Moduł Pandas zawiera różne funkcje umożliwiające wykonywanie różnych operacji na ramkach danych, takich jak łączenie, łączenie, usuwanie, dodawanie itp. W tym artykule omówimy różne typy operacji łączenia, które można wykonać na Pandach Ramka danych. Istnieje pięć typów złączeń Pandy .
- Połączenie wewnętrzne
- Lewe połączenie zewnętrzne
- Prawe połączenie zewnętrzne
- Pełne łączenie zewnętrzne lub po prostu łączenie zewnętrzne
- Indeks Dołącz
Aby zrozumieć różne typy złączeń, najpierw utworzymy dwie ramki danych, a mianowicie A I B .
Ramka danych:
tablica vs lista tablic
Python3
# importing pandas> import> pandas as pd> # Creating dataframe a> a>=> pd.DataFrame()> # Creating Dictionary> d>=> {>'id'>: [>1>,>2>,>10>,>12>],> >'val1'>: [>'a'>,>'b'>,>'c'>,>'d'>]}> a>=> pd.DataFrame(d)> # printing the dataframe> a> |
>
>
Wyjście:
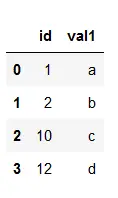
Ramka danych b:
Python3
# importing pandas> import> pandas as pd> # Creating dataframe b> b>=> pd.DataFrame()> # Creating dictionary> d>=> {>'id'>: [>1>,>2>,>9>,>8>],> >'val1'>: [>'p'>,>'q'>,>'r'>,>'s'>]}> b>=> pd.DataFrame(d)> # printing the dataframe> b> |
>
>
Wyjście:
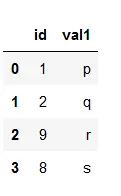
Rodzaje złączeń w Pandach
Użyjemy tych dwóch ramek danych, aby zrozumieć różne typy złączeń.
Pandy Połączenie wewnętrzne
Sprzężenie wewnętrzne jest najczęstszym rodzajem złączenia, z którym będziesz pracować. Zwraca ramkę danych zawierającą tylko te wiersze, które mają wspólne cechy. Przypomina to przecięcie dwóch zbiorów.
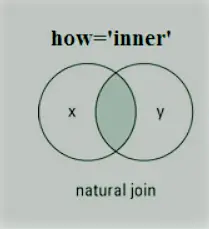
Przykład:
Python3
Zainicjuj listę Pythona
# importing pandas> import> pandas as pd> # Creating dataframe a> a>=> pd.DataFrame()> # Creating Dictionary> d>=> {>'id'>: [>1>,>2>,>10>,>12>],> >'val1'>: [>'a'>,>'b'>,>'c'>,>'d'>]}> a>=> pd.DataFrame(d)> # Creating dataframe b> b>=> pd.DataFrame()> # Creating dictionary> d>=> {>'id'>: [>1>,>2>,>9>,>8>],> >'val1'>: [>'p'>,>'q'>,>'r'>,>'s'>]}> b>=> pd.DataFrame(d)> # inner join> df>=> pd.merge(a, b, on>=>'id'>, how>=>'inner'>)> # display dataframe> df> |
>
>
Wyjście:

Pandy Lewe dołączenie
W przypadku lewego sprzężenia zewnętrznego zostaną wyświetlone wszystkie rekordy z pierwszej ramki danych, niezależnie od tego, czy klucze z pierwszej ramki danych można znaleźć w drugiej ramce danych. Natomiast w przypadku drugiej ramki danych zostaną wyświetlone tylko rekordy z kluczami z drugiej ramki danych, które można znaleźć w pierwszej ramce danych.
 Przykład:
Przykład:
Python3
# importing pandas> import> pandas as pd> # Creating dataframe a> a>=> pd.DataFrame()> # Creating Dictionary> d>=> {>'id'>: [>1>,>2>,>10>,>12>],> >'val1'>: [>'a'>,>'b'>,>'c'>,>'d'>]}> a>=> pd.DataFrame(d)> # Creating dataframe b> b>=> pd.DataFrame()> # Creating dictionary> d>=> {>'id'>: [>1>,>2>,>9>,>8>],> >'val1'>: [>'p'>,>'q'>,>'r'>,>'s'>]}> b>=> pd.DataFrame(d)> # left outer join> df>=> pd.merge(a, b, on>=>'id'>, how>=>'left'>)> # display dataframe> df> |
>
>
Wyjście:

Pandy Prawe połączenie zewnętrzne
W przypadku prawego złączenia zostaną wyświetlone wszystkie rekordy z drugiej ramki danych. Jednakże zostaną wyświetlone tylko rekordy z kluczami w pierwszej ramce danych, które można znaleźć w drugiej ramce danych.

Przykład:
Python3
wydruk Javy
# importing pandas> import> pandas as pd> # Creating dataframe a> a>=> pd.DataFrame()> # Creating Dictionary> d>=> {>'id'>: [>1>,>2>,>10>,>12>],> >'val1'>: [>'a'>,>'b'>,>'c'>,>'d'>]}> a>=> pd.DataFrame(d)> # Creating dataframe b> b>=> pd.DataFrame()> # Creating dictionary> d>=> {>'id'>: [>1>,>2>,>9>,>8>],> >'val1'>: [>'p'>,>'q'>,>'r'>,>'s'>]}> b>=> pd.DataFrame(d)> # right outer join> df>=> pd.merge(a, b, on>=>'id'>, how>=>'right'>)> # display dataframe> df> |
>
>
Wyjście:

Pandy Pełne połączenie zewnętrzne
Pełne sprzężenie zewnętrzne zwraca wszystkie wiersze z lewej ramki danych i wszystkie wiersze z prawej ramki danych oraz dopasowuje wiersze, jeśli to możliwe, z NaN w innym miejscu. Ale jeśli ramka danych jest kompletna, otrzymamy ten sam wynik.

Przykład:
Python3
# importing pandas> import> pandas as pd> # Creating dataframe a> a>=> pd.DataFrame()> # Creating Dictionary> d>=> {>'id'>: [>1>,>2>,>10>,>12>],> >'val1'>: [>'a'>,>'b'>,>'c'>,>'d'>]}> a>=> pd.DataFrame(d)> # Creating dataframe b> b>=> pd.DataFrame()> # Creating dictionary> d>=> {>'id'>: [>1>,>2>,>9>,>8>],> >'val1'>: [>'p'>,>'q'>,>'r'>,>'s'>]}> b>=> pd.DataFrame(d)> # full outer join> df>=> pd.merge(a, b, on>=>'id'>, how>=>'outer'>)> # display dataframe> df> |
>
>
Wyjście:

Dołącz do indeksu Pand
Aby scalić ramkę danych z indeksami, przekaż lewy_indeks I prawy_indeks argumenty jako True, tj. obie ramki danych są łączone w indeksie przy użyciu domyślnego łączenia wewnętrznego.
Python3
# importing pandas> import> pandas as pd> # Creating dataframe a> a>=> pd.DataFrame()> # Creating Dictionary> d>=> {>'id'>: [>1>,>2>,>10>,>12>],> >'val1'>: [>'a'>,>'b'>,>'c'>,>'d'>]}> a>=> pd.DataFrame(d)> # Creating dataframe b> b>=> pd.DataFrame()> # Creating dictionary> d>=> {>'id'>: [>1>,>2>,>9>,>8>],> >'val1'>: [>'p'>,>'q'>,>'r'>,>'s'>]}> b>=> pd.DataFrame(d)> # index join> df>=> pd.merge(a, b, left_index>=>True>, right_index>=>True>)> # display dataframe> df> |
>
>
wyszukiwanie BFS
Wyjście:
