BERT, skrót dla dwukierunkowych reprezentacji enkoderów z transformatorów , oznacza oprogramowanie typu open source ramy uczenia maszynowego przeznaczone dla sfery przetwarzanie języka naturalnego (NLP) . Platforma ta, powstała w 2018 roku, została stworzona przez badaczy z Google AI Language. Celem artykułu jest zbadanie architektura, działanie i zastosowania BERT .
Co to jest BERT?
BERT (Dwukierunkowe reprezentacje enkodera z transformatorów) wykorzystuje sieć neuronową opartą na transformatorze do zrozumienia i generowania języka podobnego do ludzkiego. BERT wykorzystuje architekturę składającą się wyłącznie z enkodera. W orginale Architektura transformatorowa istnieją moduły kodera i dekodera. Decyzja o zastosowaniu w BERT architektury składającej się wyłącznie z kodera sugeruje położenie głównego nacisku na zrozumienie sekwencji wejściowych, a nie generowanie sekwencji wyjściowych.
Dwukierunkowe podejście BERT
Tradycyjne modele językowe przetwarzają tekst sekwencyjnie, od lewej do prawej lub od prawej do lewej. Metoda ta ogranicza świadomość modelu do bezpośredniego kontekstu poprzedzającego słowo docelowe. BERT stosuje podejście dwukierunkowe, biorąc pod uwagę zarówno lewy, jak i prawy kontekst słów w zdaniu, zamiast analizować tekst sekwencyjnie, BERT przygląda się wszystkim słowom w zdaniu jednocześnie.
Przykład: Brzeg położony jest nad _______ rzeką.
W modelu jednokierunkowym zrozumienie pustego miejsca w dużym stopniu zależy od poprzednich słów, a model może mieć trudności z rozróżnieniem, czy bank odnosi się do instytucji finansowej, czy do brzegu rzeki.
BERT, będąc dwukierunkowym, uwzględnia jednocześnie lewy (położony nad brzegiem) i prawy kontekst (rzeki), umożliwiając bardziej zniuansowane zrozumienie. Rozumie, że brakujące słowo jest prawdopodobnie związane z lokalizacją geograficzną banku, co pokazuje bogactwo kontekstowe, jakie niesie ze sobą podejście dwukierunkowe.
Szkolenie wstępne i dostrajanie
Model BERT przechodzi dwuetapowy proces:
- Szkolenie wstępne dotyczące dużych ilości tekstu bez etykiet w celu nauczenia się osadzania kontekstowego.
- Dostrajanie oznaczonych danych pod kątem konkretnych NLP zadania.
Szkolenie wstępne na dużych zbiorach danych
- BERT jest wstępnie przeszkolony na dużej ilości nieoznaczonych danych tekstowych. Model uczy się osadzania kontekstowego, czyli reprezentacji słów uwzględniających otaczający je kontekst w zdaniu.
- BERT angażuje się w różne zadania przedszkoleniowe bez nadzoru. Na przykład może nauczyć się przewidywać brakujące słowa w zdaniu (model języka maskowanego lub zadanie MLM), rozumieć związek między dwoma zdaniami lub przewidywać następne zdanie w parze.
Dostrajanie oznaczonych danych
- Po fazie wstępnego szkolenia model BERT, wyposażony w osadzania kontekstowe, jest następnie dostrajany pod kątem konkretnych zadań przetwarzania języka naturalnego (NLP). Ten krok dostosowuje model do bardziej ukierunkowanych zastosowań, dostosowując jego ogólne zrozumienie języka do niuansów konkretnego zadania.
- BERT jest dostrajany przy użyciu oznaczonych danych specyficznych dla dalszych zadań będących przedmiotem zainteresowania. Zadania te mogą obejmować analizę nastrojów, odpowiadanie na pytania, rozpoznawanie nazwanych podmiotów lub jakakolwiek inna aplikacja NLP. Parametry modelu są dostosowywane tak, aby zoptymalizować jego działanie pod kątem konkretnych wymagań stawianego zadania.
