Kursor w SQL Server to d atabase, który pozwala nam pobierać każdy wiersz na raz i manipulować jego danymi . Kursor to nic innego jak wskaźnik do wiersza. Jest zawsze używane w połączeniu z instrukcją SELECT. Zwykle jest to zbiór SQL-a logika, która przechodzi przez określoną liczbę wierszy jeden po drugim. Prostą ilustracją kursora jest sytuacja, gdy mamy obszerną bazę danych pracowników i chcemy obliczyć wynagrodzenie każdego pracownika po odliczeniu podatków i urlopów.
Serwer SQL zadaniem kursora jest aktualizacja danych wiersz po wierszu, zmiana ich lub wykonanie obliczeń, które nie są możliwe, gdy pobieramy wszystkie rekordy na raz . Jest także przydatny do wykonywania zadań administracyjnych, takich jak kopie zapasowe bazy danych SQL Server w kolejności sekwencyjnej. Kursory są używane głównie w procesach programistycznych, DBA i ETL.
W tym artykule wyjaśniono wszystko na temat kursora SQL Server, takie jak cykl życia kursora, dlaczego i kiedy używany jest kursor, jak zaimplementować kursory, jego ograniczenia i jak możemy zastąpić kursor.
Cykl życia kursora
Cykl życia kursora możemy opisać w pięć różnych sekcji następująco:
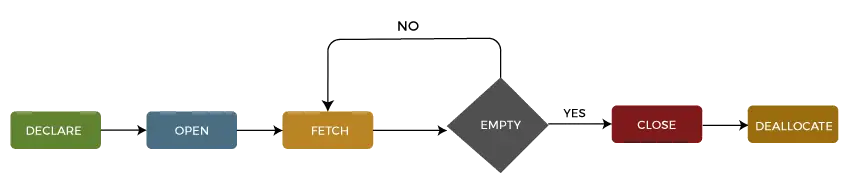
1: Zadeklaruj kursor
Pierwszym krokiem jest zadeklarowanie kursora za pomocą poniższej instrukcji SQL:
otwarty plik Java
DECLARE cursor_name CURSOR FOR select_statement;
Kursor możemy zadeklarować podając jego nazwę z typem danych CURSOR po słowie kluczowym DECLARE. Następnie napiszemy instrukcję SELECT, która definiuje wyjście dla kursora.
2: Otwórz kursor
To drugi krok, w którym otwieramy kursor w celu przechowywania danych pobranych ze zbioru wyników. Możemy to zrobić za pomocą poniższej instrukcji SQL:
OPEN cursor_name;
3: Pobierz kursor
To trzeci krok, w którym można pobierać wiersze jeden po drugim lub w bloku w celu manipulacji danymi, np. operacji wstawiania, aktualizowania i usuwania, na aktualnie aktywnym wierszu pod kursorem. Możemy to zrobić za pomocą poniższej instrukcji SQL:
FETCH NEXT FROM cursor INTO variable_list;
Możemy także skorzystać z Funkcja @@FETCHSTATUS w SQL Server, aby uzyskać status najnowszego kursora instrukcji FETCH, który został wykonany względem kursora. The APORTOWAĆ instrukcja zakończyła się pomyślnie, gdy @@FETCHSTATUS daje zerowy wynik. The CHWILA instrukcji można użyć do pobrania wszystkich rekordów z kursora. Poniższy kod wyjaśnia to jaśniej:
WHILE @@FETCH_STATUS = 0 BEGIN FETCH NEXT FROM cursor_name; END;
4: Zamknij kursor
To czwarty krok, w którym należy zamknąć kursor po zakończeniu pracy z kursorem. Możemy to zrobić za pomocą poniższej instrukcji SQL:
CLOSE cursor_name;
5: Usuń przydział kursora
Jest to piąty i ostatni krok, w którym usuniemy definicję kursora i zwolnimy wszystkie zasoby systemowe powiązane z kursorem. Możemy to zrobić za pomocą poniższej instrukcji SQL:
DEALLOCATE cursor_name;
Zastosowania kursora SQL Server
Wiemy, że systemy zarządzania relacyjnymi bazami danych, w tym SQL Server, doskonale radzą sobie z obsługą danych w zestawie wierszy zwanych zestawami wyników. Na przykład , mamy stół tabela_produktów który zawiera opisy produktów. Jeśli chcemy zaktualizować plik cena produktu, a następnie poniższe „ AKTUALIZACJA' zapytanie zaktualizuje wszystkie rekordy spełniające warunek w polu „ GDZIE' klauzula:
UPDATE product_table SET unit_price = 100 WHERE product_id = 105;
Czasami aplikacja musi przetwarzać wiersze w sposób pojedynczy, tj. wiersz po wierszu, a nie cały zestaw wyników na raz. Możemy wykonać ten proces za pomocą kursorów w SQL Server. Przed użyciem kursora musimy wiedzieć, że kursory działają bardzo słabo, dlatego należy go zawsze używać tylko wtedy, gdy nie ma innej opcji poza kursorem.
