Co to jest pamięć podręczna LRU?
Algorytmy zastępowania pamięci podręcznej są skutecznie zaprojektowane do wymiany pamięci podręcznej, gdy miejsce jest pełne. The Najdawniej używane (LRU) jest jednym z tych algorytmów. Jak sama nazwa wskazuje, gdy pamięć podręczna jest pełna, LRU wybiera dane, które są ostatnio używane i usuwa je, aby zrobić miejsce na nowe dane. Priorytet danych w pamięci podręcznej zmienia się w zależności od zapotrzebowania na te dane, tj. jeśli jakieś dane zostały niedawno pobrane lub zaktualizowane, priorytet tych danych zostanie zmieniony i przypisany do najwyższego priorytetu, a priorytet danych maleje, jeśli pozostaje niewykorzystane operacje po operacjach.
Spis treści
- Co to jest pamięć podręczna LRU?
- Operacje na pamięci podręcznej LRU:
- Działanie pamięci podręcznej LRU:
- Sposoby implementacji pamięci podręcznej LRU:
- Implementacja pamięci podręcznej LRU przy użyciu kolejki i mieszania:
- Implementacja pamięci podręcznej LRU przy użyciu listy podwójnie połączonej i mieszania:
- Implementacja pamięci podręcznej LRU przy użyciu Deque i Hashmap:
- Implementacja pamięci podręcznej LRU przy użyciu Stack i Hashmap:
- Pamięć podręczna LRU wykorzystująca implementację licznika:
- Implementacja pamięci podręcznej LRU przy użyciu leniwych aktualizacji:
- Analiza złożoności pamięci podręcznej LRU:
- Zalety pamięci podręcznej LRU:
- Wady pamięci podręcznej LRU:
- Zastosowanie w świecie rzeczywistym pamięci podręcznej LRU:
LRU Algorytm jest problemem standardowym i może ulegać zmianom w zależności od potrzeb, na przykład w systemach operacyjnych LRU odgrywa kluczową rolę, ponieważ może być stosowany jako algorytm zastępowania stron w celu minimalizacji błędów stron.
Operacje na pamięci podręcznej LRU:
- LRUCache (pojemność c): Zainicjuj pamięć podręczną LRU o dodatniej pojemności C.
- Weź klucz) : Zwraca wartość klucza „ k’ jeśli jest obecny w pamięci podręcznej, w przeciwnym razie zwraca -1. Aktualizuje również priorytet danych w pamięci podręcznej LRU.
- umieść (klucz, wartość): Zaktualizuj wartość klucza, jeśli taki klucz istnieje. W przeciwnym razie dodaj parę klucz-wartość do pamięci podręcznej. Jeśli liczba kluczy przekroczyła pojemność pamięci podręcznej LRU, odrzuć ostatnio używany klucz.
Działanie pamięci podręcznej LRU:
Załóżmy, że mamy pamięć podręczną LRU o pojemności 3 i chcielibyśmy wykonać następujące operacje:
- Umieść (klucz=1, wartość=A) w pamięci podręcznej
- Umieść (klucz=2, wartość=B) w pamięci podręcznej
- Umieść (klucz=3, wartość=C) w pamięci podręcznej
- Pobierz (klucz=2) z pamięci podręcznej
- Pobierz (klucz=4) z pamięci podręcznej
- Umieść (klucz=4, wartość=D) w pamięci podręcznej
- Umieść (klucz=3, wartość=E) w pamięci podręcznej
- Pobierz (klucz=4) z pamięci podręcznej
- Umieść (klucz=1, wartość=A) w pamięci podręcznej
Powyższe operacje wykonywane są jedna po drugiej, jak pokazano na poniższym obrazku:
Szczegółowe wyjaśnienie każdej operacji:
- Put (klucz 1, wartość A) : Ponieważ pamięć podręczna LRU ma pustą pojemność = 3, nie ma potrzeby jej zastępowania i umieszczamy {1 : A} na górze, tj. {1 : A} ma najwyższy priorytet.
- Put (klucz 2, wartość B) : Ponieważ pamięć podręczna LRU ma pustą pojemność = 2, ponownie nie ma potrzeby wymiany, ale teraz {2 : B} ma najwyższy priorytet, a priorytet {1 : A} maleje.
