Od czasu wynalezienia komputerów ludzie używają terminu „ Dane ' w odniesieniu do Informacji o komputerze, przesyłanych lub przechowywanych. Istnieją jednak dane, które istnieją również w typach zamówień. Danymi mogą być liczby lub teksty zapisane na kartce papieru, w formie bitów i bajtów przechowywanych w pamięci urządzeń elektronicznych lub fakty przechowywane w umyśle danej osoby. Gdy świat zaczął się modernizować, dane te stały się istotnym aspektem codziennego życia każdego człowieka, a różne wdrożenia umożliwiły ich przechowywanie w inny sposób.
Dane to zbiór faktów i liczb lub zbiór wartości lub wartości o określonym formacie, który odnosi się do pojedynczego zestawu wartości pozycji. Elementy danych są następnie klasyfikowane w podelementy, które stanowią grupę elementów, które nie są znane jako prosta pierwotna forma elementu.
Rozważmy przykład, w którym nazwisko pracownika można podzielić na trzy podelementy: pierwszy, środkowy i ostatni. Jednakże identyfikator przypisany pracownikowi będzie zazwyczaj traktowany jako pojedynczy element.
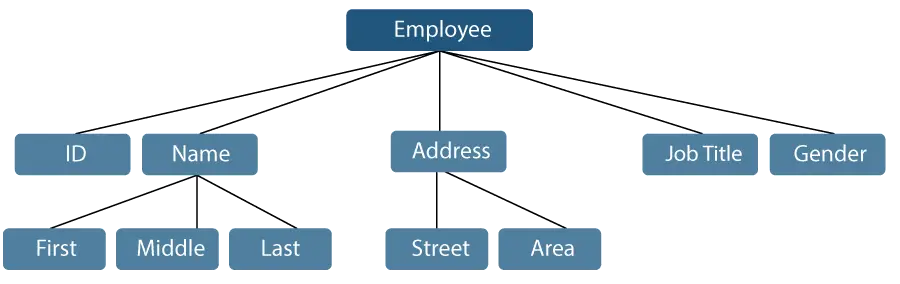
Rysunek 1: Reprezentacja elementów danych
W powyższym przykładzie elementy takie jak identyfikator, wiek, płeć, pierwsze, średnie, ostatnie, ulica, miejscowość itp. są elementarnymi elementami danych. Natomiast nazwa i adres są elementami danych grupowych.
Co to jest struktura danych?
Struktura danych jest gałęzią informatyki. Badanie struktury danych pozwala nam zrozumieć organizację danych i zarządzanie przepływem danych w celu zwiększenia wydajności dowolnego procesu lub programu. Struktura danych to szczególny sposób przechowywania i organizowania danych w pamięci komputera, dzięki czemu można je łatwo odzyskać i efektywnie wykorzystać w przyszłości, jeśli zajdzie taka potrzeba. Danymi można zarządzać na różne sposoby, na przykład logiczny lub matematyczny model określonej organizacji danych nazywany jest strukturą danych.
Zakres konkretnego modelu danych zależy od dwóch czynników:
- Po pierwsze, należy go wczytać do struktury na tyle, aby odzwierciedlał określoną korelację danych z obiektem ze świata rzeczywistego.
- Po drugie, tworzenie powinno być na tyle proste, aby w razie potrzeby można było dostosować się do wydajnego przetwarzania danych.
Przykładami struktur danych są tablice, listy połączone, stosy, kolejki, drzewa itp. Struktury danych są szeroko stosowane w niemal każdym aspekcie informatyki, tj. w projektowaniu kompilatorów, systemach operacyjnych, grafice, sztucznej inteligencji i wielu innych.
Struktury danych stanowią główną część wielu algorytmów informatycznych, ponieważ umożliwiają programistom efektywne zarządzanie danymi. Odgrywa kluczową rolę w poprawie wydajności programu lub oprogramowania, ponieważ głównym celem oprogramowania jest jak najszybsze przechowywanie i odzyskiwanie danych użytkownika.
w wyrażeniu regularnym Java
Podstawowe terminologie związane ze strukturami danych
Struktury danych są elementami składowymi dowolnego oprogramowania lub programu. Wybór odpowiedniej struktury danych dla programu jest niezwykle trudnym zadaniem dla programisty.
Poniżej przedstawiono kilka podstawowych terminologii używanych w przypadku struktur danych:
| Atrybuty | ID | Nazwa | Płeć | Stanowisko |
|---|---|---|---|---|
| Wartości | 1234 | Stacey M. Hill | Kobieta | Programista |
Podmioty o podobnych atrybutach tworzą Zestaw jednostek . Każdy atrybut zestawu jednostek ma zakres wartości, czyli zbiór wszystkich możliwych wartości, które można przypisać do konkretnego atrybutu.
Termin „informacja” jest czasami używany w odniesieniu do danych posiadających określone atrybuty danych znaczących lub przetworzonych.
Zrozumienie potrzeby struktur danych
Ponieważ aplikacje stają się coraz bardziej złożone, a ilość danych rośnie z każdym dniem, co może prowadzić do problemów z wyszukiwaniem danych, szybkością przetwarzania, obsługą wielu żądań i wieloma innymi. Struktury danych obsługują różne metody efektywnego organizowania, zarządzania i przechowywania danych. Za pomocą struktur danych możemy łatwo przeglądać elementy danych. Struktury danych zapewniają wydajność, możliwość ponownego użycia i abstrakcję.
Dlaczego powinniśmy uczyć się struktur danych?
- Struktury danych i algorytmy to dwa kluczowe aspekty informatyki.
- Struktury danych pozwalają nam organizować i przechowywać dane, natomiast algorytmy pozwalają nam w znaczący sposób je przetwarzać.
- Nauka struktur danych i algorytmów pomoże nam stać się lepszymi programistami.
- Będziemy mogli pisać kod, który będzie bardziej efektywny i niezawodny.
- Będziemy także mogli szybciej i skuteczniej rozwiązywać problemy.
Zrozumienie celów struktur danych
Struktury danych spełniają dwa uzupełniające się cele:
Zrozumienie niektórych kluczowych cech struktur danych
Niektóre z istotnych cech struktur danych to:
Klasyfikacja struktur danych
Struktura danych zapewnia uporządkowany zestaw zmiennych powiązanych ze sobą na różne sposoby. Stanowi podstawę narzędzia programistycznego, które oznacza relacje między elementami danych i umożliwia programistom efektywne przetwarzanie danych.
Struktury danych możemy podzielić na dwie kategorie:
- Pierwotna struktura danych
- Nieprymitywna struktura danych
Poniższy rysunek przedstawia różne klasyfikacje struktur danych.

Rysunek 2: Klasyfikacje struktur danych
Prymitywne struktury danych
- Tymi strukturami danych można manipulować lub obsługiwać je bezpośrednio za pomocą instrukcji na poziomie maszyny.
- Podstawowe typy danych, takie jak Liczba całkowita, zmiennoprzecinkowa, znakowa , I Wartość logiczna należą do prymitywnych struktur danych.
- Te typy danych są również nazywane Proste typy danych , ponieważ zawierają znaki, których nie można dalej dzielić
Nieprymitywne struktury danych
- Tymi strukturami danych nie można manipulować ani nimi sterować bezpośrednio za pomocą instrukcji na poziomie maszyny.
- Te struktury danych skupiają się na tworzeniu zestawu elementów danych, czyli albo jednorodny (ten sam typ danych) lub heterogeniczny (różne typy danych).
- W oparciu o strukturę i układ danych możemy podzielić te struktury danych na dwie podkategorie -
- Liniowe struktury danych
- Nieliniowe struktury danych
Liniowe struktury danych
Struktura danych, która zachowuje liniowe połączenie między elementami danych, nazywana jest liniową strukturą danych. Uporządkowanie danych odbywa się liniowo, gdzie każdy element składa się z następników i poprzedników, z wyjątkiem pierwszego i ostatniego elementu danych. Niekoniecznie jest to jednak prawdą w przypadku pamięci, gdyż układ nie może być sekwencyjny.
W oparciu o alokację pamięci liniowe struktury danych dzieli się dalej na dwa typy:
The Szyk jest najlepszym przykładem statycznej struktury danych, ponieważ mają stały rozmiar, a jej dane można później modyfikować.