Kursor używa tej samej techniki, której używamy pętli FOREACH, FOR, WHILE, DO WHILE do iteracji po jednym obiekcie na raz we wszystkich językach programowania. Można go zatem wybrać, ponieważ stosuje tę samą logikę, co proces zapętlania języka programowania.
Rodzaje kursorów w SQL Server
Poniżej przedstawiono różne typy kursorów w programie SQL Server:
- Kursory statyczne
- Dynamiczne kursory
- Kursory tylko do przodu
- Kursory zestawu kluczy

Kursory statyczne
Zestaw wyników pokazywany przez statyczny kursor jest zawsze taki sam, jak przy pierwszym otwarciu kursora. Ponieważ kursor statyczny będzie przechowywać wynik w tempdb , oni są zawsze tylko czytać . Możemy używać kursora statycznego do poruszania się zarówno do przodu, jak i do tyłu. W przeciwieństwie do innych kursorów jest wolniejszy i zużywa więcej pamięci. Dzięki temu możemy go używać tylko wtedy, gdy konieczne jest przewijanie, a inne kursory się nie nadają.
Kursor ten pokazuje wiersze, które zostały usunięte z bazy danych po jej otwarciu. Kursor statyczny nie reprezentuje żadnych operacji INSERT, UPDATE ani DELETE (chyba że kursor zostanie zamknięty i ponownie otwarty).
Dynamiczne kursory
Kursory dynamiczne są przeciwieństwem kursorów statycznych, które pozwalają nam wykonywać operacje aktualizacji, usuwania i wstawiania danych, gdy kursor jest otwarty. To jest domyślnie przewijane . Może wykryć wszystkie zmiany wprowadzone w wierszach, kolejności i wartościach w zestawie wyników, niezależnie od tego, czy zmiany zachodzą wewnątrz kursora, czy poza nim. Poza kursorem nie możemy zobaczyć aktualizacji, dopóki nie zostaną zatwierdzone.
Kursory tylko do przodu
Jest to domyślny i najszybszy typ kursora spośród wszystkich kursorów. Nazywa się go kursorem tylko do przodu, ponieważ tak jest przesuwa się tylko do przodu w zestawie wyników . Ten kursor nie obsługuje przewijania. Może pobierać tylko wiersze od początku do końca zestawu wyników. Pozwala nam wykonywać operacje wstawiania, aktualizowania i usuwania. Tutaj efekt operacji wstawiania, aktualizacji i usuwania wykonanych przez użytkownika, które wpływają na wiersze w zestawie wynikowym, jest widoczny podczas pobierania wierszy od kursora. Po pobraniu wiersza nie możemy zobaczyć zmian wprowadzonych w wierszach za pomocą kursora.
Kursory tylko do przodu dzielą się na trzy typy:
- Zestaw kluczy Forward_Only
- Forward_Only Statyczne
- Fast_Forward

Kursory sterowane zestawem kluczy
Ta funkcjonalność kursora leży pomiędzy kursorem statycznym i dynamicznym dotyczące jego zdolności do wykrywania zmian. Nie zawsze może wykryć zmiany w członkostwie i porządku zestawu wyników jak statyczny kursor. Może wykrywać zmiany w wartościach wierszy zestawu wyników niczym dynamiczny kursor. Może tylko przejdź od pierwszego do ostatniego i ostatniego do pierwszego rzędu . Kolejność i członkostwo są stałe przy każdym otwarciu tego kursora.
Obsługiwany jest za pomocą zestawu unikalnych identyfikatorów, takich samych jak klucze w zestawie kluczy. Zestaw kluczy jest określony przez wszystkie wiersze, które kwalifikowały instrukcję SELECT przy pierwszym otwarciu kursora. Potrafi także wykryć wszelkie zmiany w źródle danych, co wspiera operacje aktualizacji i usuwania. Domyślnie można go przewijać.