Ujednolicona architektura BERT pozwala mu dostosować się do różnych dalszych zadań przy minimalnych modyfikacjach, co czyni go wszechstronnym i wysoce skutecznym narzędziem w rozumienie języka naturalnego i przetwarzanie.
Jak działa BERT?
BERT jest przeznaczony do generowania modelu językowego, dlatego wykorzystywany jest jedynie mechanizm kodujący. Sekwencja tokenów jest podawana do kodera Transformera. Tokeny te są najpierw osadzane w wektorach, a następnie przetwarzane w sieci neuronowej. Dane wyjściowe to sekwencja wektorów, każdy odpowiadający tokenowi wejściowemu, zapewniający reprezentacje kontekstowe.
Podczas uczenia modeli językowych wyzwaniem jest zdefiniowanie celu przewidywania. Wiele modeli przewiduje następne słowo w sekwencji, co jest podejściem kierunkowym i może ograniczać uczenie się kontekstu. BERT stawia czoła temu wyzwaniu dzięki dwóm innowacyjnym strategiom szkoleniowym:
- Model języka zamaskowanego (MLM)
- Przewidywanie następnego zdania (NSP)
1. Model języka zamaskowanego (MLM)
W procesie wstępnego uczenia BERT część słów w każdej sekwencji wejściowej jest maskowana, a model jest szkolony w zakresie przewidywania oryginalnych wartości tych zamaskowanych słów na podstawie kontekstu zapewnianego przez otaczające słowa.
W prostych słowach,
- Słowa maskujące: Zanim BERT nauczy się ze zdań, ukrywa niektóre słowa (około 15%) i zastępuje je specjalnym symbolem, np. [MASKA].
- Odgadywanie ukrytych słów: Zadaniem BERT-a jest odgadnięcie, co to za ukryte słowa, patrząc na słowa wokół nich. To jak gra w zgadywanie, w której brakuje niektórych słów, a BERT próbuje wypełnić luki.
- Jak BERT uczy się:
- BERT dodaje specjalną warstwę do swojego systemu uczenia się, aby móc zgadywać. Następnie sprawdza, jak blisko jego domysłów są rzeczywiste ukryte słowa.
- Robi to poprzez zamianę swoich domysłów na prawdopodobieństwa, mówiąc: Myślę, że to słowo to X i jestem tego całkowicie pewien.
- Szczególna uwaga na ukryte słowa
- Podczas szkolenia BERT skupia się głównie na poprawnym korygowaniu ukrytych słów. Mniej przejmuje się przewidywaniem słów, które nie są ukryte.
- Dzieje się tak, ponieważ prawdziwym wyzwaniem jest znalezienie brakujących części, a ta strategia pomaga BERTowi naprawdę dobrze rozumieć znaczenie i kontekst słów.
Pod względem technicznym
- BERT dodaje warstwę klasyfikacyjną do sygnału wyjściowego kodera. Warstwa ta jest kluczowa dla przewidywania zamaskowanych słów.
- Wektory wyjściowe z warstwy klasyfikacyjnej są mnożone przez macierz osadzania, przekształcając je w wymiar słownictwa. Ten krok pomaga dopasować przewidywane reprezentacje do przestrzeni słownictwa.
- Prawdopodobieństwo każdego słowa w słowniku jest obliczane za pomocą Funkcja aktywacji SoftMax . Ten krok generuje rozkład prawdopodobieństwa dla całego słownika dla każdej zamaskowanej pozycji.
- Funkcja straty używana podczas uczenia uwzględnia jedynie przewidywanie wartości zamaskowanych. Model jest karany za odchylenie pomiędzy swoimi przewidywaniami a rzeczywistymi wartościami maskowanych słów.
- Model zbiega się wolniej niż modele kierunkowe. Dzieje się tak dlatego, że podczas szkolenia BERT zajmuje się jedynie przewidywaniem wartości zamaskowanych, ignorując przewidywanie słów niezamaskowanych. Zwiększona świadomość kontekstu osiągnięta dzięki tej strategii kompensuje wolniejszą zbieżność.
2. Przewidywanie następnego zdania (NSP)
BERT przewiduje, czy drugie zdanie jest powiązane z pierwszym. Odbywa się to poprzez przekształcenie danych wyjściowych tokena [CLS] na wektor w kształcie 2×1 przy użyciu warstwy klasyfikacyjnej, a następnie obliczenie prawdopodobieństwa tego, czy drugie zdanie następuje po pierwszym przy użyciu SoftMax.
- W procesie szkoleniowym BERT uczy się rozumieć związek między parami zdań, przewidując, czy drugie zdanie następuje po pierwszym w oryginalnym dokumencie.
- W przypadku 50% par wejściowych drugie zdanie jest kolejnym zdaniem w dokumencie oryginalnym, a pozostałe 50% ma zdanie wybrane losowo.
- Aby pomóc modelowi rozróżnić połączone i rozłączone pary zdań. Dane wejściowe są przetwarzane przed wejściem do modelu:
- Token [CLS] jest wstawiany na początku pierwszego zdania, a token [SEP] na końcu każdego zdania.
- Do każdego tokena dodawane jest osadzenie zdania wskazujące Zdanie A lub Zdanie B.
- Osadzenie pozycyjne wskazuje pozycję każdego żetonu w sekwencji.
- BERT przewiduje, czy drugie zdanie jest powiązane z pierwszym. Odbywa się to poprzez przekształcenie danych wyjściowych tokena [CLS] na wektor w kształcie 2×1 przy użyciu warstwy klasyfikacyjnej, a następnie obliczenie prawdopodobieństwa tego, czy drugie zdanie następuje po pierwszym przy użyciu SoftMax.
Podczas uczenia modelu BERT, zamaskowane LM i przewidywanie następnego zdania są trenowane razem. Model ma na celu zminimalizowanie połączonej funkcji straty maskowanego LM i przewidywania następnego zdania, co prowadzi do solidnego modelu językowego o zwiększonych możliwościach rozumienia kontekstu w zdaniach i relacji między zdaniami.
Dlaczego warto razem trenować Masked LM i Przewidywanie następnego zdania?
Zamaskowany LM pomaga BERTowi zrozumieć kontekst zdania i Przewidywanie następnego zdania pomaga BERTowi zrozumieć związek lub relację między parami zdań. Zatem wspólne szkolenie obu strategii gwarantuje, że BERT nauczy się szerokiego i wszechstronnego rozumienia języka, wychwytując zarówno szczegóły w zdaniach, jak i przepływ między zdaniami.
Architektury BERT
Architektura BERT to wielowarstwowy dwukierunkowy koder transformatorowy, który jest dość podobny do modelu transformatora. Architektura transformatora to sieć kodera-dekodera, która wykorzystuje samouważność po stronie kodera i uwaga po stronie dekodera.
- BERTBAZAma 1 2 warstwy w stosie kodera podczas BERTDUŻYma 24 warstwy w stosie kodera . To więcej niż architektura Transformera opisana w artykule oryginalnym ( 6 warstw kodera ).
- Architektury BERT (BASE i LARGE) mają również większe sieci ze sprzężeniem zwrotnym (odpowiednio 768 i 1024 jednostki ukryte) oraz więcej głów uwagi (odpowiednio 12 i 16) niż architektura Transformera sugerowana w oryginalnej pracy. Zawiera 512 ukrytych jednostek i 8 głów uwagi .
- BERTBAZAzawiera 110M parametrów, podczas gdy BERTDUŻYma parametry 340M.

Architektura BERT BASE i BERT LARGE.
