W tym artykule omówimy algorytm DFS w strukturze danych. Jest to algorytm rekurencyjny przeszukujący wszystkie wierzchołki struktury danych drzewa lub wykresu. Algorytm przeszukiwania w głąb (DFS) rozpoczyna się od początkowego węzła grafu G i idzie głębiej, aż znajdziemy węzeł docelowy lub węzeł bez dzieci.
Ze względu na rekurencyjny charakter struktura danych stosu może zostać wykorzystana do implementacji algorytmu DFS. Proces wdrażania DFS jest podobny do algorytmu BFS.
Proces krok po kroku wdrażania przejścia DFS jest następujący:
- Najpierw utwórz stos z całkowitą liczbą wierzchołków grafu.
- Teraz wybierz dowolny wierzchołek jako punkt początkowy przejścia i włóż ten wierzchołek na stos.
- Następnie wypchnij nieodwiedzony wierzchołek (przylegający do wierzchołka na górze stosu) na szczyt stosu.
- Teraz powtarzaj kroki 3 i 4, aż nie będzie już żadnych wierzchołków do odwiedzenia z wierzchołka na szczycie stosu.
- Jeśli nie pozostał żaden wierzchołek, wróć i zdejmij wierzchołek ze stosu.
- Powtarzaj kroki 2, 3 i 4, aż stos będzie pusty.
Zastosowania algorytmu DFS
Zastosowania wykorzystania algorytmu DFS podano następująco:
- Do realizacji sortowania topologicznego można zastosować algorytm DFS.
- Można go użyć do znalezienia ścieżek między dwoma wierzchołkami.
- Można go również wykorzystać do wykrywania cykli na wykresie.
- Algorytm DFS jest również używany w przypadku łamigłówek z jednym rozwiązaniem.
- DFS służy do określenia, czy wykres jest dwudzielny, czy nie.
Algorytm
Krok 1: SET STATUS = 1 (stan gotowości) dla każdego węzła w G
Krok 2: Włóż węzeł początkowy A na stos i ustaw jego STATUS = 2 (stan oczekiwania)
Krok 3: Powtarzaj kroki 4 i 5, aż STOS będzie pusty
Krok 4: Otwórz górny węzeł N. Przetwórz go i ustaw jego STATUS = 3 (stan przetworzony)
maszyna skończona
Krok 5: Wciśnij na stos wszystkich sąsiadów N, którzy są w stanie gotowości (których STATUS = 1) i ustaw ich STATUS = 2 (stan oczekiwania)
[KONIEC PĘTLI]
Krok 6: WYJŚCIE
Pseudo kod
DFS(G,v) ( v is the vertex where the search starts ) Stack S := {}; ( start with an empty stack ) for each vertex u, set visited[u] := false; push S, v; while (S is not empty) do u := pop S; if (not visited[u]) then visited[u] := true; for each unvisited neighbour w of uu push S, w; end if end while END DFS() Przykład algorytmu DFS
Przyjrzyjmy się teraz działaniu algorytmu DFS na przykładzie. W poniższym przykładzie mamy graf skierowany mający 7 wierzchołków.
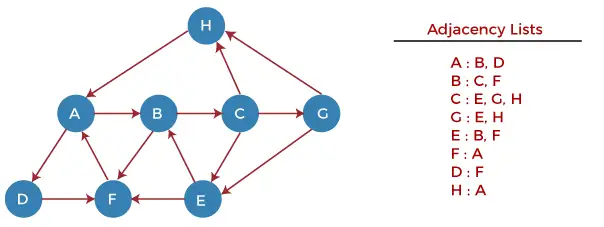
Teraz zacznijmy analizować wykres, zaczynając od węzła H.
Krok 1 - Najpierw wciśnij H na stos.
Java jest równa
STACK: H
Krok 2 - POP górny element ze stosu, czyli H, i wydrukuj go. Teraz Wciśnij wszystkich sąsiadów H na stos, którzy są w stanie gotowości.
Print: H]STACK: A
Krok 3 - POP górny element ze stosu, czyli A, i wydrukuj go. Teraz Wciśnij wszystkich sąsiadów A na stos, którzy są w stanie gotowości.
Print: A STACK: B, D
Krok 4 - POP górny element ze stosu, czyli D, i wydrukuj go. Teraz Wciśnij wszystkich sąsiadów D na stos, którzy są w stanie gotowości.
Print: D STACK: B, F
Krok 5 - POP górny element ze stosu, czyli F, i wydrukuj go. Teraz Wciśnij wszystkich sąsiadów F na stos, którzy są w stanie gotowości.
Print: F STACK: B
Krok 6 - POP górny element ze stosu, czyli B, i wydrukuj go. Teraz Wciśnij wszystkich sąsiadów B na stos, którzy są w stanie gotowości.
Print: B STACK: C
Krok 7 - POP górny element ze stosu, czyli C, i wydrukuj go. Teraz Wciśnij wszystkich sąsiadów C na stos, którzy są w stanie gotowości.
Print: C STACK: E, G
Krok 8 - POP górny element ze stosu, tj. G i PUSH wszystkich sąsiadów G na stosie, którzy są w stanie gotowości.
Print: G STACK: E
Krok 9 - POP górny element ze stosu, tj. E i PUSH wszystkich sąsiadów E na stos, którzy są w stanie gotowości.
Print: E STACK:
Teraz wszystkie węzły wykresu zostały przeszukane, a stos jest pusty.
główna metoda Java
Złożoność algorytmu przeszukiwania w głąb
Złożoność czasowa algorytmu DFS wynosi O(V+E) , gdzie V to liczba wierzchołków, a E to liczba krawędzi grafu.
Złożoność przestrzenna algorytmu DFS wynosi O (V).
Implementacja algorytmu DFS
Przyjrzyjmy się teraz implementacji algorytmu DFS w Javie.
W tym przykładzie wykres, którego używamy do zademonstrowania kodu, wygląda następująco:

/*A sample java program to implement the DFS algorithm*/ import java.util.*; class DFSTraversal { private LinkedList adj[]; /*adjacency list representation*/ private boolean visited[]; /* Creation of the graph */ DFSTraversal(int V) /*'V' is the number of vertices in the graph*/ { adj = new LinkedList[V]; visited = new boolean[V]; for (int i = 0; i <v; i++) adj[i]="new" linkedlist(); } * adding an edge to the graph void insertedge(int src, int dest) { adj[src].add(dest); dfs(int vertex) visited[vertex]="true;" *mark current node as visited* system.out.print(vertex + ' '); iterator it="adj[vertex].listIterator();" while (it.hasnext()) n="it.next();" if (!visited[n]) dfs(n); public static main(string args[]) dfstraversal dfstraversal(8); graph.insertedge(0, 1); 2); 3); graph.insertedge(1, graph.insertedge(2, 4); graph.insertedge(3, 5); 6); graph.insertedge(4, 7); graph.insertedge(5, system.out.println('depth first traversal for is:'); graph.dfs(0); < pre> <p> <strong>Output</strong> </p> <img src="//techcodeview.com/img/ds-tutorial/28/dfs-algorithm-3.webp" alt="DFS algorithm"> <h3>Conclusion</h3> <p>In this article, we have discussed the depth-first search technique, its example, complexity, and implementation in the java programming language. Along with that, we have also seen the applications of the depth-first search algorithm.</p> <p>So, that's all about the article. Hope it will be helpful and informative to you.</p> <hr></v;>