Proces może być dwojakiego rodzaju:
- Niezależny proces.
- Proces współpracy.
Na niezależny proces nie ma wpływu wykonanie innych procesów, podczas gdy na proces współpracujący mogą wpływać inne wykonujące się procesy. Chociaż można pomyśleć, że te procesy, które działają niezależnie, będą wykonywane bardzo wydajnie, w rzeczywistości istnieje wiele sytuacji, w których można wykorzystać charakter kooperacyjny w celu zwiększenia szybkości obliczeń, wygody i modułowości. Komunikacja między procesami (IPC) to mechanizm, który pozwala procesom komunikować się między sobą i synchronizować swoje działania. Komunikację pomiędzy tymi procesami można postrzegać jako metodę współdziałania pomiędzy nimi. Procesy mogą komunikować się ze sobą poprzez:
- Wspólna pamięć
- Przekazywanie wiadomości
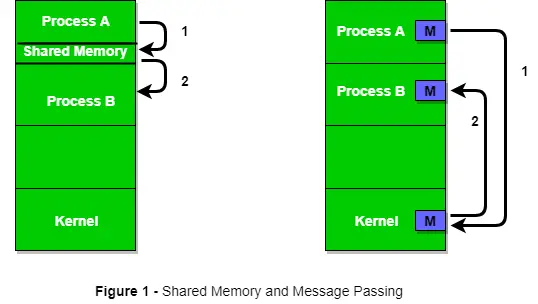
Rysunek 1 poniżej przedstawia podstawową strukturę komunikacji pomiędzy procesami za pomocą metody pamięci współdzielonej i metody przekazywania komunikatów.
System operacyjny może implementować oba sposoby komunikacji. Najpierw omówimy metody komunikacji w pamięci współdzielonej, a następnie przekazywanie wiadomości. Komunikacja pomiędzy procesami wykorzystującymi pamięć współdzieloną wymaga od procesów współdzielenia jakiejś zmiennej i całkowicie zależy od tego, jak programista ją zaimplementuje. Jeden ze sposobów komunikacji przy użyciu pamięci współdzielonej można sobie wyobrazić w następujący sposób: Załóżmy, że procesy 1 i procesy 2 są wykonywane jednocześnie i współdzielą pewne zasoby lub wykorzystują pewne informacje z innego procesu. Proces1 generuje informacje o określonych obliczeniach lub używanych zasobach i przechowuje je jako zapis w pamięci współdzielonej. Kiedy proces2 będzie musiał skorzystać ze współdzielonych informacji, sprawdzi rekord przechowywany w pamięci współdzielonej, zanotuje informacje wygenerowane przez proces1 i podejmie odpowiednie działania. Procesy mogą wykorzystywać pamięć współdzieloną do wydobywania informacji w postaci rekordu z innego procesu, a także do dostarczania określonych informacji do innych procesów.
Omówmy przykład komunikacji pomiędzy procesami z wykorzystaniem metody pamięci współdzielonej.
i) Metoda pamięci współdzielonej
Przykład: problem producent-konsument
Istnieją dwa procesy: producent i konsument. Producent produkuje pewne rzeczy, a Konsument ten rzecz konsumuje. Obydwa procesy mają wspólną przestrzeń lub lokalizację w pamięci, zwaną buforem, w którym przechowywany jest przedmiot wyprodukowany przez Producenta i z którego Konsument konsumuje przedmiot w razie potrzeby. Istnieją dwie wersje tego problemu: pierwsza znana jest jako problem nieograniczonego bufora, w którym producent może kontynuować produkcję towarów i nie ma ograniczeń co do rozmiaru bufora, druga znana jest jako problem ograniczonego bufora w które Producent może wyprodukować do określonej liczby sztuk, zanim zacznie oczekiwać na ich spożycie przez Konsumenta. Omówimy problem ograniczonego bufora. Najpierw Producent i Konsument będą mieli wspólną pamięć, a następnie producent rozpocznie produkcję przedmiotów. Jeśli całkowita wyprodukowana pozycja jest równa wielkości bufora, producent będzie czekać, aż zostanie skonsumowana przez Konsumenta. Podobnie konsument najpierw sprawdzi dostępność towaru. W przypadku braku towaru Konsument będzie czekał, aż Producent go wyprodukuje. Jeśli są dostępne przedmioty, Konsument je skonsumuje. Pseudokod do zademonstrowania znajduje się poniżej:
Udostępnione dane pomiędzy dwoma procesami
C
#define buff_max 25> #define mod %> >struct> item{> >// different member of the produced data> >// or consumed data> >---------> >}> > >// An array is needed for holding the items.> >// This is the shared place which will be> >// access by both process> >// item shared_buff [ buff_max ];> > >// Two variables which will keep track of> >// the indexes of the items produced by producer> >// and consumer The free index points to> >// the next free index. The full index points to> >// the first full index.> >int> free_index = 0;> >int> full_index = 0;> > |
>
>
Kodeks procesu producenta
C
item nextProduced;> > >while>(1){> > >// check if there is no space> >// for production.> >// if so keep waiting.> >while>((free_index+1) mod buff_max == full_index);> > >shared_buff[free_index] = nextProduced;> >free_index = (free_index + 1) mod buff_max;> >}> |
>
>
Kodeks procesu konsumenckiego
C
item nextConsumed;> > >while>(1){> > >// check if there is an available> >// item for consumption.> >// if not keep on waiting for> >// get them produced.> >while>((free_index == full_index);> > >nextConsumed = shared_buff[full_index];> >full_index = (full_index + 1) mod buff_max;> >}> |
>
>
W powyższym kodzie Producent rozpocznie produkcję ponownie, gdy maksymalne wzmocnienie modów (free_index+1) będzie bezpłatne, ponieważ jeśli nie jest darmowe, oznacza to, że nadal istnieją przedmioty, które Konsument może skonsumować, więc nie ma potrzeby produkować więcej. Podobnie, jeśli indeks wolny i indeks pełny wskazują ten sam indeks, oznacza to, że nie ma żadnych elementów do wykorzystania.
Ogólna implementacja C++:
C++
#include> #include> #include> #include> #define buff_max 25> #define mod %> struct> item {> >// different member of the produced data> >// or consumed data> >// ---------> };> // An array is needed for holding the items.> // This is the shared place which will be> // access by both process> // item shared_buff[buff_max];> // Two variables which will keep track of> // the indexes of the items produced by producer> // and consumer The free index points to> // the next free index. The full index points to> // the first full index.> std::atomic<>int>>wolny_indeks(0);> std::atomic<>int>>pełny_indeks(0);> std::mutex mtx;> void> producer() {> >item new_item;> >while> (>true>) {> >// Produce the item> >// ...> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >// Add the item to the buffer> >while> (((free_index + 1) mod buff_max) == full_index) {> >// Buffer is full, wait for consumer> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> >mtx.lock();> >// Add the item to the buffer> >// shared_buff[free_index] = new_item;> >free_index = (free_index + 1) mod buff_max;> >mtx.unlock();> >}> }> void> consumer() {> >item consumed_item;> >while> (>true>) {> >while> (free_index == full_index) {> >// Buffer is empty, wait for producer> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> >mtx.lock();> >// Consume the item from the buffer> >// consumed_item = shared_buff[full_index];> >full_index = (full_index + 1) mod buff_max;> >mtx.unlock();> >// Consume the item> >// ...> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> }> int> main() {> >// Create producer and consumer threads> >std::vectorthread>wątki; wątki.emplace_back(producent); wątki.emplace_back(konsument); // Poczekaj na zakończenie wątków for (auto& thread : threads) { thread.join(); } zwróć 0; }> |
>
>
kompozycja relacji
Należy zauważyć, że klasa atomic służy do zapewnienia, że zmienne współdzielone free_index i full_index są aktualizowane niepodzielnie. Muteks służy do ochrony sekcji krytycznej, w której uzyskiwany jest dostęp do współdzielonego bufora. Funkcja Sleep_for służy do symulacji produkcji i konsumpcji towarów.
ii) Metoda przekazywania wiadomości
Teraz zaczniemy dyskusję na temat komunikacji pomiędzy procesami poprzez przekazywanie komunikatów. W tej metodzie procesy komunikują się ze sobą bez użycia jakiejkolwiek pamięci współdzielonej. Jeżeli dwa procesy p1 i p2 chcą się ze sobą komunikować, postępują w następujący sposób:
- Ustanów łącze komunikacyjne (jeśli łącze już istnieje, nie ma potrzeby ustanawiania go ponownie).
- Rozpocznij wymianę wiadomości, używając podstawowych elementów.
Potrzebujemy co najmniej dwóch prymitywów:
– wysłać (wiadomość, miejsce docelowe) lub wysłać (wiadomość)
– odbierać (wiadomość, host) lub odbierać (wiadomość)

Rozmiar wiadomości może mieć stały rozmiar lub zmienny rozmiar. Jeśli ma stały rozmiar, jest łatwy dla projektanta systemu operacyjnego, ale skomplikowany dla programisty, a jeśli ma zmienny rozmiar, jest łatwy dla programisty, ale skomplikowany dla projektanta systemu operacyjnego. Standardowa wiadomość może składać się z dwóch części: nagłówek i treść.
The część nagłówkowa służy do przechowywania typu wiadomości, identyfikatora miejsca docelowego, identyfikatora źródła, długości wiadomości i informacji sterujących. Informacje sterujące zawierają informacje, co zrobić, jeśli zabraknie miejsca w buforze, numer kolejny i priorytet. Generalnie wiadomość jest wysyłana w stylu FIFO.
Wiadomość przekazywana przez łącze komunikacyjne.
Bezpośrednie i pośrednie łącze komunikacyjne
Teraz zaczniemy dyskusję na temat metod realizacji łączy komunikacyjnych. Podczas wdrażania łącza należy pamiętać o kilku kwestiach, takich jak:
- Jak tworzone są linki?
- Czy łącze może być powiązane z więcej niż dwoma procesami?
- Ile połączeń może istnieć pomiędzy każdą parą komunikujących się procesów?
- Jaka jest pojemność łącza? Czy rozmiar wiadomości, jaki może pomieścić link, jest stały czy zmienny?
- Czy łącze jest jednokierunkowe czy dwukierunkowe?
Łącze ma pewną pojemność, która określa liczbę komunikatów, które mogą się w nim tymczasowo znajdować, a z każdym łączem jest powiązana kolejka, która może mieć pojemność zerową, pojemność ograniczoną lub pojemność nieograniczoną. Przy zerowej pojemności nadawca czeka, aż odbiorca poinformuje nadawcę, że otrzymał wiadomość. W przypadkach o pojemności niezerowej proces nie wie, czy po operacji wysyłania wiadomość została odebrana, czy nie. W tym celu nadawca musi wyraźnie komunikować się z odbiorcą. Realizacja łącza zależy od sytuacji, może to być bezpośrednie łącze komunikacyjne lub pośrednie łącze komunikacyjne.
Bezpośrednie łącza komunikacyjne realizowane są wtedy, gdy procesy używają do komunikacji określonego identyfikatora procesu, ale trudno jest wcześniej zidentyfikować nadawcę.
Na przykład serwer druku.
Komunikacja pośrednia odbywa się poprzez współdzieloną skrzynkę pocztową (port), która składa się z kolejki wiadomości. Nadawca przechowuje wiadomość w skrzynce pocztowej, a odbiorca ją odbiera.
Przekazywanie wiadomości poprzez wymianę wiadomości.
Synchroniczne i asynchroniczne przekazywanie komunikatów:
Zablokowany proces to taki, który oczekuje na jakieś zdarzenie, takie jak udostępnienie zasobu lub zakończenie operacji we/wy. IPC jest możliwe pomiędzy procesami na tym samym komputerze, jak również pomiędzy procesami działającymi na innym komputerze, tj. w systemie sieciowym/rozproszonym. W obu przypadkach proces może zostać zablokowany lub nie podczas wysyłania wiadomości lub próby odebrania wiadomości, więc przekazywanie wiadomości może blokować lub nie blokować. Rozważane jest blokowanie synchroniczny I blokowanie wysyłania oznacza, że nadawca zostanie zablokowany do czasu odebrania wiadomości przez odbiorcę. Podobnie, blokowanie odbioru ma blokadę odbiornika, dopóki wiadomość nie będzie dostępna. Rozważa się brak blokowania asynchroniczny i Nieblokujące wysyłanie oznacza, że nadawca wysyła wiadomość i kontynuuje. Podobnie, odbiór nieblokujący oznacza, że odbiorca otrzyma ważny komunikat lub wartość null. Po wnikliwej analizie możemy dojść do wniosku, że dla nadawcy bardziej naturalne jest nieblokowanie po przekazaniu wiadomości, gdyż może zaistnieć potrzeba wysłania wiadomości do różnych procesów. Jednakże nadawca oczekuje potwierdzenia od odbiorcy w przypadku niepowodzenia wysyłania. Podobnie bardziej naturalne jest, że odbiorca blokuje po wydaniu komunikatu odbiorczego, ponieważ informacje z odebranego komunikatu mogą zostać wykorzystane do dalszego wykonania. Jednocześnie, jeśli wysyłanie wiadomości będzie się nadal kończyć niepowodzeniem, odbiorca będzie musiał czekać w nieskończoność. Dlatego rozważamy również inną możliwość przekazywania wiadomości. Zasadniczo istnieją trzy preferowane kombinacje:
- Blokowanie wysyłania i blokowanie odbierania
- Nieblokujące wysyłanie i nieblokujące odbieranie
- Nieblokujące wysyłanie i blokowanie odbierania (najczęściej używane)
W bezpośrednim przekazywaniu wiadomości , Proces chcący się komunikować musi wyraźnie wskazać odbiorcę lub nadawcę komunikacji.
np. wyślij(p1, wiadomość) oznacza wysłanie wiadomości do p1.
Podobnie, odbierać (p2, wiadomość) oznacza odebranie wiadomości od p2.
W tej metodzie komunikacji łącze komunikacyjne jest ustanawiane automatycznie i może być jednokierunkowe lub dwukierunkowe, ale jedno łącze może być użyte pomiędzy jedną parą nadawcy i odbiorcy, a jedna para nadawcy i odbiorcy nie powinna posiadać więcej niż jednej pary spinki do mankietów. Można również wdrożyć symetrię i asymetrię między wysyłaniem i odbieraniem, tj. albo oba procesy będą nadawać sobie nawzajem nazwy w celu wysyłania i odbierania wiadomości, albo tylko nadawca będzie nadał nazwę odbiorcy w celu wysłania wiadomości i nie ma potrzeby, aby odbiorca podawał nazwę nadawcy dla otrzymanie wiadomości. Problem z tą metodą komunikacji polega na tym, że jeśli zmieni się nazwa jednego procesu, metoda ta nie będzie działać.
W pośrednim przekazywaniu wiadomości procesy korzystają ze skrzynek pocztowych (zwanych również portami) do wysyłania i odbierania wiadomości. Każda skrzynka pocztowa ma unikalny identyfikator, a procesy mogą się komunikować tylko wtedy, gdy dzielą skrzynkę pocztową. Łącze ustanawiane jest tylko wtedy, gdy procesy korzystają ze wspólnej skrzynki pocztowej, a pojedyncze łącze może być powiązane z wieloma procesami. Każda para procesów może współużytkować kilka łączy komunikacyjnych, które mogą być jednokierunkowe lub dwukierunkowe. Załóżmy, że dwa procesy chcą komunikować się poprzez pośrednie przekazywanie wiadomości. Wymagane operacje to: utworzenie skrzynki pocztowej, użycie tej skrzynki pocztowej do wysyłania i odbierania wiadomości, a następnie zniszczenie skrzynki pocztowej. Stosowane standardowe prymitywy to: wysłać wiadomość) co oznacza wysłanie wiadomości do skrzynki pocztowej A. Operacja podstawowa odbierania wiadomości również działa w ten sam sposób, np.: otrzymano (A, wiadomość) . Wystąpił problem z implementacją tej skrzynki pocztowej. Załóżmy, że więcej niż dwa procesy korzystają z tej samej skrzynki pocztowej i załóżmy, że proces p1 wysyła wiadomość do skrzynki pocztowej, który proces będzie odbiorcą? Można to rozwiązać, wymuszając, aby tylko dwa procesy mogły współużytkować pojedynczą skrzynkę pocztową, lub wymuszając, aby tylko jeden proces mógł wykonywać odbiór w danym momencie, lub losowo wybierając dowolny proces i powiadamiając nadawcę o odbiorcy. Skrzynka pocztowa może być prywatna dla jednej pary nadawcy/odbiorcy, ale może być także współdzielona przez wiele par nadawcy/odbiorcy. Port jest implementacją takiej skrzynki pocztowej, która może mieć wielu nadawców i jednego odbiorcę. Jest używany w aplikacjach klient/serwer (w tym przypadku serwer jest odbiorcą). Port jest własnością procesu odbierającego i jest tworzony przez system operacyjny na żądanie procesu odbiorcy i może zostać zniszczony na żądanie tego samego procesora odbiorcy, gdy odbiornik zakończy swoje działanie. Wymuszanie, aby tylko jeden proces mógł wykonywać odbiór, można przeprowadzić przy użyciu koncepcji wzajemnego wykluczania. Skrzynka pocztowa Mutex tworzony jest proces, który jest współdzielony przez n procesów. Nadawca nie blokuje i wysyła wiadomość. Pierwszy proces, który wykonuje odbiór, wejdzie do sekcji krytycznej, a wszystkie inne procesy zostaną zablokowane i będą czekać.