Ten model przyjmuje CLS token jako dane wejściowe, następnie następuje sekwencja słów jako dane wejściowe. Tutaj CLS jest tokenem klasyfikacji. Następnie przekazuje dane wejściowe do powyższych warstw. Każda warstwa ma zastosowanie samouważność i przekazuje wynik przez sieć ze sprzężeniem zwrotnym, a następnie przekazuje go do następnego kodera. Model wyprowadza wektor o ukrytym rozmiarze ( 768 dla BERT BASE). Jeśli chcemy wyprowadzić klasyfikator z tego modelu, możemy pobrać dane wyjściowe odpowiadające tokenowi CLS.
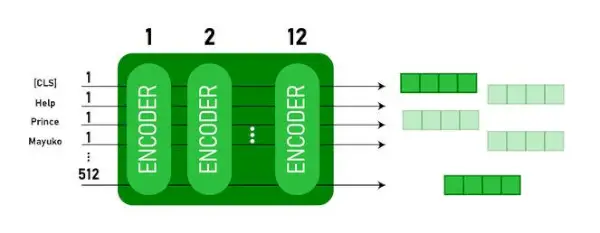
Dane wyjściowe BERT jako osadzenia
Teraz tego wyuczonego wektora można używać do wykonywania szeregu zadań, takich jak klasyfikacja, tłumaczenie itp. Na przykład papier osiąga świetne wyniki już przy użyciu pojedynczej warstwy Sieć neuronowa na modelu BERT w zadaniu klasyfikacyjnym.
Jak wykorzystać model BERT w NLP?
BERT może być używany do różnych zadań związanych z przetwarzaniem języka naturalnego (NLP), takich jak:
1. Zadanie klasyfikacyjne
- BERT może być używany do zadań klasyfikacyjnych, takich jak analiza nastrojów celem jest sklasyfikowanie tekstu w różnych kategoriach (pozytywny/negatywny/neutralny), BERT można zastosować, dodając warstwę klasyfikacyjną na górze wyjścia transformatora dla tokena [CLS].
- Token [CLS] reprezentuje zagregowaną informację z całej sekwencji wejściowej. Tę zbiorczą reprezentację można następnie wykorzystać jako dane wejściowe dla warstwy klasyfikacyjnej w celu opracowania prognoz dla konkretnego zadania.
2. Odpowiadanie na pytania
- W zadaniach odpowiadania na pytania, gdzie model ma zlokalizować i zaznaczyć odpowiedź w zadanym ciągu tekstowym, można w tym celu przeszkolić BERT.
- BERT jest szkolony w zakresie odpowiadania na pytania poprzez uczenie się dwóch dodatkowych wektorów oznaczających początek i koniec odpowiedzi. Podczas szkolenia model otrzymuje pytania i odpowiadające im fragmenty, a także uczy się przewidywać pozycję początkową i końcową odpowiedzi w danym fragmencie.
3. Rozpoznawanie podmiotów nazwanych (NER)
- BERT można wykorzystać w NER, gdzie celem jest identyfikacja i klasyfikacja podmiotów (np. Osoba, Organizacja, Data) w sekwencji tekstowej.
- Model NER oparty na BERT jest szkolony poprzez pobranie wektora wyjściowego każdego tokena z Transformatora i wprowadzenie go do warstwy klasyfikacyjnej. Warstwa przewiduje etykietę nazwanej jednostki dla każdego tokenu, wskazując typ jednostki, którą reprezentuje.
Jak tokenizować i kodować tekst za pomocą BERT?
Aby tokenizować i kodować tekst za pomocą BERT, będziemy korzystać z biblioteki „transformer” w Pythonie.
Polecenie instalacji transformatorów:
!pip install transformers>
- Załadujemy wstępnie wyszkolony tokenize BERT za pomocą słownictwa w obudowach BertTokenizer.from_pretrained(bert-base-cased) .
- tokenizer.encode(tekst) tokenizuje tekst wejściowy i konwertuje go na sekwencję identyfikatorów tokenów.