Połączone listy, stosy , I Ogony są typowymi przykładami dynamicznych struktur danych
Rodzaje liniowych struktur danych
Poniżej znajduje się lista liniowych struktur danych, których zwykle używamy:
1. Tablice
Jakiś Szyk to struktura danych używana do gromadzenia wielu elementów danych tego samego typu w jedną zmienną. Zamiast przechowywać wiele wartości tego samego typu danych w oddzielnych nazwach zmiennych, moglibyśmy przechowywać je wszystkie razem w jednej zmiennej. To stwierdzenie nie oznacza, że będziemy musieli zjednoczyć wszystkie wartości tego samego typu danych w dowolnym programie w jedną tablicę tego typu danych. Często jednak zdarza się, że określone zmienne tego samego typu danych są ze sobą powiązane w sposób odpowiedni dla tablicy.
Tablica to lista elementów, gdzie każdy element ma swoje unikalne miejsce na liście. Elementy danych tablicy mają tę samą nazwę zmiennej; jednakże każdy z nich ma inny numer indeksu zwany indeksem dolnym. Dostęp do dowolnego elementu danych z listy możemy uzyskać za pomocą jego lokalizacji na liście. Zatem kluczową cechą tablic, którą należy zrozumieć, jest to, że dane są przechowywane w sąsiadujących lokalizacjach pamięci, co umożliwia użytkownikom przeglądanie elementów danych tablicy przy użyciu ich odpowiednich indeksów.

Rysunek 3. Tablica
css pogrubione
Tablice można podzielić na różne typy:
Niektóre zastosowania tablicy:
- Możemy przechowywać listę elementów danych należących do tego samego typu danych.
- Tablica działa jako pamięć pomocnicza dla innych struktur danych.
- Tablica pomaga również przechowywać elementy danych drzewa binarnego o stałej liczbie.
- Array pełni także funkcję magazynu macierzy.
2. Połączone listy
A Połączona lista to kolejny przykład liniowej struktury danych używanej do dynamicznego przechowywania zbioru elementów danych. Elementy danych w tej strukturze danych są reprezentowane przez węzły połączone za pomocą łączy lub wskaźników. Każdy węzeł zawiera dwa pola, pole informacyjne składa się z danych rzeczywistych, natomiast pole wskaźnikowe składa się z adresów kolejnych węzłów na liście. Wskaźnik ostatniego węzła połączonej listy składa się ze wskaźnika zerowego, ponieważ nie wskazuje na nic. W przeciwieństwie do tablic użytkownik może dynamicznie dostosowywać rozmiar połączonej listy zgodnie z wymaganiami.

Rysunek 4. Połączona lista
Listy połączone można podzielić na różne typy:
Niektóre zastosowania list połączonych:
- Listy połączone pomagają nam implementować stosy, kolejki, drzewa binarne i wykresy o predefiniowanym rozmiarze.
- Możemy również zaimplementować funkcję systemu operacyjnego do dynamicznego zarządzania pamięcią.
- Listy połączone umożliwiają także implementację wielomianów w operacjach matematycznych.
- Możemy używać Circular Linked List do implementowania systemów operacyjnych lub funkcji aplikacji, które wykonują zadania okrężnie.
- Okrągła lista połączona jest również pomocna w pokazie slajdów, w którym użytkownik musi wrócić do pierwszego slajdu po zaprezentowaniu ostatniego slajdu.
- Lista podwójnie połączona służy do implementowania przycisków „do przodu” i „do tyłu” w przeglądarce, umożliwiających poruszanie się do przodu i do tyłu na otwartych stronach witryny internetowej.
3. Stosy
A Stos jest liniową strukturą danych zgodną z LIFO (Last In, First Out), która umożliwia operacje takie jak wstawianie i usuwanie z jednego końca stosu, tj. z góry. Stosy można implementować za pomocą pamięci ciągłej, tablicy i pamięci nieciągłej, listy połączonej. Prawdziwymi przykładami stosów są stosy książek, talia kart, stosy pieniędzy i wiele innych.