- Put (klucz 3, wartość C) : Wciąż jest 1 wolne miejsce w pamięci podręcznej, dlatego wstaw {3 : C} bez żadnej zamiany, zauważ, że pamięć podręczna jest pełna, a bieżąca kolejność priorytetów od najwyższego do najniższego to {3:C}, {2:B }, {1:A}.
- Pobierz (klawisz 2) : Teraz podczas tej operacji zwróć wartość klucza=2, także dlatego, że używany jest klucz=2, teraz nowa kolejność priorytetów to {2:B}, {3:C}, {1:A}
- Uzyskaj (klawisz 4): Zauważ, że klucza 4 nie ma w pamięci podręcznej, dla tej operacji zwracamy „-1”.
- Put (klawisz 4, wartość D) : Zwróć uwagę, że pamięć podręczna jest PEŁNA, teraz użyj algorytmu LRU, aby określić, który klucz był ostatnio używany. Ponieważ {1:A} miał najmniejszy priorytet, usuń {1:A} z naszej pamięci podręcznej i umieść {4:D} w pamięci podręcznej. Zwróć uwagę, że nowa kolejność priorytetów to {4:D}, {2:B}, {3:C}
- Put (klawisz 3, wartość E) : Ponieważ klucz=3 był już obecny w pamięci podręcznej i miał wartość=C, więc ta operacja nie spowoduje usunięcia żadnego klucza, a raczej zaktualizuje wartość klucza=3 do „ I' . Teraz nowa kolejność priorytetów będzie wyglądać następująco: {3:E}, {4:D}, {2:B}
- Pobierz (klawisz 4) : Zwraca wartość klucza=4. Teraz nowym priorytetem będzie {4:D}, {3:E}, {2:B}
- Put (klucz 1, wartość A) : Ponieważ nasza pamięć podręczna jest PEŁNA, użyj naszego algorytmu LRU, aby określić, który klucz był ostatnio używany, a ponieważ klucz {2:B} miał najmniejszy priorytet, usuń {2:B} z naszej pamięci podręcznej i umieść {1:A} w Pamięć podręczna. Teraz nowa kolejność priorytetów to {1:A}, {4:D}, {3:E}
Sposoby implementacji pamięci podręcznej LRU:
Pamięć podręczną LRU można zaimplementować na różne sposoby, a każdy programista może wybrać inne podejście. Poniżej przedstawiono jednak powszechnie stosowane podejścia:
- LRU używający kolejki i haszowania
- Używanie LRU Lista podwójnie połączona + haszowanie
- LRU używający Deque
- LRU używający stosu
- Używanie LRU Implementacja licznika
- LRU używa leniwych aktualizacji
Implementacja pamięci podręcznej LRU przy użyciu kolejki i mieszania:
Do implementacji pamięci podręcznej LRU używamy dwóch struktur danych.
jak zamienić ciąg znaków na int
- Kolejka jest realizowany przy użyciu podwójnie połączonej listy. Maksymalny rozmiar kolejki będzie równy całkowitej liczbie dostępnych ramek (rozmiarowi pamięci podręcznej). Ostatnio używane strony będą znajdować się w przedniej części, a najrzadziej używane strony będą w tylnej części.
- Hash z numerem strony jako kluczem i adresem odpowiedniego węzła kolejki jako wartością.
Kiedy następuje odwołanie do strony, żądana strona może znajdować się w pamięci. Jeśli jest w pamięci, musimy odłączyć węzeł listy i przenieść go na początek kolejki.
Jeśli żądanej strony nie ma w pamięci, wprowadzamy ją do pamięci. Krótko mówiąc, dodajemy nowy węzeł na początek kolejki i aktualizujemy odpowiedni adres węzła w haszu. Jeżeli kolejka jest pełna, czyli wszystkie ramki są zajęte, usuwamy węzeł z końca kolejki, a nowy węzeł dodajemy na początek kolejki.
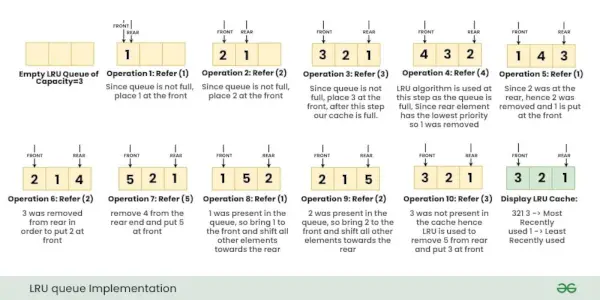
Ilustracja:
Rozważmy operacje, Odnosi się klucz X w pamięci podręcznej LRU: { 1, 2, 3, 4, 1, 2, 5, 1, 2, 3 }
Notatka: Początkowo w pamięci nie ma żadnej strony.Poniższe obrazy przedstawiają krok po kroku wykonanie powyższych operacji na pamięci podręcznej LRU.
Algorytm:
- Utwórz klasę LRUCache z deklaracją listy typów int, nieuporządkowanej mapy typów
- W funkcji refer LRUCache
- Jeśli tej wartości nie ma w kolejce, wypchnij tę wartość przed kolejkę i usuń ostatnią wartość, jeśli kolejka jest pełna
- Jeśli wartość już istnieje, usuń ją z kolejki i wypchnij na początek kolejki
- W funkcji wyświetlania wydrukuj LRUCache korzystając z kolejki zaczynając od przodu
Poniżej implementacja powyższego podejścia:
C++
// We can use stl container list as a double> // ended queue to store the cache keys, with> // the descending time of reference from front> // to back and a set container to check presence> // of a key. But to fetch the address of the key> // in the list using find(), it takes O(N) time.> // This can be optimized by storing a reference> // (iterator) to each key in a hash map.> #include> using> namespace> std;> > class> LRUCache {> >// store keys of cache> >list<>int>>dq;> > >// store references of key in cache> >unordered_map<>int>, list<>int>>::iterator> mam;> >int> csize;>// maximum capacity of cache> > public>:> >LRUCache(>int>);> >void> refer(>int>);> >void> display();> };> > // Declare the size> LRUCache::LRUCache(>int> n) { csize = n; }> > // Refers key x with in the LRU cache> void> LRUCache::refer(>int> x)> {> >// not present in cache> >if> (ma.find(x) == ma.end()) {> >// cache is full> >if> (dq.size() == csize) {> >// delete least recently used element> >int> last = dq.back();> > >// Pops the last element> >dq.pop_back();> > >// Erase the last> >ma.erase(last);> >}> >}> > >// present in cache> >else> >dq.erase(ma[x]);> > >// update reference> >dq.push_front(x);> >ma[x] = dq.begin();> }> > // Function to display contents of cache> void> LRUCache::display()> {> > >// Iterate in the deque and print> >// all the elements in it> >for> (>auto> it = dq.begin(); it != dq.end(); it++)> >cout << (*it) <<>' '>;> > >cout << endl;> }> > // Driver Code> int> main()> {> >LRUCache ca(4);> > >ca.refer(1);> >ca.refer(2);> >ca.refer(3);> >ca.refer(1);> >ca.refer(4);> >ca.refer(5);> >ca.display();> > >return> 0;> }> // This code is contributed by Satish Srinivas> |
>
>
C
// A C program to show implementation of LRU cache> #include> #include> > // A Queue Node (Queue is implemented using Doubly Linked> // List)> typedef> struct> QNode {> >struct> QNode *prev, *next;> >unsigned> >pageNumber;>// the page number stored in this QNode> } QNode;> > // A Queue (A FIFO collection of Queue Nodes)> typedef> struct> Queue {> >unsigned count;>// Number of filled frames> >unsigned numberOfFrames;>// total number of frames> >QNode *front, *rear;> } Queue;> > // A hash (Collection of pointers to Queue Nodes)> typedef> struct> Hash {> >int> capacity;>// how many pages can be there> >QNode** array;>// an array of queue nodes> } Hash;> > // A utility function to create a new Queue Node. The queue> // Node will store the given 'pageNumber'> QNode* newQNode(unsigned pageNumber)> {> >// Allocate memory and assign 'pageNumber'> >QNode* temp = (QNode*)>malloc>(>sizeof>(QNode));> >temp->numer strony = numer strony;> > >// Initialize prev and next as NULL> >temp->prev = temp->next = NULL;> > >return> temp;> }> > // A utility function to create an empty Queue.> // The queue can have at most 'numberOfFrames' nodes> Queue* createQueue(>int> numberOfFrames)> {> >Queue* queue = (Queue*)>malloc>(>sizeof>(Queue));> > >// The queue is empty> >queue->liczba = 0;> >queue->przód = kolejka->tył = NULL;> > >// Number of frames that can be stored in memory> >queue->liczbaRamek = liczbaRamek;> > >return> queue;> }> > // A utility function to create an empty Hash of given> // capacity> Hash* createHash(>int> capacity)> {> >// Allocate memory for hash> >Hash* hash = (Hash*)>malloc>(>sizeof>(Hash));> >hash->pojemność = pojemność;> > >// Create an array of pointers for referring queue nodes> >hash->tablica> >= (QNode**)>malloc>(hash->pojemność *>sizeof>(QNode*));> > >// Initialize all hash entries as empty> >int> i;> >for> (i = 0; i capacity; ++i)> >hash->tablica[i] = NULL;> > >return> hash;> }> > // A function to check if there is slot available in memory> int> AreAllFramesFull(Queue* queue)> {> >return> queue->liczba == kolejka->numberOfFrames;> }> > // A utility function to check if queue is empty> int> isQueueEmpty(Queue* queue)> {> >return> queue->tył == NULL;> }> > // A utility function to delete a frame from queue> void> deQueue(Queue* queue)> {> >if> (isQueueEmpty(queue))> >return>;> > >// If this is the only node in list, then change front> >if> (queue->przód == kolejka->tył)> >queue->przód = NULL;> > >// Change rear and remove the previous rear> >QNode* temp = queue->tył;> >queue->tył = kolejka->tył->poprzednia;> > >if> (queue->tył)> >queue->tył->następny = NULL;> > >free>(temp);> > >// decrement the number of full frames by 1> >queue->liczyć--;> }> > // A function to add a page with given 'pageNumber' to both> // queue and hash> void> Enqueue(Queue* queue, Hash* hash, unsigned pageNumber)> {> >// If all frames are full, remove the page at the rear> >if> (AreAllFramesFull(queue)) {> >// remove page from hash> >hash->tablica[kolejka->tył->numer strony] = NULL;> >deQueue(queue);> >}> > >// Create a new node with given page number,> >// And add the new node to the front of queue> >QNode* temp = newQNode(pageNumber);> >temp->następny = kolejka->przód;> > >// If queue is empty, change both front and rear> >// pointers> >if> (isQueueEmpty(queue))> >queue->tył = kolejka-> przód = temp;> >else> // Else change the front> >{> >queue->przód->poprzednia = temp;> >queue->przód = temperatura;> >}> > >// Add page entry to hash also> >hash->tablica[numer strony] = temp;> > >// increment number of full frames> >queue->liczyć++;> }> > // This function is called when a page with given> // 'pageNumber' is referenced from cache (or memory). There> // are two cases:> // 1. Frame is not there in memory, we bring it in memory> // and add to the front of queue> // 2. Frame is there in memory, we move the frame to front> // of queue> void> ReferencePage(Queue* queue, Hash* hash,> >unsigned pageNumber)> {> >QNode* reqPage = hash->tablica[numer strony];> > >// the page is not in cache, bring it> >if> (reqPage == NULL)> >Enqueue(queue, hash, pageNumber);> > >// page is there and not at front, change pointer> >else> if> (reqPage != queue->z przodu) {> >// Unlink rquested page from its current location> >// in queue.> >reqPage->prev->next = reqPage->next;> >if> (reqPage->następny)> >reqPage->następny->poprzedni = reqPage->poprzedni;> > >// If the requested page is rear, then change rear> >// as this node will be moved to front> >if> (reqPage == queue->tył) {> >queue->tył = reqPage->poprzednia;> >queue->tył->następny = NULL;> >}> > >// Put the requested page before current front> >reqPage->następny = kolejka->przód;> >reqPage->poprzedni = NULL;> > >// Change prev of current front> >reqPage->następny->poprzedni = reqPage;> > >// Change front to the requested page> >queue->przód = wymagana strona;> >}> }> > // Driver code> int> main()> {> >// Let cache can hold 4 pages> >Queue* q = createQueue(4);> > >// Let 10 different pages can be requested (pages to be> >// referenced are numbered from 0 to 9> >Hash* hash = createHash(10);> > >// Let us refer pages 1, 2, 3, 1, 4, 5> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 2);> >ReferencePage(q, hash, 3);> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 4);> >ReferencePage(q, hash, 5);> > >// Let us print cache frames after the above referenced> >// pages> >printf>(>'%d '>, q->przód->numer strony);> >printf>(>'%d '>, q->przód->następna->numer strony);> >printf>(>'%d '>, q->przód->następny->następny->numer strony);> >printf>(>'%d '>, q->przód->następny->następny->następny->numer strony);> > >return> 0;> }> |
