W tym artykule omówimy algorytm BFS w strukturze danych. Przeszukiwanie wszerz to algorytm przechodzenia przez graf, który rozpoczyna przechodzenie przez graf od węzła głównego i bada wszystkie sąsiednie węzły. Następnie wybiera najbliższy węzeł i bada wszystkie niezbadane węzły. Podczas korzystania z BFS do przechodzenia każdy węzeł na wykresie można uznać za węzeł główny.
Istnieje wiele sposobów poruszania się po grafie, ale wśród nich najczęściej stosowanym podejściem jest BFS. Jest to algorytm rekurencyjny przeszukujący wszystkie wierzchołki struktury danych drzewa lub wykresu. BFS dzieli każdy wierzchołek wykresu na dwie kategorie – odwiedzony i nieodwiedzony. Wybiera pojedynczy węzeł na grafie, a następnie odwiedza wszystkie węzły sąsiadujące z wybranym węzłem.
Zastosowania algorytmu BFS
Zastosowania algorytmu „najpierw szerokość” są następujące:
- BFS można wykorzystać do znalezienia sąsiadujących lokalizacji z danej lokalizacji źródłowej.
- W sieci peer-to-peer algorytm BFS może służyć jako metoda przechodzenia w celu znalezienia wszystkich sąsiadujących węzłów. Większość klientów torrent, takich jak BitTorrent, uTorrent itp., wykorzystuje ten proces do wyszukiwania „nasion” i „równików” w sieci.
- BFS może być używany w robotach sieciowych do tworzenia indeksów stron internetowych. Jest to jeden z głównych algorytmów, które można wykorzystać do indeksowania stron internetowych. Rozpoczyna przeglądanie od strony źródłowej i podąża za linkami powiązanymi ze stroną. W tym przypadku każda strona internetowa jest traktowana jako węzeł na wykresie.
- BFS służy do określenia najkrótszej ścieżki i minimalnego drzewa rozpinającego.
- BFS jest również używany w technice Cheneya do powielania zbierania śmieci.
- Można ją zastosować w metodzie Forda-Fulkersona do obliczenia maksymalnego przepływu w sieci przepływowej.
Algorytm
Etapy algorytmu BFS służące do eksploracji wykresu są następujące:
Krok 1: SET STATUS = 1 (stan gotowości) dla każdego węzła w G
rodzeństwo Kylie Jenner
Krok 2: Umieść w kolejce węzeł początkowy A i ustaw jego STATUS = 2 (stan oczekiwania)
Krok 3: Powtarzaj kroki 4 i 5, aż KOLEJKA będzie pusta
Krok 4: Usuń z kolejki węzeł N. Przetwórz go i ustaw jego STATUS = 3 (stan przetworzony).
Krok 5: Umieść w kolejce wszystkich sąsiadów N, którzy są w stanie gotowości (których STATUS = 1) i ustaw
ich STATUS = 2
klucz podstawowy klucz złożony
(stan oczekiwania)
[KONIEC PĘTLI]
Krok 6: WYJŚCIE
Przykład algorytmu BFS
Teraz zrozummy działanie algorytmu BFS na przykładzie. W poniższym przykładzie mamy graf skierowany mający 7 wierzchołków.
dialekt hibernacji
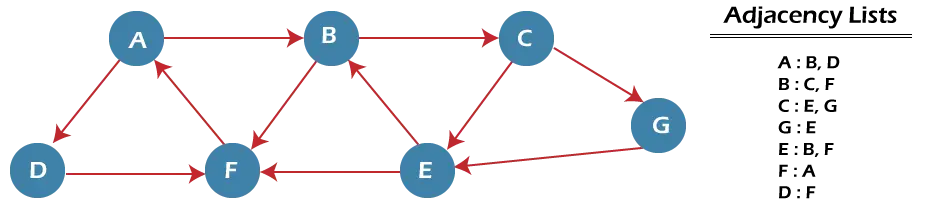
Na powyższym wykresie minimalną ścieżkę „P” można znaleźć, korzystając z BFS, który zaczyna się od węzła A i kończy na węźle E. Algorytm wykorzystuje dwie kolejki, mianowicie QUEUE1 i QUEUE2. KOLEJKA 1 zawiera wszystkie węzły, które mają zostać przetworzone, podczas gdy KOLEJKA 2 zawiera wszystkie węzły, które są przetwarzane i usuwane z KOLEJKI 1.
