Wstęp:
Skrócenie adresów URL jest przykładem mieszania, ponieważ mapuje adresy URL o dużych rozmiarach na małe
Kilka przykładów funkcji skrótu:
- klucz % liczba segmentów
- Wartość ASCII znaku * PrimeNumberX. Gdzie x = 1, 2, 3….n
- Możesz stworzyć własną funkcję mieszającą, ale powinna to być dobra funkcja mieszająca, która daje mniejszą liczbę kolizji.
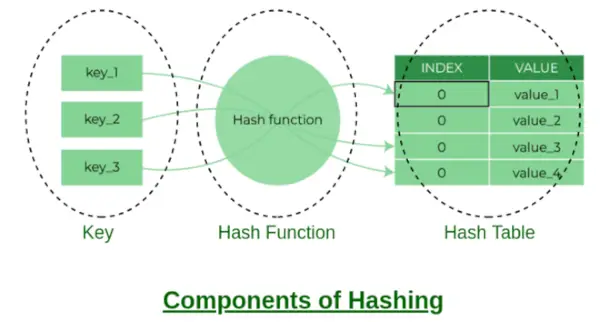
Składniki haszowania
: w Javie
Indeks wiadra:
Wartość zwrócona przez funkcję Hash jest indeksem segmentu klucza w oddzielnej metodzie łączenia łańcuchowego. Każdy indeks w tablicy nazywany jest segmentem, ponieważ jest segmentem połączonej listy.
Powtórzenie:
Ponowne mieszanie to koncepcja, która zmniejsza kolizję, gdy elementy są zwiększane w bieżącej tabeli mieszającej. Utworzy nową tablicę o podwójnym rozmiarze i skopiuje do niej poprzednie elementy tablicy, co przypomina wewnętrzne działanie wektora w C++. Oczywiście funkcja Hash powinna być dynamiczna, ponieważ powinna odzwierciedlać pewne zmiany w miarę zwiększania jej pojemności. Funkcja mieszająca uwzględnia w sobie pojemność tablicy mieszającej, zatem podczas kopiowania kluczowych wartości z poprzedniej funkcji skrótu tablicowego daje różne indeksy segmentów, gdyż jest to zależne od pojemności (zasobników) tablicy mieszającej. Ogólnie rzecz biorąc, gdy wartość współczynnika obciążenia jest większa niż 0,5, wykonywane jest ponowne mieszanie.
- Podwoić rozmiar tablicy.
- Skopiuj elementy poprzedniej tablicy do nowej tablicy. Używamy funkcji skrótu podczas ponownego kopiowania każdego węzła do nowej tablicy, dlatego zmniejszy to kolizję.
- Usuń poprzednią tablicę z pamięci i skieruj wskaźnik tablicy mieszającej na tę nową tablicę.
- Ogólnie rzecz biorąc, współczynnik obciążenia = liczba elementów w mapie skrótu / całkowita liczba segmentów (pojemność).
Kolizja:
Kolizja to sytuacja, gdy indeks wiadra nie jest pusty. Oznacza to, że w indeksie tego segmentu znajduje się nagłówek listy połączonej. Mamy dwie lub więcej wartości, które odpowiadają temu samemu indeksowi segmentu.
Główne funkcje w naszym programie
- Wprowadzenie
- Szukaj
- Funkcja skrótu
- Usuwać
- Ponowne mieszanie
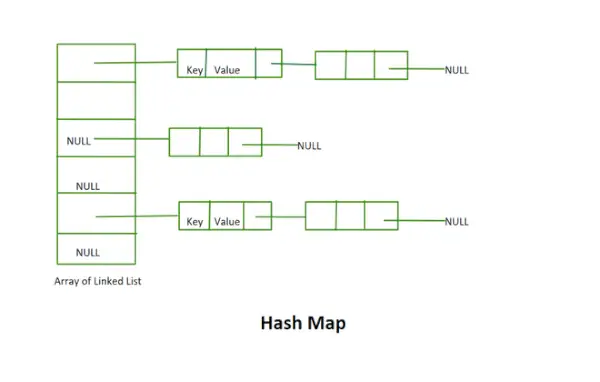
Mapa skrótu
Implementacja bez ponownego mieszania:
pobierz youtube za pomocą vlc
C
#include> #include> #include> // Linked List node> struct> node {> >// key is string> >char>* key;> >// value is also string> >char>* value;> >struct> node* next;> };> // like constructor> void> setNode(>struct> node* node,>char>* key,>char>* value)> {> >node->klucz = klucz;> >node->wartość = wartość;> >node->następny = NULL;> >return>;> };> struct> hashMap {> >// Current number of elements in hashMap> >// and capacity of hashMap> >int> numOfElements, capacity;> >// hold base address array of linked list> >struct> node** arr;> };> // like constructor> void> initializeHashMap(>struct> hashMap* mp)> {> >// Default capacity in this case> >mp->pojemność = 100;> >mp->liczba elementów = 0;> >// array of size = 1> >mp->tablica = (>struct> node**)>malloc>(>sizeof>(>struct> node*)> >* mp->pojemność);> >return>;> }> int> hashFunction(>struct> hashMap* mp,>char>* key)> {> >int> bucketIndex;> >int> sum = 0, factor = 31;> >for> (>int> i = 0; i <>strlen>(key); i++) {> >// sum = sum + (ascii value of> >// char * (primeNumber ^ x))...> >// where x = 1, 2, 3....n> >sum = ((sum % mp->pojemność)> >+ (((>int>)key[i]) * factor) % mp->pojemność)> >% mp->pojemność;> >// factor = factor * prime> >// number....(prime> >// number) ^ x> >factor = ((factor % __INT16_MAX__)> >* (31 % __INT16_MAX__))> >% __INT16_MAX__;> >}> >bucketIndex = sum;> >return> bucketIndex;> }> void> insert(>struct> hashMap* mp,>char>* key,>char>* value)> {> >// Getting bucket index for the given> >// key - value pair> >int> bucketIndex = hashFunction(mp, key);> >struct> node* newNode = (>struct> node*)>malloc>(> >// Creating a new node> >sizeof>(>struct> node));> >// Setting value of node> >setNode(newNode, key, value);> >// Bucket index is empty....no collision> >if> (mp->arr[bucketIndex] == NULL) {> >mp->arr[bucketIndex] = nowyWęzeł;> >}> >// Collision> >else> {> >// Adding newNode at the head of> >// linked list which is present> >// at bucket index....insertion at> >// head in linked list> >newNode->next = mp->arr[bucketIndex];> >mp->arr[bucketIndex] = nowyWęzeł;> >}> >return>;> }> void> delete> (>struct> hashMap* mp,>char>* key)> {> >// Getting bucket index for the> >// given key> >int> bucketIndex = hashFunction(mp, key);> >struct> node* prevNode = NULL;> >// Points to the head of> >// linked list present at> >// bucket index> >struct> node* currNode = mp->arr[bucketIndex];> >while> (currNode != NULL) {> >// Key is matched at delete this> >// node from linked list> >if> (>strcmp>(key, currNode->klucz) == 0) {> >// Head node> >// deletion> >if> (currNode == mp->arr[bucketIndex]) {> >mp->arr[bucketIndex] = currNode->next;> >}> >// Last node or middle node> >else> {> >prevNode->następny = currNode->next;> >}> >free>(currNode);> >break>;> >}> >prevNode = currNode;> >currNode = currNode->następny;> >}> >return>;> }> char>* search(>struct> hashMap* mp,>char>* key)> {> >// Getting the bucket index> >// for the given key> >int> bucketIndex = hashFunction(mp, key);> >// Head of the linked list> >// present at bucket index> >struct> node* bucketHead = mp->arr[bucketIndex];> >while> (bucketHead != NULL) {> >// Key is found in the hashMap> >if> (bucketHead->klucz == klucz) {> >return> bucketHead->wartość;> >}> >bucketHead = bucketHead->następny;> >}> >// If no key found in the hashMap> >// equal to the given key> >char>* errorMssg = (>char>*)>malloc>(>sizeof>(>char>) * 25);> >errorMssg =>'Oops! No data found.
'>;> >return> errorMssg;> }> // Drivers code> int> main()> {> >// Initialize the value of mp> >struct> hashMap* mp> >= (>struct> hashMap*)>malloc>(>sizeof>(>struct> hashMap));> >initializeHashMap(mp);> >insert(mp,>'Yogaholic'>,>'Anjali'>);> >insert(mp,>'pluto14'>,>'Vartika'>);> >insert(mp,>'elite_Programmer'>,>'Manish'>);> >insert(mp,>'GFG'>,>'techcodeview.com'>);> >insert(mp,>'decentBoy'>,>'Mayank'>);> >printf>(>'%s
'>, search(mp,>'elite_Programmer'>));> >printf>(>'%s
'>, search(mp,>'Yogaholic'>));> >printf>(>'%s
'>, search(mp,>'pluto14'>));> >printf>(>'%s
'>, search(mp,>'decentBoy'>));> >printf>(>'%s
'>, search(mp,>'GFG'>));> >// Key is not inserted> >printf>(>'%s
'>, search(mp,>'randomKey'>));> >printf>(>'
After deletion :
'>);> >// Deletion of key> >delete> (mp,>'decentBoy'>);> >printf>(>'%s
'>, search(mp,>'decentBoy'>));> >return> 0;> }> |
>
jaki jest rozmiar ekranu mojego komputera
>
C++
#include> #include> // Linked List node> struct> node {> >// key is string> >char>* key;> >// value is also string> >char>* value;> >struct> node* next;> };> // like constructor> void> setNode(>struct> node* node,>char>* key,>char>* value) {> >node->klucz = klucz;> >node->wartość = wartość;> >node->następny = NULL;> >return>;> }> struct> hashMap {> >// Current number of elements in hashMap> >// and capacity of hashMap> >int> numOfElements, capacity;> >// hold base address array of linked list> >struct> node** arr;> };> // like constructor> void> initializeHashMap(>struct> hashMap* mp) {> >// Default capacity in this case> >mp->pojemność = 100;> >mp->liczba elementów = 0;> >// array of size = 1> >mp->tablica = (>struct> node**)>malloc>(>sizeof>(>struct> node*) * mp->pojemność);> >return>;> }> int> hashFunction(>struct> hashMap* mp,>char>* key) {> >int> bucketIndex;> >int> sum = 0, factor = 31;> >for> (>int> i = 0; i <>strlen>(key); i++) {> >// sum = sum + (ascii value of> >// char * (primeNumber ^ x))...> >// where x = 1, 2, 3....n> >sum = ((sum % mp->pojemność) + (((>int>)key[i]) * factor) % mp->pojemność) % mp->pojemność;> >// factor = factor * prime> >// number....(prime> >// number) ^ x> >factor = ((factor % __INT16_MAX__) * (31 % __INT16_MAX__)) % __INT16_MAX__;> >}> >bucketIndex = sum;> >return> bucketIndex;> }> void> insert(>struct> hashMap* mp,>char>* key,>char>* value) {> >// Getting bucket index for the given> >// key - value pair> >int> bucketIndex = hashFunction(mp, key);> >struct> node* newNode = (>struct> node*)>malloc>(> >// Creating a new node> >sizeof>(>struct> node));> >// Setting value of node> >setNode(newNode, key, value);> >// Bucket index is empty....no collision> >if> (mp->arr[bucketIndex] == NULL) {> >mp->arr[bucketIndex] = nowyWęzeł;> >}> >// Collision> >else> {> >// Adding newNode at the head of> >// linked list which is present> >// at bucket index....insertion at> >// head in linked list> >newNode->next = mp->arr[bucketIndex];> >mp->arr[bucketIndex] = nowyWęzeł;> >}> >return>;> }> void> deleteKey(>struct> hashMap* mp,>char>* key) {> >// Getting bucket index for the> >// given key> >int> bucketIndex = hashFunction(mp, key);> >struct> node* prevNode = NULL;> >// Points to the head of> >// linked list present at> >// bucket index> >struct> node* currNode = mp->arr[bucketIndex];> >while> (currNode != NULL) {> >// Key is matched at delete this> >// node from linked list> >if> (>strcmp>(key, currNode->klucz) == 0) {> >// Head node> >// deletion> >if> (currNode == mp->arr[bucketIndex]) {> >mp->arr[bucketIndex] = currNode->next;> >}> >// Last node or middle node> >else> {> >prevNode->następny = currNode->next;> }> free>(currNode);> break>;> }> prevNode = currNode;> >currNode = currNode->następny;> >}> return>;> }> char>* search(>struct> hashMap* mp,>char>* key) {> // Getting the bucket index for the given key> int> bucketIndex = hashFunction(mp, key);> // Head of the linked list present at bucket index> struct> node* bucketHead = mp->arr[bucketIndex];> while> (bucketHead != NULL) {> > >// Key is found in the hashMap> >if> (>strcmp>(bucketHead->klucz, klucz) == 0) {> >return> bucketHead->wartość;> >}> > >bucketHead = bucketHead->następny;> }> // If no key found in the hashMap equal to the given key> char>* errorMssg = (>char>*)>malloc>(>sizeof>(>char>) * 25);> strcpy>(errorMssg,>'Oops! No data found.
'>);> return> errorMssg;> }> // Drivers code> int> main()> {> // Initialize the value of mp> struct> hashMap* mp = (>struct> hashMap*)>malloc>(>sizeof>(>struct> hashMap));> initializeHashMap(mp);> insert(mp,>'Yogaholic'>,>'Anjali'>);> insert(mp,>'pluto14'>,>'Vartika'>);> insert(mp,>'elite_Programmer'>,>'Manish'>);> insert(mp,>'GFG'>,>'techcodeview.com'>);> insert(mp,>'decentBoy'>,>'Mayank'>);> printf>(>'%s
'>, search(mp,>'elite_Programmer'>));> printf>(>'%s
'>, search(mp,>'Yogaholic'>));> printf>(>'%s
'>, search(mp,>'pluto14'>));> printf>(>'%s
'>, search(mp,>'decentBoy'>));> printf>(>'%s
'>, search(mp,>'GFG'>));> // Key is not inserted> printf>(>'%s
'>, search(mp,>'randomKey'>));> printf>(>'
After deletion :
'>);> // Deletion of key> deleteKey(mp,>'decentBoy'>);> // Searching the deleted key> printf>(>'%s
'>, search(mp,>'decentBoy'>));> return> 0;> }> |
usuwanie ostatniego zatwierdzenia gi
>
>Wyjście
alfabet z cyframi
Manish Anjali Vartika Mayank techcodeview.com Oops! No data found. After deletion : Oops! No data found.>
Wyjaśnienie:
- wstawianie: wstawia parę klucz-wartość na początku połączonej listy, która jest obecna w danym indeksie segmentu. hashFunction: Podaje indeks segmentu dla danego klucza. Nasz funkcja skrótu = wartość ASCII znaku * liczba pierwszaX . Liczbą pierwszą w naszym przypadku jest 31, a wartość x rośnie od 1 do n dla kolejnych znaków w kluczu. deletion: Usuwa parę klucz-wartość z tablicy mieszającej dla danego klucza. Usuwa węzeł z połączonej listy, która zawiera parę klucz-wartość. Szukaj: Szukaj wartości podanego klucza.
- Ta implementacja nie wykorzystuje koncepcji ponownego mieszania. Jest to tablica połączonych list o stałym rozmiarze.
- W podanym przykładzie klucz i wartość są ciągami znaków.
Złożoność czasu i złożoność przestrzeni:
Złożoność czasowa operacji wstawiania i usuwania tablicy skrótów wynosi średnio O(1). Istnieją pewne matematyczne obliczenia, które to potwierdzają.
- Złożoność czasowa wstawienia: W przeciętnym przypadku jest stała. W najgorszym przypadku jest liniowy. Złożoność czasowa wyszukiwania: W przeciętnym przypadku jest stała. W najgorszym przypadku jest liniowy. Złożoność czasowa usuwania: W przeciętnych przypadkach jest stała. W najgorszym przypadku jest liniowy. Złożoność przestrzeni: O(n), ponieważ ma n elementów.
Powiązane artykuły:
- Technika obsługi kolizji z oddzielnym łańcuchem w haszowaniu.