>
>
Jawa
/* We can use Java inbuilt Deque as a double> >ended queue to store the cache keys, with> >the descending time of reference from front> >to back and a set container to check presence> >of a key. But remove a key from the Deque using> >remove(), it takes O(N) time. This can be> >optimized by storing a reference (iterator) to> >each key in a hash map. */> import> java.util.Deque;> import> java.util.HashSet;> import> java.util.Iterator;> import> java.util.LinkedList;> > public> class> LRUCache {> > >// store keys of cache> >private> Deque doublyQueue;> > >// store references of key in cache> >private> HashSet hashSet;> > >// maximum capacity of cache> >private> final> int> CACHE_SIZE;> > >LRUCache(>int> capacity)> >{> >doublyQueue =>new> LinkedList();> >hashSet =>new> HashSet();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> refer(>int> page)> >{> >if> (!hashSet.contains(page)) {> >if> (doublyQueue.size() == CACHE_SIZE) {> >int> last = doublyQueue.removeLast();> >hashSet.remove(last);> >}> >}> >else> {>/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.remove(page);> >}> >doublyQueue.push(page);> >hashSet.add(page);> >}> > >// display contents of cache> >public> void> display()> >{> >Iterator itr = doublyQueue.iterator();> >while> (itr.hasNext()) {> >System.out.print(itr.next() +>' '>);> >}> >}> > >// Driver code> >public> static> void> main(String[] args)> >{> >LRUCache cache =>new> LRUCache(>4>);> >cache.refer(>1>);> >cache.refer(>2>);> >cache.refer(>3>);> >cache.refer(>1>);> >cache.refer(>4>);> >cache.refer(>5>);> >cache.display();> >}> }> // This code is contributed by Niraj Kumar> |
>
>
Python3
# We can use stl container list as a double> # ended queue to store the cache keys, with> # the descending time of reference from front> # to back and a set container to check presence> # of a key. But to fetch the address of the key> # in the list using find(), it takes O(N) time.> # This can be optimized by storing a reference> # (iterator) to each key in a hash map.> class> LRUCache:> ># store keys of cache> >def> __init__(>self>, n):> >self>.csize>=> n> >self>.dq>=> []> >self>.ma>=> {}> > > ># Refers key x with in the LRU cache> >def> refer(>self>, x):> > ># not present in cache> >if> x>not> in> self>.ma.keys():> ># cache is full> >if> len>(>self>.dq)>=>=> self>.csize:> ># delete least recently used element> >last>=> self>.dq[>->1>]> > ># Pops the last element> >ele>=> self>.dq.pop();> > ># Erase the last> >del> self>.ma[last]> > ># present in cache> >else>:> >del> self>.dq[>self>.ma[x]]> > ># update reference> >self>.dq.insert(>0>, x)> >self>.ma[x]>=> 0>;> > ># Function to display contents of cache> >def> display(>self>):> > ># Iterate in the deque and print> ># all the elements in it> >print>(>self>.dq)> > # Driver Code> ca>=> LRUCache(>4>)> > ca.refer(>1>)> ca.refer(>2>)> ca.refer(>3>)> ca.refer(>1>)> ca.refer(>4>)> ca.refer(>5>)> ca.display()> # This code is contributed by Satish Srinivas> |
>
>
do metody string w Javie
C#
// C# program to implement the approach> > using> System;> using> System.Collections.Generic;> > class> LRUCache {> >// store keys of cache> >private> List<>int>>podwójnieKolejka;> > >// store references of key in cache> >private> HashSet<>int>>zestaw skrótów;> > >// maximum capacity of cache> >private> int> CACHE_SIZE;> > >public> LRUCache(>int> capacity)> >{> >doublyQueue =>new> List<>int>>();> >hashSet =>new> HashSet<>int>>();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> Refer(>int> page)> >{> >if> (!hashSet.Contains(page)) {> >if> (doublyQueue.Count == CACHE_SIZE) {> >int> last> >= doublyQueue[doublyQueue.Count - 1];> >doublyQueue.RemoveAt(doublyQueue.Count - 1);> >hashSet.Remove(last);> >}> >}> >else> {> >/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.Remove(page);> >}> >doublyQueue.Insert(0, page);> >hashSet.Add(page);> >}> > >// display contents of cache> >public> void> Display()> >{> >foreach>(>int> page>in> doublyQueue)> >{> >Console.Write(page +>' '>);> >}> >}> > >// Driver code> >static> void> Main(>string>[] args)> >{> >LRUCache cache =>new> LRUCache(4);> >cache.Refer(1);> >cache.Refer(2);> >cache.Refer(3);> >cache.Refer(1);> >cache.Refer(4);> >cache.Refer(5);> >cache.Display();> >}> }> > // This code is contributed by phasing17> |
>
>
JavaScript
// JS code to implement the approach> class LRUCache {> >constructor(n) {> >this>.csize = n;> >this>.dq = [];> >this>.ma =>new> Map();> >}> > >refer(x) {> >if> (!>this>.ma.has(x)) {> >if> (>this>.dq.length ===>this>.csize) {> >const last =>this>.dq[>this>.dq.length - 1];> >this>.dq.pop();> >this>.ma.>delete>(last);> >}> >}>else> {> >this>.dq.splice(>this>.dq.indexOf(x), 1);> >}> > >this>.dq.unshift(x);> >this>.ma.set(x, 0);> >}> > >display() {> >console.log(>this>.dq);> >}> }> > const cache =>new> LRUCache(4);> > cache.refer(1);> cache.refer(2);> cache.refer(3);> cache.refer(1);> cache.refer(4);> cache.refer(5);> cache.display();> > // This code is contributed by phasing17> |
>
>
Implementacja pamięci podręcznej LRU przy użyciu listy podwójnie połączonej i mieszania :
Pomysł jest bardzo prosty, czyli wkładać elementy od strony głowy.
- jeżeli elementu nie ma na liście to dodaj go na początek listy
- jeśli element znajduje się na liście to przesuń element na początek i przesuń pozostały element listy
Należy pamiętać, że priorytet węzła będzie zależał od odległości tego węzła od głowy, im najbliższy węzeł znajduje się od głowy, tym wyższy jest jego priorytet. Kiedy więc pamięć podręczna jest pełna i musimy usunąć jakiś element, usuwamy element sąsiadujący z końcem podwójnie połączonej listy.
Implementacja pamięci podręcznej LRU przy użyciu Deque i Hashmap:
Struktura danych Deque umożliwia wstawianie i usuwanie zarówno od przodu, jak i od końca, ta właściwość umożliwia implementację LRU, ponieważ element przedni może reprezentować element o wysokim priorytecie, podczas gdy element końcowy może być elementem o niskim priorytecie, tj. Najmniej ostatnio używanym.
Pracujący:
- Uzyskaj operację : Sprawdza, czy klucz istnieje na mapie skrótów pamięci podręcznej i postępuj zgodnie z poniższymi przypadkami w deque:
- Jeśli klucz zostanie znaleziony:
- Przedmiot uważa się za ostatnio używany, dlatego przesuwa się go na przód deque.
- Wartość powiązana z kluczem jest zwracana jako wynik
get>operacja.- Jeśli klucz nie zostanie znaleziony:
- return -1, aby wskazać, że taki klucz nie istnieje.
- Umieść operację: Najpierw sprawdź, czy klucz już istnieje na mapie skrótów pamięci podręcznej i postępuj zgodnie z poniższymi przypadkami na deque
- Jeśli klucz istnieje:
- Wartość powiązana z kluczem zostanie zaktualizowana.
- Przedmiot zostaje przesunięty na przód deque, ponieważ jest teraz ostatnio używany.
- Jeśli klucz nie istnieje:
- Jeśli pamięć podręczna jest pełna, oznacza to, że należy włożyć nowy element i usunąć ostatnio używany element. Odbywa się to poprzez usunięcie elementu z końca deque i odpowiedniego wpisu z mapy skrótów.
- Nowa para klucz-wartość jest następnie wstawiana zarówno do mapy skrótów, jak i na przód deque, aby zaznaczyć, że jest to ostatnio używany element
Implementacja pamięci podręcznej LRU przy użyciu Stack i Hashmap:
Implementowanie pamięci podręcznej LRU (najmniej ostatnio używanej) przy użyciu struktury danych stosu i mieszania może być nieco trudne, ponieważ prosty stos nie zapewnia wydajnego dostępu do ostatnio używanego elementu. Można jednak połączyć stos z mapą skrótów, aby osiągnąć to efektywnie. Oto zaawansowane podejście do jego wdrożenia:
- Użyj mapy mieszającej : Mapa mieszająca będzie przechowywać pary klucz-wartość pamięci podręcznej. Klucze zostaną przypisane do odpowiednich węzłów na stosie.
- Użyj stosu : Stos zachowa kolejność kluczy w oparciu o ich użycie. Najrzadziej używany przedmiot będzie na dole stosu, a ostatnio używany przedmiot będzie na górze
Ta metoda nie jest zbyt skuteczna i dlatego nie jest często stosowana.
Pamięć podręczna LRU wykorzystująca implementację licznika:
Każdy blok w pamięci podręcznej będzie miał swój własny licznik LRU, do którego należy wartość licznika {0 do n-1} , Tutaj ' N „ oznacza rozmiar pamięci podręcznej. Blok zmieniony podczas wymiany bloku staje się blokiem MRU, w wyniku czego wartość jego licznika zostaje zmieniona na n – 1. Wartości liczników większe niż wartość licznika dostępnego bloku są zmniejszane o jeden. Pozostałe bloki pozostają bez zmian.
| Wartość Contera | Priorytet | Stan używany |
|---|---|---|
| 0 | Niski | Najdawniej używane łączenie w przód |
| n-1 | Wysoki | Ostatnio używane |
Implementacja pamięci podręcznej LRU przy użyciu leniwych aktualizacji:
Implementowanie pamięci podręcznej LRU (najmniej ostatnio używanej) przy użyciu leniwych aktualizacji jest powszechną techniką poprawiającą wydajność operacji pamięci podręcznej. Leniwe aktualizacje polegają na śledzeniu kolejności uzyskiwania dostępu do elementów bez natychmiastowej aktualizacji całej struktury danych. W przypadku braku pamięci podręcznej możesz zdecydować, czy przeprowadzić pełną aktualizację, w oparciu o pewne kryteria.
Analiza złożoności pamięci podręcznej LRU:
- Złożoność czasowa:
- Operacja Put(): O(1), czyli czas potrzebny na wstawienie lub aktualizację nowej pary klucz-wartość jest stały
- Operacja Get(): O(1), czyli czas potrzebny na pobranie wartości klucza jest stały
- Przestrzeń pomocnicza: O(N) gdzie N jest pojemnością pamięci podręcznej.
Zalety pamięci podręcznej LRU:
- Szybki dostęp : Dostęp do danych z pamięci podręcznej LRU zajmuje czas O(1).
- Szybka aktualizacja : Aktualizacja pary klucz-wartość w pamięci podręcznej LRU zajmuje czas O(1).
- Szybkie usuwanie ostatnio używanych danych : Wymaga O(1) usunięcia tego, co nie było ostatnio używane.
- Bez bicia: LRU jest mniej podatny na rzucanie w porównaniu do FIFO, ponieważ uwzględnia historię użytkowania stron. Potrafi wykryć, które strony są często używane i nadać im priorytet przydziału pamięci, redukując liczbę błędów stron i operacji we/wy dysku.
Wady pamięci podręcznej LRU:
- Wymaga dużego rozmiaru pamięci podręcznej, aby zwiększyć wydajność.
- Wymaga wdrożenia dodatkowej Struktury Danych.
- Pomoc sprzętowa jest wysoka.
- W LRU wykrywanie błędów jest trudne w porównaniu do innych algorytmów.
- Ma ograniczoną akceptowalność.
Zastosowanie w świecie rzeczywistym pamięci podręcznej LRU:
- W systemach baz danych, aby uzyskać szybkie wyniki zapytań.
- W systemach operacyjnych, aby zminimalizować błędy stron.
- Edytory tekstu i IDE do przechowywania często używanych plików lub fragmentów kodu
- Routery i przełączniki sieciowe wykorzystują LRU w celu zwiększenia wydajności sieci komputerowej
- W optymalizacjach kompilatora
- Narzędzia do przewidywania tekstu i autouzupełniania