Implementacja przykładu
Zaimplementujmy przykład kursora na serwerze SQL. Możemy to zrobić, tworząc najpierw tabelę o nazwie „ klient ' używając poniższej instrukcji:
jak otworzyć plik w Javie
CREATE TABLE customer ( id int PRIMARY KEY, c_name nvarchar(45) NOT NULL, email nvarchar(45) NOT NULL, city nvarchar(25) NOT NULL );
Następnie wstawimy wartości do tabeli. Możemy wykonać poniższą instrukcję, aby dodać dane do tabeli:
INSERT INTO customer (id, c_name, email, city) VALUES (1,'Steffen', '[email protected]', 'Texas'), (2, 'Joseph', '[email protected]', 'Alaska'), (3, 'Peter', '[email protected]', 'California'), (4,'Donald', '[email protected]', 'New York'), (5, 'Kevin', '[email protected]', 'Florida'), (6, 'Marielia', '[email protected]', 'Arizona'), (7,'Antonio', '[email protected]', 'New York'), (8, 'Diego', '[email protected]', 'California');
Dane możemy zweryfikować wykonując polecenie WYBIERAĆ oświadczenie:
SELECT * FROM customer;
Po wykonaniu zapytania możemy zobaczyć poniższe dane wyjściowe, w których mamy osiem rzędów do tabeli:

Teraz utworzymy kursor, aby wyświetlić rekordy klientów. Poniższe fragmenty kodu wyjaśniają wszystkie etapy deklaracji lub tworzenia kursora, łącząc wszystko w całość:
metody Javy
--Declare the variables for holding data. DECLARE @id INT, @c_name NVARCHAR(50), @city NVARCHAR(50) --Declare and set counter. DECLARE @Counter INT SET @Counter = 1 --Declare a cursor DECLARE PrintCustomers CURSOR FOR SELECT id, c_name, city FROM customer --Open cursor OPEN PrintCustomers --Fetch the record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city --LOOP UNTIL RECORDS ARE AVAILABLE. WHILE @@FETCH_STATUS = 0 BEGIN IF @Counter = 1 BEGIN PRINT 'id' + CHAR(9) + 'c_name' + CHAR(9) + CHAR(9) + 'city' PRINT '--------------------------' END --Print the current record PRINT CAST(@id AS NVARCHAR(10)) + CHAR(9) + @c_name + CHAR(9) + CHAR(9) + @city --Increment the counter variable SET @Counter = @Counter + 1 --Fetch the next record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city END --Close the cursor CLOSE PrintCustomers --Deallocate the cursor DEALLOCATE PrintCustomers
Po uruchomieniu kursora otrzymamy poniższy wynik:

Ograniczenia kursora SQL Server
Kursor ma pewne ograniczenia, dlatego powinien być zawsze używany tylko wtedy, gdy nie ma innej opcji poza kursorem. Te ograniczenia to:
- Kursor zużywa zasoby sieciowe, wymagając połączenia sieciowego za każdym razem, gdy pobiera rekord.
- Kursor to rezydujący w pamięci zestaw wskaźników, co oznacza, że zajmuje trochę pamięci, którą inne procesy mogłyby wykorzystać na naszym komputerze.
- Nakłada blokady na część tabeli lub całą tabelę podczas przetwarzania danych.
- Wydajność i szybkość kursora są wolniejsze, ponieważ rekordy tabeli aktualizują się po jednym wierszu na raz.
- Kursory są szybsze niż pętle while, ale wiążą się z większym obciążeniem.
- Liczba wierszy i kolumn przeniesionych do kursora to kolejny aspekt wpływający na szybkość kursora. Odnosi się do czasu potrzebnego na otwarcie kursora i wykonanie instrukcji pobierania.
Jak możemy uniknąć kursorów?
Głównym zadaniem kursorów jest poruszanie się po tabeli wiersz po wierszu. Poniżej podano najprostszy sposób uniknięcia kursorów:
Korzystanie z pętli while SQL
Najłatwiejszym sposobem uniknięcia użycia kursora jest użycie pętli while, która umożliwia wstawienie zestawu wyników do tabeli tymczasowej.
Funkcje zdefiniowane przez użytkownika
Czasami do obliczenia wynikowego zestawu wierszy używa się kursorów. Możemy to osiągnąć za pomocą funkcji zdefiniowanej przez użytkownika, która spełnia wymagania.
Korzystanie z złączeń
Łączenie przetwarza tylko te kolumny, które spełniają określony warunek, zmniejszając w ten sposób liczbę wierszy kodu, które zapewniają większą wydajność niż kursory w przypadku konieczności przetworzenia dużych rekordów.