Uczenie się nadzorowane i bez nadzoru to dwie techniki uczenia maszynowego. Obie techniki są jednak stosowane w różnych scenariuszach i przy różnych zbiorach danych. Poniżej podano wyjaśnienie obu metod uczenia się wraz z tabelą różnic.
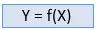
Nadzorowane uczenie maszynowe:
Uczenie nadzorowane to metoda uczenia maszynowego, w ramach której modele są szkolone przy użyciu oznaczonych etykietami danych. W uczeniu nadzorowanym modele muszą znaleźć funkcję mapującą, aby odwzorować zmienną wejściową (X) na zmienną wyjściową (Y).
zmień programowanie w Javie
Uczenie się pod nadzorem wymaga nadzoru, aby wytrenować model, co przypomina sytuację, w której uczeń uczy się rzeczy w obecności nauczyciela. Uczenie się pod nadzorem można zastosować w przypadku dwóch rodzajów problemów: Klasyfikacja I Regresja .
Ucz się więcej Nadzorowane uczenie maszynowe
Przykład: Załóżmy, że mamy obraz różnych rodzajów owoców. Zadaniem naszego modelu uczenia się z nadzorem jest identyfikacja owoców i odpowiednia ich klasyfikacja. Aby więc zidentyfikować obraz w uczeniu nadzorowanym, podamy dane wejściowe i wyjściowe, co oznacza, że będziemy trenować model na podstawie kształtu, rozmiaru, koloru i smaku każdego owocu. Po zakończeniu szkolenia przetestujemy model podając nowy zestaw owoców. Model zidentyfikuje owoc i przewidzi wynik za pomocą odpowiedniego algorytmu.
Uczenie maszynowe bez nadzoru:
Uczenie się bez nadzoru to kolejna metoda uczenia maszynowego, w której wzorce są wyciągane z nieoznaczonych danych wejściowych. Celem uczenia się bez nadzoru jest znalezienie struktury i wzorców na podstawie danych wejściowych. Uczenie się bez nadzoru nie wymaga żadnego nadzoru. Zamiast tego samodzielnie znajduje wzorce na podstawie danych.
Ucz się więcej Uczenie maszynowe bez nadzoru
Uczenie się bez nadzoru można zastosować w przypadku dwóch rodzajów problemów: Grupowanie I Stowarzyszenie .
Przykład: Aby zrozumieć uczenie się bez nadzoru, posłużymy się przykładem podanym powyżej. Zatem w przeciwieństwie do uczenia się pod nadzorem, tutaj nie będziemy zapewniać żadnego nadzoru nad modelem. Po prostu dostarczymy wejściowy zbiór danych do modelu i pozwolimy modelowi znaleźć wzorce na podstawie danych. Za pomocą odpowiedniego algorytmu model sam się nauczy i podzieli owoce na różne grupy według najbardziej podobnych cech między nimi.
Główne różnice między uczeniem się pod nadzorem i bez nadzoru podano poniżej:
jednorodna mieszanina
| Nadzorowana nauka | Uczenie się bez nadzoru |
|---|---|
| Algorytmy uczenia się nadzorowanego są szkolone przy użyciu oznakowanych danych. | Algorytmy uczenia się bez nadzoru są szkolone przy użyciu nieoznaczonych danych. |
| Model uczenia się nadzorowanego wykorzystuje bezpośrednią informację zwrotną, aby sprawdzić, czy przewiduje prawidłowe wyniki, czy nie. | Model uczenia się bez nadzoru nie przyjmuje żadnych informacji zwrotnych. |
| Model uczenia się nadzorowanego przewiduje wyniki. | Model uczenia się bez nadzoru znajduje ukryte wzorce w danych. |
| W uczeniu nadzorowanym dane wejściowe są dostarczane do modelu wraz z danymi wyjściowymi. | W przypadku uczenia się bez nadzoru do modelu dostarczane są jedynie dane wejściowe. |
| Celem uczenia się nadzorowanego jest wyszkolenie modelu tak, aby mógł przewidzieć wynik, gdy otrzyma nowe dane. | Celem uczenia się bez nadzoru jest znalezienie ukrytych wzorców i przydatnych spostrzeżeń z nieznanego zbioru danych. |
| Uczenie się nadzorowane wymaga nadzoru, aby wytrenować model. | Uczenie się bez nadzoru nie wymaga żadnego nadzoru do szkolenia modelu. |
| Uczenie się pod nadzorem można podzielić na: Klasyfikacja I Regresja problemy. | Uczenie się bez nadzoru można podzielić na: Grupowanie I Wspomnienia problemy. |
| Uczenie nadzorowane można zastosować w przypadkach, gdy znamy dane wejściowe i odpowiadające im wyniki. | Uczenie się bez nadzoru można zastosować w przypadkach, gdy mamy tylko dane wejściowe i nie mamy odpowiednich danych wyjściowych. |
| Model uczenia się nadzorowanego zapewnia dokładny wynik. | Model uczenia się bez nadzoru może dawać mniej dokładne wyniki w porównaniu z uczeniem się pod nadzorem. |
| Uczenie nadzorowane nie jest bliskie prawdziwej sztucznej inteligencji, ponieważ w tym przypadku najpierw trenujemy model dla poszczególnych danych, a dopiero potem on może przewidzieć prawidłowy wynik. | Uczenie się bez nadzoru jest bliższe prawdziwej sztucznej inteligencji, ponieważ uczy się podobnie, jak dziecko uczy się codziennych rutynowych rzeczy na podstawie swoich doświadczeń. |
| Zawiera różne algorytmy, takie jak regresja liniowa, regresja logistyczna, maszyna wektorów nośnych, klasyfikacja wieloklasowa, drzewo decyzyjne, logika bayesowska itp. | Zawiera różne algorytmy, takie jak klastrowanie, KNN i algorytm Apriori. |