Python to świetny język do analizy danych, przede wszystkim ze względu na fantastyczny ekosystem zorientowany na dane Pyton pakiety. Pandy jest jednym z takich pakietów i znacznie ułatwia importowanie i analizowanie danych.
Średnia ramka danych Pandy()
Pandy ramka danych.średnia() funkcja zwraca średnią wartości dla żądanej osi. Jeżeli metoda zostanie zastosowana na obiekcie serii Pandy, wówczas metoda zwróci wartość skalarną będącą średnią wartością wszystkich obserwacji w Ramka danych Pandy . Jeśli metoda zostanie zastosowana do obiektu Pandas Dataframe, wówczas metoda zwróci a Seria Pandy obiekt zawierający średnią wartości na określonej osi.
Składnia: DataFrame.mean(oś=0, pomiń=prawda, poziom=brak, numeric_only=fałsz, **kwargs)
Parametry:
- oś: {indeks (0), kolumny (1)}
- zamówienie : Wyklucz wartości NA/null podczas obliczania wyniku
- poziom: Jeśli oś jest MultiIndexem (hierarchiczna), policz wzdłuż określonego poziomu, zwijając się w serię
- tylko_numeryczny: Uwzględnij tylko kolumny float, int i boolean. Jeśli Brak, spróbuje użyć wszystkiego, użyj tylko danych liczbowych. Nie zaimplementowano dla serii.
Zwroty : oznacza: Seria lub DataFrame (jeśli określono poziom)
polimorfizm Javy
Pandy DataFrame.mean() Przykłady
Przykład 1:
Użyj funkcji mean(), aby znaleźć średnią wszystkich obserwacji na osi indeksu.
Pyton # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, 44, 1], 'B':[5, 2, 54, 3, 2], 'C':[20, 16, 7, 3, 8], 'D':[14, 3, 17, 2, 6]}) # Print the dataframe df> 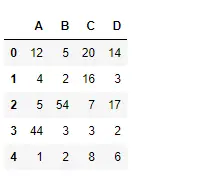
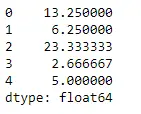
Użyjmy funkcji Dataframe.mean(), aby znaleźć średnią na osi indeksu.
Pyton # Even if we do not specify axis = 0, # the method will return the mean over # the index axis by default df.mean(axis = 0)>
Wyjście:
Przykład 2:
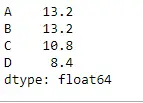
Użyj funkcji mean() w ramce danych, która nie ma wartości None. Znajdź także średnią na osi kolumny.
Pyton # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, None, 1], 'B':[7, 2, 54, 3, None], 'C':[20, 16, 11, 3, 8], 'D':[14, 3, None, 2, 6]}) # skip the Na values while finding the mean df.mean(axis = 1, skipna = True)> Wyjście: