Czytamy liniowe struktury danych, takie jak tablica, lista połączona, stos i kolejka, w których wszystkie elementy są ułożone sekwencyjnie. Dla różnych rodzajów danych wykorzystywane są różne struktury danych.
Przy wyborze struktury danych bierze się pod uwagę kilka czynników:
Drzewo jest także jedną ze struktur danych reprezentujących dane hierarchiczne. Załóżmy, że chcemy pokazać pracowników i ich stanowiska w formie hierarchicznej, można to przedstawić w sposób pokazany poniżej:
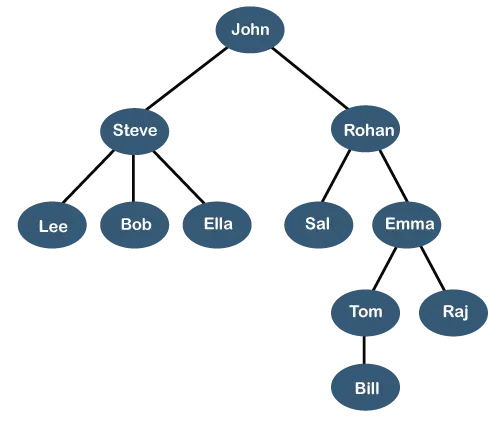
Powyższe drzewo przedstawia hierarchia organizacji jakiejś firmy. W powyższej strukturze Jan jest Dyrektor generalny firmy, a John ma dwóch bezpośrednich podwładnych o nazwie jako Steve'a I Rohana . Steve ma trzech bezpośrednich podwładnych Lee, Bob, Ella Gdzie Steve'a jest menadżerem. Bob ma dwóch bezpośrednich podwładnych Być I Emma . Emma ma dwóch bezpośrednich podwładnych o nazwie Tomek I Raj . Tom ma jednego bezpośredniego podwładnego Rachunek . Ta szczególna struktura logiczna jest znana jako a Drzewo . Jego struktura jest podobna do prawdziwego drzewa, dlatego nosi nazwę Drzewo . W tej strukturze źródło znajduje się na górze, a jego gałęzie poruszają się w dół. Można zatem powiedzieć, że struktura danych typu Tree jest efektywnym sposobem przechowywania danych w sposób hierarchiczny.
Rozumiemy kilka kluczowych punktów struktury danych drzewa.
- Drzewiastą strukturę danych definiuje się jako zbiór obiektów lub jednostek zwanych węzłami, które są ze sobą połączone w celu reprezentowania lub symulowania hierarchii.
- Drzewiasta struktura danych jest nieliniową strukturą danych, ponieważ nie jest przechowywana w sposób sekwencyjny. Jest to struktura hierarchiczna, ponieważ elementy drzewa są ułożone na wielu poziomach.
- W strukturze danych drzewa najwyższy węzeł nazywany jest węzłem głównym. Każdy węzeł zawiera pewne dane, a dane mogą być dowolnego typu. W powyższej strukturze drzewa węzeł zawiera nazwisko pracownika, zatem typem danych będzie string.
- Każdy węzeł zawiera pewne dane oraz łącze lub odniesienie do innych węzłów, które można nazwać dziećmi.
Niektóre podstawowe terminy stosowane w strukturze danych drzewa.
Rozważmy strukturę drzewa, która jest pokazana poniżej:

W powyższej strukturze każdy węzeł jest oznaczony jakimś numerem. Każda strzałka pokazana na powyższym rysunku jest nazywana a połączyć pomiędzy dwoma węzłami.
Właściwości struktury danych drzewa

W oparciu o właściwości struktury danych Tree, drzewa dzieli się na różne kategorie.
Implementacja drzewa
Drzewiastą strukturę danych można utworzyć poprzez dynamiczne tworzenie węzłów za pomocą wskaźników. Drzewo w pamięci można przedstawić w sposób pokazany poniżej:

Powyższy rysunek przedstawia reprezentację drzewiastej struktury danych w pamięci. W powyższej strukturze węzeł zawiera trzy pola. Drugie pole przechowuje dane; pierwsze pole przechowuje adres lewego dziecka, a trzecie pole przechowuje adres prawego dziecka.
W programowaniu strukturę węzła można zdefiniować jako:
struct node { int data; struct node *left; struct node *right; } Powyższą strukturę można zdefiniować tylko dla drzew binarnych, ponieważ drzewo binarne może mieć maksymalnie dwoje dzieci, a drzewa generyczne mogą mieć więcej niż dwoje dzieci. Struktura węzła dla drzew ogólnych byłaby inna niż w przypadku drzewa binarnego.
polecenie instalacji npm
Zastosowania drzew
Oto zastosowania drzew:
Rodzaje drzewiastej struktury danych
Poniżej przedstawiono typy drzewiastej struktury danych:

Tam może być N liczba poddrzew w drzewie ogólnym. W drzewie ogólnym poddrzewa są nieuporządkowane, ponieważ nie można uporządkować węzłów w poddrzewie.
Każde niepuste drzewo ma krawędź skierowaną w dół, a krawędzie te są połączone węzłami tzw węzły podrzędne . Węzeł główny jest oznaczony poziomem 0. Węzły mające tego samego rodzica nazywane są rodzeństwo .