Omówmy teraz problem Producent-Konsument, korzystając z koncepcji przekazywania komunikatu. Producent umieszcza przesyłkę (wewnątrz wiadomości) w skrzynce pocztowej, a konsument może skonsumować przesyłkę, gdy w skrzynce pocztowej znajduje się co najmniej jedna wiadomość. Kod podano poniżej:
Kod producenta
C
void> Producer(>void>){> > >int> item;> >Message m;> > >while>(1){> > >receive(Consumer, &m);> >item = produce();> >build_message(&m , item ) ;> >send(Consumer, &m);> >}> >}> |
>
>
Kodeks konsumencki
C
void> Consumer(>void>){> > >int> item;> >Message m;> > >while>(1){> > >receive(Producer, &m);> >item = extracted_item();> >send(Producer, &m);> >consume_item(item);> >}> >}> |
>
>
Przykłady systemów IPC
- Posix: wykorzystuje metodę pamięci współdzielonej.
- Mach: wykorzystuje przekazywanie wiadomości
- Windows XP: wykorzystuje przekazywanie komunikatów przy użyciu lokalnych wywołań proceduralnych
Komunikacja w architekturze klient/serwer:
Istnieją różne mechanizmy:
- Rura
- Gniazdo elektryczne
- Zdalne wywołania proceduralne (RPC)
Powyższe trzy metody zostaną omówione w późniejszych artykułach, ponieważ wszystkie są dość koncepcyjne i zasługują na osobne artykuły.
Bibliografia:
- Koncepcje systemów operacyjnych autorstwa Galvina i in.
- Notatki z wykładów/ppt Ariela J. Franka, Uniwersytet Bar-Ilan
Komunikacja między procesami (IPC) to mechanizm, za pomocą którego procesy lub wątki mogą komunikować się i wymieniać między sobą dane na komputerze lub w sieci. IPC jest ważnym aspektem nowoczesnych systemów operacyjnych, ponieważ umożliwia współpracę różnych procesów i dzielenie zasobów, co prowadzi do zwiększenia wydajności i elastyczności.
Zalety IPC:
- Umożliwia procesom komunikację między sobą i współdzielenie zasobów, co prowadzi do zwiększenia wydajności i elastyczności.
- Ułatwia koordynację pomiędzy wieloma procesami, co prowadzi do lepszej ogólnej wydajności systemu.
- Umożliwia tworzenie systemów rozproszonych, które mogą obejmować wiele komputerów lub sieci.
- Można go używać do implementowania różnych protokołów synchronizacji i komunikacji, takich jak semafory, potoki i gniazda.
Wady IPC:
- Zwiększa złożoność systemu, utrudniając projektowanie, wdrażanie i debugowanie.
- Może wprowadzać luki w zabezpieczeniach, ponieważ procesy mogą mieć dostęp do danych należących do innych procesów lub je modyfikować.
- Wymaga ostrożnego zarządzania zasobami systemowymi, takimi jak pamięć i czas procesora, aby mieć pewność, że operacje IPC nie obniżą ogólnej wydajności systemu.
Może prowadzić do niespójności danych, jeśli wiele procesów próbuje uzyskać dostęp do tych samych danych lub je zmodyfikować w tym samym czasie. - Ogólnie rzecz biorąc, zalety IPC przeważają nad wadami, ponieważ jest to mechanizm niezbędny dla nowoczesnych systemów operacyjnych i umożliwia współpracę procesów oraz dzielenie się zasobami w elastyczny i wydajny sposób. Należy jednak zachować ostrożność podczas projektowania i wdrażania systemów IPC, aby uniknąć potencjalnych luk w zabezpieczeniach i problemów z wydajnością.
Więcej informacji referencyjnych:
http://nptel.ac.in/courses/106108101/pdf/Lecture_Notes/Mod%207_LN.pdf
https://www.youtube.com/watch?v=lcRqHwIn5Dk