędkości, co może pomóc w ulepszeniu planowania transportu i infrastruktury.
- Analiza sieci społecznościowych: Klastrowanie służy do identyfikowania społeczności lub grup w sieciach społecznościowych, co może pomóc w zrozumieniu zachowań społecznych, wpływów i trendów.
- Bezpieczeństwo cybernetyczne: Klastrowanie służy do grupowania podobnych wzorców ruchu sieciowego lub zachowania systemu, co może pomóc w wykrywaniu cyberataków i zapobieganiu im.
- Analiza klimatu: Klastrowanie służy do grupowania podobnych wzorców danych klimatycznych, takich jak temperatura, opady i wiatr, co może pomóc w zrozumieniu zmian klimatycznych i ich wpływu na środowisko.
- Analiza sportowa: Klastrowanie służy do grupowania podobnych wzorców danych dotyczących wydajności gracza lub zespołu, co może pomóc w analizowaniu mocnych i słabych stron gracza lub zespołu oraz podejmowaniu strategicznych decyzji.
- Analiza kryminalna: Klastrowanie służy do grupowania podobnych wzorców danych dotyczących przestępczości, takich jak lokalizacja, czas i rodzaj, co może pomóc w identyfikowaniu głównych punktów przestępczości, przewidywaniu przyszłych trendów przestępczości i ulepszaniu strategii zapobiegania przestępczości.
Wniosek
W tym artykule omówiliśmy klastrowanie, jego rodzaje i zastosowania w prawdziwym świecie. W uczeniu bez nadzoru jest dużo więcej do omówienia, a analiza skupień to dopiero pierwszy krok. Ten artykuł może pomóc Ci rozpocząć pracę z algorytmami klastrowania i pomóc w uzyskaniu nowego projektu, który można dodać do swojego portfolio.
Często zadawane pytania (FAQ) dotyczące klastrowania
P. Jaka jest najlepsza metoda grupowania?
10 najlepszych algorytmów grupowania to:
bash, jeśli jeszcze
- K-oznacza grupowanie
- Klastrowanie hierarchiczne
- DBSCAN (klasowanie przestrzenne aplikacji z szumem w oparciu o gęstość)
- Modele mieszaniny Gaussa (GMM)
- Klastrowanie aglomeracyjne
- Klastrowanie widmowe
- Klastrowanie średniego przesunięcia
- Propagacja powinowactwa
- OPTYKA (punkty porządkowania w celu identyfikacji struktury klastrowej)
- Brzoza (zrównoważona iteracyjna redukcja i grupowanie przy użyciu hierarchii)
P. Jaka jest różnica między grupowaniem a klasyfikacją?
Główna różnica między grupowaniem a klasyfikacją polega na tym, że klasyfikacja jest algorytmem uczenia się nadzorowanego, a grupowanie jest algorytmem uczenia się bez nadzoru. Oznacza to, że stosujemy grupowanie do tych zbiorów danych, które nie zawierają zmiennej docelowej.
P. Jakie są zalety analizy skupień?
Dane można organizować w znaczące grupy przy użyciu silnego narzędzia analitycznego, jakim jest analiza skupień. Możesz go używać do wskazywania segmentów, znajdowania ukrytych wzorców i poprawiania decyzji.
P. Która metoda grupowania jest najszybsza?
Grupowanie K-średnich jest często uważane za najszybszą metodę grupowania ze względu na jej prostotę i wydajność obliczeniową. Iteracyjnie przypisuje punkty danych do najbliższego środka ciężkości klastra, dzięki czemu nadaje się do dużych zbiorów danych o niskiej wymiarowości i umiarkowanej liczbie klastrów.
P. Jakie są ograniczenia klastrowania?
Ograniczenia grupowania obejmują wrażliwość na warunki początkowe, zależność od wyboru parametrów, trudności w określeniu optymalnej liczby klastrów oraz wyzwania związane z obsługą danych wielowymiarowych lub zaszumionych.
P. Od czego zależy jakość wyniku grupowania?
Jakość wyników grupowania zależy od takich czynników, jak wybór algorytmu, metryka odległości, liczba klastrów, metoda inicjalizacji, techniki wstępnego przetwarzania danych, metryki oceny klastrów i wiedza dziedzinowa. Elementy te łącznie wpływają na skuteczność i dokładność wyniku grupowania.