Polecenie Linux uniq służy do usuwania wszystkich powtarzających się linii z pliku. Można go także używać do wyświetlania liczby dowolnych słów, tylko powtarzających się linii, ignorowania znaków i porównywania określonych pól. Jest to jedno z najczęściej używanych poleceń w Linuksa system. Często jest używany z polecenie sortowania ponieważ porównuje sąsiednie znaki. Odrzuca wszystkie identyczne linie i zapisuje wynik.
Składnia:
uniq [OPTION]... [INPUT [OUTPUT]]
Opcje:
Niektóre przydatne opcje wiersza poleceń polecenia uniq są następujące:
-c, --liczba: poprzedza linie liczbą wystąpień.
-d, --powtórzone: służy do drukowania duplikatów linii, po jednej dla każdej grupy.
-D: Służy do drukowania wszystkich zduplikowanych linii.
--all-repeated[=METODA]: Jest dość podobna do opcji '-D', różnica pomiędzy obydwoma opcjami polega na tym, że umożliwia oddzielenie grup pustą linią.
-f, --skip-fields=N: Służy do uniknięcia porównania pierwszych N pól.
--grupa[=METODA]: Służy do wyświetlania wszystkich pozycji i oddziela grupy pustą linią.
zmiana nazwy katalogu w systemie Linux
-i, --ignore-case: Służy do ignorowania różnic podczas porównywania.
-s, --skip-chars=N: Służy do uniknięcia porównania pierwszych N znaków.
-u, --unique: służy do drukowania unikalnych linii.
-z, --zero-zakończony: Jest używany, gdy ogranicznik linii ma wartość NUL, a nie tryb nowej linii.
-w, --check-chars=N: Służy do porównywania nie więcej niż N znaków w liniach.
--pomoc: Służy do wyświetlania dokumentacji pomocy.
--wersja: Służy do wyświetlania informacji o wersji.
Przykłady poleceń uniq
Zobaczmy następujące przykłady polecenia uniq:
- Usuń powtarzające się linie
- policzyć liczbę wystąpień słowa
- Wyświetl powtarzające się linie
- Wyświetl unikalne linie
- Ignoruj znaki w porównaniu
- Ignoruj pola w porównaniu
Usuń powtarzające się linie
Aby usunąć powtarzające się linie z pliku, wykonaj podstawowe polecenie uniq w następujący sposób:
połączenie pd
sort dupli.txt | uniq
Powyższe polecenie usunie zduplikowane linie z pliku „dupli.txt”. Rozważ poniższe dane wyjściowe:
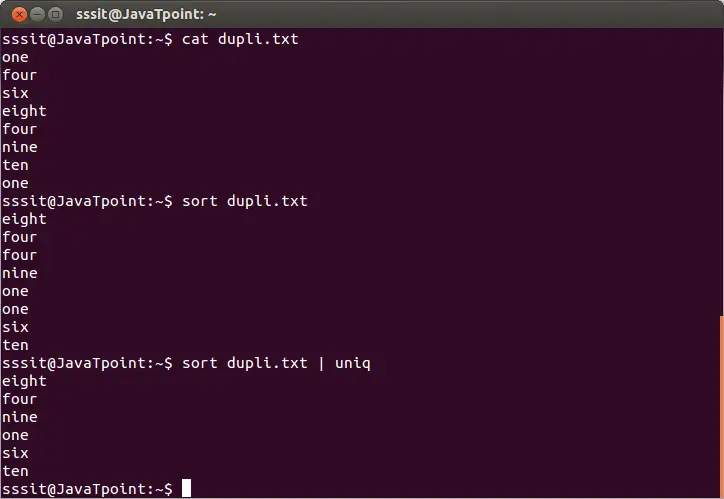
Z powyższego wyniku powtarzające się słowa są ignorowane.
Policz liczbę wystąpień słowa
Liczbę wystąpień słowa możemy policzyć za pomocą polecenia uniq. Do zliczania słowa używana jest opcja „-c”. Wykonaj to w następujący sposób:
sort dupli.txt | uniq -c
Powyższe polecenie policzy słowa znajdujące się w pliku „dupli.txt”. Rozważ poniższe dane wyjściowe:
pochodna częściowa w lateksie

Z powyższych wyników należy wykonać polecenie „sort dupli.txt | uniq -c' zlicza liczbę powtórzeń słowa.
Wyświetl powtarzające się linie
Opcja „-d” służy do wyświetlania tylko powtarzających się linii. Wyświetli tylko te linie, które będą więcej niż raz w pliku i zapisze dane wyjściowe na standardowe wyjście. Rozważ poniższe polecenie:
sort dupli.txt | uniq -d
Powyższe polecenie wyświetli tylko powtarzające się linie. Rozważ poniższe dane wyjściowe:

Wyświetl unikalne linie
Opcja „-u” służy do wyświetlania tylko unikalnych linii (które się nie powtarzają). Wyświetli tylko linie, które wystąpią tylko raz i zapisze wynik na standardowe wyjście. Rozważ poniższe polecenie:
sort dupli.txt | uniq -u
Powyższe polecenie wyświetli tylko unikalne linie z pliku „dupli.txt”. Rozważ poniższe dane wyjściowe:

Ignoruj znaki w porównaniu
Opcja „-s” służy do ignorowania porównywanych znaków. Zignoruje określoną liczbę znaków i wyświetli wynik na standardowym wyjściu. Rozważ poniższe polecenie:
sort dupli.txt | uniq -s 2
Powyższe polecenie zignoruje pierwsze dwa znaki w porównaniu z plikiem „dupli.txt”. Rozważ poniższe dane wyjściowe:

Ignoruj pola w porównaniu
Opcja „-f” służy do ignorowania pól. Rozważ poniższe polecenie:
uniq -f 2 dupli2.txt
Powyższe polecenie nie porówna dwóch pierwszych pól z pliku 'dupli2.txt'. Rozważ poniższe dane wyjściowe:

W powyższym wyniku pierwsze dwa pola są pomijane, a pozostałe pola są porównywane z pliku „dupli2.txt”.