Poniższa architektura wyjaśnia przepływ przesyłania zapytania do Hive.
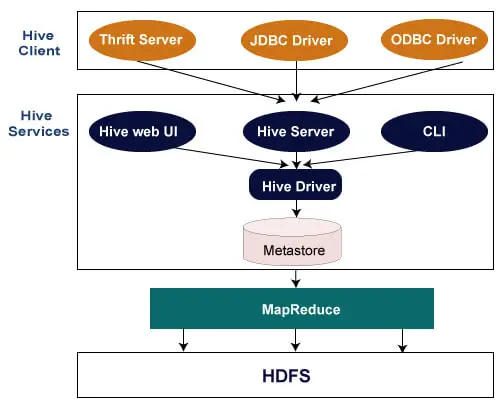
Klient Hive
Hive umożliwia pisanie aplikacji w różnych językach, w tym Java, Python i C++. Obsługuje różne typy klientów, takie jak: -
- Thrift Server — jest to wielojęzyczna platforma dostawców usług obsługująca żądania ze wszystkich języków programowania obsługujących Thrift.
- Sterownik JDBC - służy do nawiązania połączenia pomiędzy aplikacjami Hive i Java. Sterownik JDBC występuje w klasie org.apache.hadoop.hive.jdbc.HiveDriver.
- Sterownik ODBC - umożliwia aplikacjom obsługującym protokół ODBC łączenie się z Hive.
Usługi ula
Poniżej znajdują się usługi świadczone przez Hive: -
- Hive CLI — Hive CLI (interfejs wiersza poleceń) to powłoka, w której możemy wykonywać zapytania i polecenia Hive.
- Sieciowy interfejs użytkownika Hive — internetowy interfejs użytkownika Hive jest po prostu alternatywą dla interfejsu wiersza polecenia Hive. Zapewnia internetowy interfejs GUI do wykonywania zapytań i poleceń Hive.
- Hive MetaStore - Jest to centralne repozytorium przechowujące wszystkie informacje o strukturze różnych tabel i partycji w magazynie. Zawiera także metadane kolumny i informacje o jej typie, serializatory i deserializatory używane do odczytu i zapisu danych oraz odpowiednie pliki HDFS, w których przechowywane są dane.
- Serwer Hive — nazywany jest serwerem Apache Thrift. Akceptuje żądania od różnych klientów i udostępnia je sterownikowi Hive.
- Sterownik Hive — odbiera zapytania z różnych źródeł, takich jak interfejs WWW, CLI, Thrift i sterownik JDBC/ODBC. Przesyła zapytania do kompilatora.
- Kompilator Hive — celem kompilatora jest analizowanie zapytania i przeprowadzanie analizy semantycznej różnych bloków zapytań i wyrażeń. Konwertuje instrukcje HiveQL na zadania MapReduce.
- Hive Execution Engine — Optimizer generuje plan logiczny w formie DAG zadań zmniejszania mapy i zadań HDFS. Na koniec silnik wykonawczy wykonuje przychodzące zadania w kolejności ich zależności.