Aby dowiedzieć się więcej o drzewie binarnym, kliknij link podany poniżej:
https://www.javatpoint.com/binary-tree
Każdy węzeł w lewym poddrzewie musi zawierać wartość mniejszą niż wartość węzła głównego, a wartość każdego węzła w prawym poddrzewie musi być większa niż wartość węzła głównego.
Węzeł można utworzyć za pomocą zdefiniowanego przez użytkownika typu danych, tzw struktura, jak pokazano niżej:
struct node { int data; struct node *left; struct node *right; } Powyżej przedstawiono strukturę węzła z trzema polami: pole danych, drugie pole to lewy wskaźnik typu węzła, a trzecie pole to prawy wskaźnik typu węzła.
Aby dowiedzieć się więcej o drzewie wyszukiwania binarnego, kliknij link podany poniżej:
https://www.javatpoint.com/binary-search-tree
Jest to jeden z typów drzewa binarnego, lub można powiedzieć, że jest to odmiana drzewa wyszukiwania binarnego. Drzewo AVL spełnia właściwość drzewo binarne jak również z drzewo wyszukiwania binarnego . Jest to samobalansujące się drzewo wyszukiwania binarnego, które zostało wynalezione przez Adelsona Velsky’ego Lindasa . Tutaj samorównoważenie oznacza równoważenie wysokości lewego i prawego poddrzewa. Bilansowanie to mierzone jest w kategoriach czynnik równoważący .
Możemy uznać drzewo za drzewo AVL, jeśli drzewo jest zgodne z drzewem poszukiwań binarnych, a także czynnikiem równoważącym. Współczynnik równoważący można zdefiniować jako różnica między wysokością lewego poddrzewa a wysokością prawego poddrzewa . Wartość współczynnika równoważącego musi wynosić 0, -1 lub 1; dlatego każdy węzeł drzewa AVL powinien mieć wartość współczynnika równoważącego jako 0, -1 lub 1.
Aby dowiedzieć się więcej o drzewie AVL, kliknij link podany poniżej:
https://www.javatpoint.com/avl-tree
Drzewo czerwono-czarne jest drzewem wyszukiwania binarnego. Warunkiem wstępnym drzewa czerwono-czarnego jest wiedza o drzewie wyszukiwania binarnego. W drzewie wyszukiwania binarnego wartość lewego poddrzewa powinna być mniejsza niż wartość tego węzła, a wartość prawego poddrzewa powinna być większa niż wartość tego węzła. Jak wiemy, złożoność czasowa wyszukiwania binarnego w przeciętnym przypadku jest logarytmiczna2n, najlepszym przypadkiem jest O(1), a najgorszym przypadkiem O(n).
Kiedy na drzewie wykonywana jest jakakolwiek operacja, chcemy, żeby nasze drzewo było zrównoważone tak, aby wszystkie operacje takie jak wyszukiwanie, wstawianie, usuwanie itp. zajmowały mniej czasu, a wszystkie te operacje miały złożoność czasową dziennik2N.
algorytm Bellforda
Drzewo czerwono-czarne to samobalansujące się drzewo wyszukiwania binarnego. Drzewo AVL jest zatem również drzewem wyszukiwania binarnego równoważącego wysokość dlaczego potrzebujemy czerwono-czarnego drzewa . W drzewie AVL nie wiemy, ile obrotów potrzeba do zrównoważenia drzewa, ale w drzewie czerwono-czarnym do zrównoważenia drzewa potrzebne są maksymalnie 2 rotacje. Zawiera jeden dodatkowy bit, który reprezentuje czerwony lub czarny kolor węzła, aby zapewnić równowagę drzewa.
Struktura danych drzewa rozwinięcia jest także drzewem wyszukiwania binarnego, w którym ostatnio uzyskiwany dostęp do elementu jest umieszczany w pozycji korzenia drzewa poprzez wykonanie pewnych operacji obrotu. Tutaj, rozchylanie oznacza ostatnio używany węzeł. To jest samorównoważenie drzewo wyszukiwania binarnego nie mające wyraźnego warunku równowagi, np AVL drzewo.
Może istnieć możliwość, że wysokość drzewa rozgałęzionego nie jest zrównoważona, tj. wysokość lewego i prawego poddrzewa może się różnić, ale operacje na drzewie rozgałęzionym są następujące: spokój czas gdzie N to liczba węzłów.
Drzewo Splay jest drzewem zrównoważonym, ale nie można go uważać za drzewo zrównoważone pod względem wysokości, ponieważ po każdej operacji wykonywany jest obrót, który prowadzi do drzewa zrównoważonego.
Struktura danych Treap pochodzi ze struktury danych Tree i Heap. Zawiera więc właściwości struktur danych drzewa i sterty. W drzewie wyszukiwania binarnego każdy węzeł lewego poddrzewa musi być równy lub mniejszy od wartości węzła głównego, a każdy węzeł prawego poddrzewa musi być równy lub większy od wartości węzła głównego. W strukturze danych sterty zarówno prawe, jak i lewe poddrzewo zawierają większe klucze niż korzeń; dlatego możemy powiedzieć, że węzeł główny zawiera najniższą wartość.
W strukturze danych treap każdy węzeł ma oba klucz I priorytet gdzie klucz pochodzi z drzewa wyszukiwania binarnego, a priorytet ze struktury danych sterty.
The Treap struktura danych ma dwie właściwości podane poniżej:
- Prawe dziecko węzła>=bieżący węzeł i lewe dziecko węzła<=current node (binary tree)< li>
- Elementy potomne dowolnego poddrzewa muszą być większe niż węzeł (sterta)
Drzewo B jest zrównoważone sposób drzewo gdzie M określa kolejność drzewa. Do tej pory czytaliśmy, że węzeł zawiera tylko jeden klucz, ale b-tree może mieć więcej niż jeden klucz i więcej niż 2 dzieci. Zawsze przechowuje posortowane dane. W drzewie binarnym możliwe jest, że węzły liści mogą znajdować się na różnych poziomach, ale w drzewie b wszystkie węzły liści muszą znajdować się na tym samym poziomie.
Jeśli porządek wynosi m, wówczas węzeł ma następujące właściwości:
- Każdy węzeł w b-drzewie może mieć maksimum M dzieci
- W przypadku minimalnej liczby dzieci węzeł liścia ma 0 dzieci, węzeł główny ma co najmniej 2 dzieci, a węzeł wewnętrzny ma minimalny pułap m/2 dzieci. Na przykład wartość m wynosi 5, co oznacza, że węzeł może mieć 5 dzieci, a węzły wewnętrzne mogą mieć maksymalnie 3 dzieci.
- Każdy węzeł ma maksymalną liczbę (m-1) kluczy.
Węzeł główny musi zawierać co najmniej 1 klucz, a wszystkie pozostałe węzły muszą zawierać co najmniej sufit m/2 minus 1 Klucze.