- print(Identyfikatory tokenów:, kodowanie) drukuje identyfikatory tokenów uzyskane po zakodowaniu.
- tokenizer.convert_ids_to_tokens(kodowanie) konwertuje identyfikatory tokenów z powrotem na odpowiadające im tokeny.
- print(Tokeny:, tokeny) drukuje tokeny uzyskane po konwersji identyfikatorów tokenów
Python3
from> transformers>import> BertTokenizer> # Load pre-trained BERT tokenizer> tokenizer>=> BertTokenizer.from_pretrained(>'bert-base-cased'>)> # Input text> text>=> 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '> # Tokenize and encode the text> encoding>=> tokenizer.encode(text)> # Print the token IDs> print>(>'Token IDs:'>, encoding)> # Convert token IDs back to tokens> tokens>=> tokenizer.convert_ids_to_tokens(encoding)> # Print the corresponding tokens> print>(>'Tokens:'>, tokens)> |
>
>
Wyjście:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102] Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']> The tokenizer.encode metoda dodaje dodatek specjalny [CLS] – klasyfikacja I [SEP] – separator tokeny na początku i na końcu zakodowanej sekwencji.
Zastosowanie BERT
BERT służy do:
- Reprezentacja tekstu: BERT służy do generowania osadzania słów lub reprezentacji słów w zdaniu.
- Rozpoznawanie nazwanych podmiotów (NER) : BERT można dostosować do zadań rozpoznawania nazwanych podmiotów, których celem jest identyfikacja w danym tekście podmiotów, takich jak nazwiska osób, organizacje, lokalizacje itp.
- Klasyfikacja tekstu: BERT jest szeroko stosowany do zadań związanych z klasyfikacją tekstu, w tym do analizy nastrojów, wykrywania spamu i kategoryzacji tematów. Wykazał się doskonałą wydajnością w rozumieniu i klasyfikowaniu kontekstu danych tekstowych.
- Systemy odpowiadania na pytania: BERT zastosowano w systemach odpowiadania na pytania, gdzie model jest szkolony w zakresie rozumienia kontekstu pytania i udzielania odpowiednich odpowiedzi. Jest to szczególnie przydatne w przypadku zadań takich jak czytanie ze zrozumieniem.
- Tłumaczenie maszynowe: Osadzanie kontekstowe BERT można wykorzystać do ulepszenia systemów tłumaczenia maszynowego. Model oddaje niuanse językowe, które są kluczowe dla dokładnego tłumaczenia.
- Podsumowanie tekstu: BERT można wykorzystać do abstrakcyjnego podsumowania tekstu, gdzie model generuje zwięzłe i znaczące streszczenia dłuższych tekstów poprzez zrozumienie kontekstu i semantyki.
- Konwersacyjna sztuczna inteligencja: BERT zajmuje się budowaniem konwersacyjnych systemów AI, takich jak chatboty, wirtualni asystenci i systemy dialogowe. Jego zdolność do uchwycenia kontekstu sprawia, że jest skuteczny w rozumieniu i generowaniu odpowiedzi w języku naturalnym.
- Podobieństwo semantyczne: Osadzania BERT można wykorzystać do pomiaru podobieństwa semantycznego między zdaniami lub dokumentami. Jest to przydatne w zadaniach takich jak wykrywanie duplikatów, identyfikacja parafraz i wyszukiwanie informacji.
BERT kontra GPT
Różnica między BERT i GPT jest następująca:
| BERT | GPT | |
|---|---|---|
| Architektura | BERT jest przeznaczony do dwukierunkowego uczenia się reprezentacji. Wykorzystuje cel modelu języka zamaskowanego, w którym przewiduje brakujące słowa w zdaniu na podstawie lewego i prawego kontekstu. | Z kolei GPT jest przeznaczony do generatywnego modelowania języka. Przewiduje następne słowo w zdaniu, biorąc pod uwagę poprzedni kontekst, wykorzystując jednokierunkowe podejście autoregresyjne. |
| Cele przedszkoleniowe | BERT jest wstępnie szkolony przy użyciu celu modelu zamaskowanego języka i przewidywania następnego zdania. Koncentruje się na uchwyceniu dwukierunkowego kontekstu i zrozumieniu relacji między słowami w zdaniu. | GPT jest wstępnie przeszkolony do przewidywania następnego słowa w zdaniu, co zachęca model do uczenia się spójnej reprezentacji języka i generowania sekwencji odpowiednich kontekstowo. |
| Zrozumienie kontekstu | BERT jest skuteczny w przypadku zadań wymagających głębokiego zrozumienia kontekstu i relacji w zdaniu, takich jak klasyfikacja tekstu, rozpoznawanie nazwanych podmiotów i odpowiadanie na pytania. | GPT świetnie radzi sobie z generowaniem spójnego i kontekstowo odpowiedniego tekstu. Jest często stosowany w zadaniach twórczych, systemach dialogowych i zadaniach wymagających generowania sekwencji języka naturalnego. |
| Typy zadań i przypadki użycia
| Powszechnie używane w zadaniach takich jak klasyfikacja tekstu, rozpoznawanie nazwanych jednostek, analiza tonacji i odpowiadanie na pytania. | Stosowane do zadań takich jak generowanie tekstu, systemy dialogów, podsumowania i kreatywne pisanie. |
| Dostrajanie a uczenie się kilkoma strzałami | BERT jest często dostosowywany do konkretnych dalszych zadań za pomocą oznaczonych danych, aby dostosować swoje wstępnie wytrenowane reprezentacje do bieżącego zadania. | GPT zaprojektowano do wykonywania kilkuetapowego uczenia się, podczas którego można go uogólniać na nowe zadania przy minimalnych danych szkoleniowych dotyczących konkretnego zadania. |
Sprawdź także:
- Klasyfikacja nastrojów za pomocą BERT
- Jak wygenerować osadzanie słów za pomocą BERT?
- Model BART automatycznego uzupełniania tekstu w NLP
- Klasyfikacja komentarzy toksycznych przy użyciu BERT
- Przewidywanie następnego zdania za pomocą BERT
Często zadawane pytania (FAQ)
P. Do czego służy BERT?
BERT służy do wykonywania zadań NLP, takich jak reprezentacja tekstu, rozpoznawanie nazwanych jednostek, klasyfikacja tekstu, systemy pytań i odpowiedzi, tłumaczenie maszynowe, podsumowywanie tekstu i nie tylko.
P. Jakie są zalety modelu BERT?
Model językowy BERT wyróżnia się obszernym szkoleniem wstępnym w wielu językach, oferującym szeroki zakres językowy w porównaniu z innymi modelami. To sprawia, że BERT jest szczególnie korzystny w przypadku projektów innych niż angielski, ponieważ zapewnia solidne reprezentacje kontekstowe i zrozumienie semantyczne w różnorodnych językach, zwiększając jego wszechstronność w zastosowaniach wielojęzycznych.
P. W jaki sposób BERT sprawdza się w analizie nastrojów?
BERT przoduje w analizie nastrojów, wykorzystując swoją dwukierunkową naukę reprezentacji do wychwytywania niuansów kontekstowych, znaczeń semantycznych i struktur składniowych w danym tekście. Umożliwia to BERT zrozumienie nastrojów wyrażonych w zdaniu poprzez rozważenie relacji między słowami, co skutkuje bardzo skutecznymi wynikami analizy nastrojów.
synchronizacja Java
P. Czy Google opiera się na BERT?
BERT I RangaBrain to elementy algorytmu wyszukiwania Google służące do przetwarzania zapytań i zawartości stron internetowych w celu lepszego zrozumienia i poprawy wyników wyszukiwania.