Rysunek 5. Prawdziwy przykład stosu
Powyższy rysunek przedstawia rzeczywisty przykład stosu, w którym operacje są wykonywane tylko z jednego końca, np. wstawianie i usuwanie nowych książek ze szczytu stosu. Oznacza to, że wstawianie i usuwanie na stosie może być wykonane tylko z góry stosu. W danym momencie możemy uzyskać dostęp tylko do szczytów Stosu.
Podstawowe operacje na stosie są następujące:

Rysunek 6. Stos
przykłady programów w Pythonie
Niektóre zastosowania stosów:
- Stos jest używany jako struktura tymczasowego przechowywania dla operacji rekurencyjnych.
- Stos jest również wykorzystywany jako struktura pamięci pomocniczej dla wywołań funkcji, operacji zagnieżdżonych i funkcji odroczonych/przełożonych.
- Możemy zarządzać wywołaniami funkcji za pomocą stosów.
- Stosy są również wykorzystywane do oceny wyrażeń arytmetycznych w różnych językach programowania.
- Stosy są również pomocne w konwertowaniu wyrażeń infiksowych na wyrażenia postfiksowe.
- Stosy pozwalają nam sprawdzić składnię wyrażenia w środowisku programistycznym.
- Możemy dopasować nawiasy za pomocą stosów.
- Do odwrócenia ciągu można użyć stosów.
- Stosy są pomocne w rozwiązywaniu problemów w oparciu o cofanie się.
- Możemy używać stosów w przeszukiwaniu w głąb wykresu i przechodzenia przez drzewo.
- Stosy są również używane w funkcjach systemu operacyjnego.
- Stosy są także używane w funkcjach COFNIJ i PONOWNIE w edycji.
4. Ogony
A Kolejka to liniowa struktura danych podobna do stosu z pewnymi ograniczeniami dotyczącymi wstawiania i usuwania elementów. Wstawianie elementu do kolejki odbywa się na jednym końcu, a usuwanie na drugim lub przeciwległym końcu. Możemy zatem stwierdzić, że struktura danych kolejki jest zgodna z zasadą FIFO (pierwsze weszło, pierwsze wyszło), aby manipulować elementami danych. Implementację kolejek można wykonać za pomocą tablic, list połączonych lub stosów. Niektóre z rzeczywistych przykładów kolejek to kolejka przy kasie biletowej, schody ruchome, myjnia samochodowa i wiele innych.

Rysunek 7. Przykład kolejki z życia wzięty
Powyższy obraz to realistyczna ilustracja kasy biletowej do kina, która może pomóc nam zrozumieć kolejkę, w której klient, który przychodzi pierwszy, jest zawsze obsługiwany jako pierwszy. Klient, który przyjdzie ostatni, niewątpliwie zostanie obsłużony jako ostatni. Oba końce kolejki są otwarte i mogą wykonywać różne operacje. Innym przykładem jest linia food court, w której klient jest wstawiany od tyłu, a usuwany od przodu, po wykonaniu usługi, o którą prosił.
Poniżej przedstawiono podstawowe operacje kolejki:

Cyfra 8. Kolejka
Niektóre zastosowania kolejek:
- Kolejki są zwykle używane w operacji wyszukiwania wszerz na wykresach.
- Kolejki są również używane w operacjach Harmonogramu zadań w systemach operacyjnych, np. kolejka bufora klawiatury do przechowywania klawiszy naciśniętych przez użytkowników oraz kolejka bufora drukowania do przechowywania dokumentów wydrukowanych przez drukarkę.
- Kolejki są odpowiedzialne za planowanie procesora, planowanie zadań i planowanie dysku.
- Kolejki priorytetowe są wykorzystywane podczas operacji pobierania plików w przeglądarce.
- Kolejki służą także do przesyłania danych pomiędzy urządzeniami peryferyjnymi a procesorem.
- Kolejki są również odpowiedzialne za obsługę przerwań generowanych przez aplikacje użytkownika dla procesora.
Nieliniowe struktury danych
Nieliniowe struktury danych to struktury danych, w których elementy danych nie są ułożone w kolejności. W tym przypadku wstawianie i usuwanie danych nie jest możliwe w sposób liniowy. Istnieje hierarchiczna relacja pomiędzy poszczególnymi elementami danych.
Rodzaje nieliniowych struktur danych
Poniżej znajduje się lista nieliniowych struktur danych, których zwykle używamy:
1. Drzewa
Drzewo to nieliniowa struktura danych i hierarchia zawierająca zbiór węzłów, w którym każdy węzeł drzewa przechowuje wartość i listę odniesień do innych węzłów („dzieci”).
Struktura danych drzewa to wyspecjalizowana metoda porządkowania i gromadzenia danych w komputerze w celu efektywniejszego ich wykorzystania. Zawiera węzeł centralny, węzły konstrukcyjne i podwęzły połączone krawędziami. Można również powiedzieć, że struktura danych drzewa składa się z połączonych korzeni, gałęzi i liści.

Rysunek 9. Drzewo
Drzewa można podzielić na różne typy:
Niektóre zastosowania drzew:
drzewo avl
- Drzewa wdrażają struktury hierarchiczne w systemach komputerowych, takich jak katalogi i systemy plików.
- Drzewa służą także do realizacji struktury nawigacyjnej serwisu WWW.
- Możemy wygenerować kod podobny do kodu Huffmana za pomocą drzew.
- Drzewa są również pomocne w podejmowaniu decyzji w aplikacjach do gier.
- Drzewa są odpowiedzialne za implementację kolejek priorytetowych dla funkcji planowania systemu operacyjnego w oparciu o priorytety.
- Drzewa są również odpowiedzialne za analizowanie wyrażeń i instrukcji w kompilatorach różnych języków programowania.
- Możemy używać drzew do przechowywania kluczy danych do indeksowania dla systemu zarządzania bazami danych (DBMS).
- Spanning Trees pozwala nam kierować decyzjami w sieciach komputerowych i komunikacyjnych.
- Drzewa są również wykorzystywane w algorytmie wyszukiwania ścieżek wdrażanym w zastosowaniach sztucznej inteligencji (AI), robotyce i grach wideo.
2. Wykresy
Wykres to kolejny przykład nieliniowej struktury danych zawierającej skończoną liczbę węzłów lub wierzchołków i łączących je krawędzi. Wykresy są wykorzystywane do rozwiązywania problemów świata rzeczywistego, w którym oznaczają obszar problemowy jako sieć, taką jak sieci społecznościowe, sieci obwodów i sieci telefoniczne. Na przykład węzły lub wierzchołki Grafu mogą reprezentować pojedynczego użytkownika w sieci telefonicznej, podczas gdy krawędzie reprezentują połączenie między nimi za pośrednictwem telefonu.
Strukturę danych Graph, G, uważa się za strukturę matematyczną składającą się ze zbioru wierzchołków V i zbioru krawędzi E, jak pokazano poniżej:
G = (V, E)

Rysunek 10. Wykres
Powyższy rysunek przedstawia graf mający siedem wierzchołków A, B, C, D, E, F, G i dziesięć krawędzi [A, B], [A, C], [B, C], [B, D], [B, E], [C, D], [D, E], [D, F], [E, F] i [E, G].
W zależności od położenia wierzchołków i krawędzi grafy można podzielić na różne typy:
Niektóre zastosowania wykresów:
przypisy do przecen
- Wykresy pomagają nam przedstawiać trasy i sieci w zastosowaniach związanych z transportem, podróżami i komunikacją.
- Wykresy służą do wyświetlania tras w systemie GPS.
- Wykresy pomagają nam również przedstawić wzajemne połączenia w sieciach społecznościowych i innych aplikacjach sieciowych.
- Wykresy są wykorzystywane w aplikacjach mapujących.
- Wykresy odpowiadają za reprezentację preferencji użytkownika w aplikacjach e-commerce.
- Wykresy są również wykorzystywane w sieciach użyteczności publicznej w celu identyfikacji problemów, jakie stwarzają korporacje lokalne lub miejskie.
- Wykresy pomagają także zarządzać wykorzystaniem i dostępnością zasobów w organizacji.
- Wykresy są również wykorzystywane do tworzenia map łączy dokumentów w witrynach internetowych w celu przedstawienia powiązań między stronami za pomocą hiperłączy.
- Wykresy są również wykorzystywane w ruchach robotów i sieciach neuronowych.
Podstawowe operacje na strukturach danych
W poniższej sekcji omówimy różne typy operacji, które możemy wykonać w celu manipulowania danymi w każdej strukturze danych:
- Czas kompilacji
- Czas działania
Na przykład malloc() funkcja jest używana w języku C do tworzenia struktury danych.
Zrozumienie abstrakcyjnego typu danych
Zgodnie z Narodowy Instytut Standardów i Technologii (NIST) , struktura danych to układ informacji, zazwyczaj w pamięci, zapewniający lepszą wydajność algorytmu. Struktury danych obejmują połączone listy, stosy, kolejki, drzewa i słowniki. Mogą to być również jednostki teoretyczne, takie jak imię i nazwisko oraz adres osoby.
Z powyższej definicji wynika, że operacje na strukturze danych obejmują:
- Wysoki poziom abstrakcji, np. dodawanie lub usuwanie pozycji z listy.
- Wyszukiwanie i sortowanie elementu na liście.
- Dostęp do elementu o najwyższym priorytecie na liście.
Ilekroć struktura danych wykonuje takie operacje, nazywa się to Abstrakcyjny typ danych (ADT) .
Możemy go zdefiniować jako zbiór elementów danych wraz z operacjami na danych. Termin „abstrakcyjny” odnosi się do faktu, że dane i zdefiniowane na nich podstawowe operacje są badane niezależnie od ich implementacji. Obejmuje to, co możemy zrobić z danymi, a nie jak możemy to zrobić.
Implementacja ADI zawiera strukturę pamięci w celu przechowywania elementów danych i algorytmów dla podstawowych operacji. Wszystkie struktury danych, takie jak tablica, lista połączona, kolejka, stos itp., są przykładami ADT.
Zrozumienie zalet stosowania ADT
W prawdziwym świecie programy ewoluują w wyniku nowych ograniczeń lub wymagań, więc modyfikacja programu zazwyczaj wymaga zmiany w jednej lub wielu strukturach danych. Załóżmy na przykład, że chcemy wstawić nowe pole do rekordu pracownika, aby śledzić więcej szczegółów na temat każdego pracownika. W takim przypadku możemy poprawić wydajność programu, zastępując tablicę strukturą Linked. W takiej sytuacji przepisywanie każdej procedury wykorzystującej zmodyfikowaną strukturę jest niewłaściwe. Dlatego lepszą alternatywą jest oddzielenie struktury danych od informacji o jej implementacji. Na tej zasadzie opiera się użycie abstrakcyjnych typów danych (ADT).
Niektóre zastosowania struktur danych
Poniżej przedstawiono niektóre zastosowania struktur danych:
- Struktury danych pomagają w organizacji danych w pamięci komputera.
- Struktury danych pomagają również w reprezentowaniu informacji w bazach danych.
- Data Structures pozwala na implementację algorytmów przeszukiwania danych (np. wyszukiwarka).
- Możemy używać struktur danych do implementowania algorytmów manipulacji danymi (na przykład edytory tekstu).
- Możemy również zaimplementować algorytmy do analizy danych przy użyciu struktur danych (na przykład eksploratorów danych).
- Struktury danych obsługują algorytmy generowania danych (na przykład generator liczb losowych).
- Struktury danych obsługują również algorytmy kompresji i dekompresji danych (na przykład narzędzie zip).
- Możemy również używać struktur danych do implementowania algorytmów szyfrowania i deszyfrowania danych (na przykład system bezpieczeństwa).
- Za pomocą Data Structures możemy zbudować oprogramowanie zarządzające plikami i katalogami (na przykład menedżer plików).
- Możemy również opracować oprogramowanie, które może renderować grafikę przy użyciu struktur danych. (Na przykład przeglądarka internetowa lub oprogramowanie do renderowania 3D).
Oprócz nich, jak wspomniano wcześniej, istnieje wiele innych zastosowań struktur danych, które mogą pomóc nam w zbudowaniu dowolnego oprogramowania.