Jak wiemy, algorytm nadzorowanego uczenia maszynowego można ogólnie podzielić na algorytmy regresji i klasyfikacji. W algorytmach regresji przewidywaliśmy wynik dla wartości ciągłych, ale aby przewidzieć wartości kategoryczne, potrzebujemy algorytmów klasyfikacji.
Jaki jest algorytm klasyfikacji?
Algorytm klasyfikacji jest techniką uczenia się nadzorowanego, która służy do identyfikacji kategorii nowych obserwacji na podstawie danych uczących. W klasyfikacji program uczy się na podstawie danego zbioru danych lub obserwacji, a następnie klasyfikuje nowe obserwacje w szereg klas lub grup. Jak na przykład, Tak lub Nie, 0 lub 1, Spam lub Nie Spam, kot czy pies, itp. Klasy mogą być wywoływane jako cele/etykiety lub kategorie.
Jak znaleźć ukryte aplikacje na Androidzie
W przeciwieństwie do regresji, zmienną wyjściową Klasyfikacji jest kategoria, a nie wartość, np. „Zielony lub Niebieski”, „owoc lub zwierzę” itp. Ponieważ algorytm Klasyfikacji jest techniką uczenia się nadzorowanego, dlatego pobiera oznaczone dane wejściowe, które oznacza, że zawiera dane wejściowe z odpowiednim wyjściem.
W algorytmie klasyfikacji dyskretna funkcja wyjściowa (y) jest odwzorowywana na zmienną wejściową (x).
y=f(x), where y = categorical output
Najlepszym przykładem algorytmu klasyfikacji ML jest Detektor spamu e-mailowego .
Głównym celem algorytmu klasyfikacji jest identyfikacja kategorii danego zbioru danych, a algorytmy te służą głównie do przewidywania wyników dla danych kategorycznych.
Algorytmy klasyfikacji można lepiej zrozumieć, korzystając z poniższego diagramu. Na poniższym schemacie znajdują się dwie klasy, klasa A i klasa B. Klasy te mają cechy podobne do siebie i odmienne od innych klas.
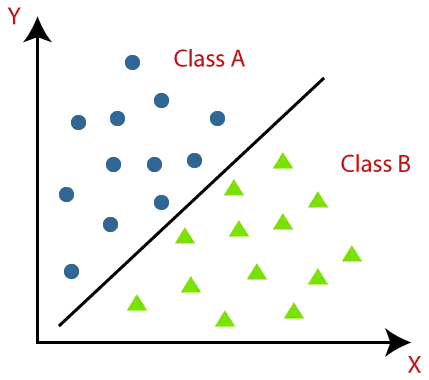
Algorytm implementujący klasyfikację zbioru danych nazywany jest klasyfikatorem. Istnieją dwa rodzaje klasyfikacji:
Przykłady: TAK lub NIE, MĘŻCZYZNA lub KOBIETA, SPAM lub NIE SPAM, KOT lub PIES itp.
Przykład: Klasyfikacje rodzajów roślin uprawnych. Klasyfikacja rodzajów muzyki.
Uczniowie zajmujący się problemami klasyfikacji:
W problemach klasyfikacyjnych wyróżnia się dwa typy uczniów:
Przykład: Algorytm K-NN. Rozumowanie oparte na przypadkach
Rodzaje algorytmów klasyfikacji ML:
Algorytmy klasyfikacji można dalej podzielić na głównie dwie kategorie:
- Regresja logistyczna
- Wsparcie maszyn wektorowych
- K-najbliżsi sąsiedzi
- Jądro SVM
- Naiwny Bayes
- Klasyfikacja drzewa decyzyjnego
- Klasyfikacja losowego lasu
Uwaga: powyższych algorytmów nauczymy się w późniejszych rozdziałach.
Ocena modelu klasyfikacji:
Po ukończeniu naszego modelu należy ocenić jego działanie; albo jest to model klasyfikacyjny, albo regresyjny. Zatem do oceny modelu klasyfikacji mamy następujące sposoby:
1. Utrata logu lub utrata entropii krzyżowej:
- Służy do oceny wydajności klasyfikatora, którego wynikiem jest wartość prawdopodobieństwa z zakresu od 0 do 1.
- W przypadku dobrego modelu klasyfikacji binarnej wartość utraty logarytmicznej powinna być bliska 0.
- Wartość utraty logu wzrasta, jeśli wartość przewidywana odbiega od wartości rzeczywistej.
- Niższa strata logarytmiczna oznacza wyższą dokładność modelu.
- W przypadku klasyfikacji binarnej entropię krzyżową można obliczyć jako:
?(ylog(p)+(1?y)log(1?p))
Gdzie y = produkcja rzeczywista, p = produkcja przewidywana.
2. Matryca zamieszania:
- Macierz zamieszania dostarcza nam macierzy/tabeli jako danych wyjściowych i opisuje wydajność modelu.
- Nazywa się ją również macierzą błędów.
- Macierz składa się z wyników przewidywań w formie sumarycznej, która zawiera łączną liczbę przewidywań poprawnych i przewidywań błędnych. Macierz wygląda jak w poniższej tabeli:
| Rzeczywisty pozytyw | Rzeczywisty negatyw | |
|---|---|---|
| Przewidywany pozytywny | Prawdziwie pozytywny | Fałszywie pozytywny |
| Przewidywany negatywny | Fałszywie negatywny | Prawdziwy negatyw |

3. Krzywa AUC-ROC:
bash, jeśli warunek
- Krzywa ROC oznacza Krzywa charakterystyki działania odbiornika i AUC oznacza Obszar pod krzywą .
- Jest to wykres przedstawiający wydajność modelu klasyfikacji przy różnych progach.
- Aby zwizualizować działanie modelu klasyfikacji wieloklasowej, używamy krzywej AUC-ROC.
- Krzywą ROC wykreślono z TPR i FPR, gdzie TPR (częstotliwość prawdziwie dodatnia) na osi Y i FPR (częstotliwość fałszywie dodatnia) na osi X.
Przypadki użycia algorytmów klasyfikacyjnych
Algorytmy klasyfikacji mogą być stosowane w różnych miejscach. Poniżej przedstawiono kilka popularnych przypadków użycia algorytmów klasyfikacji:
- Wykrywanie spamu e-mailowego
- Rozpoznawanie mowy
- Identyfikacja komórek nowotworowych.
- Klasyfikacja leków
- Identyfikacja biometryczna itp.