Teraz zacznijmy analizować wykres, zaczynając od węzła A.
Krok 1 - Najpierw dodaj A do kolejki 1 i NULL do kolejki 2.
QUEUE1 = {A} QUEUE2 = {NULL} Krok 2 - Teraz usuń węzeł A z kolejki 1 i dodaj go do kolejki 2. Wstaw wszystkich sąsiadów węzła A do kolejki 1.
QUEUE1 = {B, D} QUEUE2 = {A} Krok 3 - Teraz usuń węzeł B z kolejki 1 i dodaj go do kolejki 2. Wstaw wszystkich sąsiadów węzła B do kolejki 1.
anakonda kontra wąż pyton
QUEUE1 = {D, C, F} QUEUE2 = {A, B} Krok 4 - Teraz usuń węzeł D z kolejki 1 i dodaj go do kolejki 2. Wstaw wszystkich sąsiadów węzła D do kolejki 1. Jedynym sąsiadem węzła D jest F, ponieważ jest on już wstawiony, więc nie zostanie wstawiony ponownie.
QUEUE1 = {C, F} QUEUE2 = {A, B, D} Krok 5 - Usuń węzeł C z kolejki 1 i dodaj go do kolejki 2. Wstaw wszystkich sąsiadów węzła C do kolejki 1.
Algorytm sortowania przez scalanie
QUEUE1 = {F, E, G} QUEUE2 = {A, B, D, C} Krok 5 - Usuń węzeł F z kolejki 1 i dodaj go do kolejki 2. Wstaw wszystkich sąsiadów węzła F do kolejki 1. Ponieważ wszyscy sąsiedzi węzła F są już obecni, nie będziemy ich ponownie wstawiać.
QUEUE1 = {E, G} QUEUE2 = {A, B, D, C, F} Krok 6 - Usuń węzeł E z kolejki 1. Ponieważ wszyscy jego sąsiedzi zostali już dodani, więc nie będziemy ich ponownie wstawiać. Teraz odwiedzane są wszystkie węzły, a węzeł docelowy E zostaje napotkany w kolejce 2.
QUEUE1 = {G} QUEUE2 = {A, B, D, C, F, E} Złożoność algorytmu BFS
Złożoność czasowa BFS zależy od struktury danych użytej do przedstawienia wykresu. Złożoność czasowa algorytmu BFS wynosi O(V+E) , ponieważ w najgorszym przypadku algorytm BFS bada każdy węzeł i krawędź. W grafie liczba wierzchołków wynosi O(V), natomiast liczba krawędzi to O(E).
Złożoność przestrzenną BFS można wyrazić jako O(V) , gdzie V jest liczbą wierzchołków.
Implementacja algorytmu BFS
Przyjrzyjmy się teraz implementacji algorytmu BFS w Javie.
W tym kodzie używamy listy sąsiedztwa do przedstawienia naszego wykresu. Implementacja algorytmu wyszukiwania wszerz w Javie znacznie ułatwia radzenie sobie z listą sąsiedztwa, ponieważ musimy przeglądać listę węzłów dołączonych do każdego węzła dopiero wtedy, gdy węzeł zostanie usunięty z początku (lub początku) kolejki.
W tym przykładzie wykres, którego używamy do zademonstrowania kodu, wygląda następująco:

import java.io.*; import java.util.*; public class BFSTraversal { private int vertex; /* total number number of vertices in the graph */ private LinkedList adj[]; /* adjacency list */ private Queue que; /* maintaining a queue */ BFSTraversal(int v) { vertex = v; adj = new LinkedList[vertex]; for (int i=0; i<v; i++) { adj[i]="new" linkedlist(); } que="new" void insertedge(int v,int w) adj[v].add(w); * adding an edge to the adjacency list (edges are bidirectional in this example) bfs(int n) boolean nodes[]="new" boolean[vertex]; initialize array for holding data int a="0;" nodes[n]="true;" que.add(n); root node is added top of queue while (que.size() !="0)" n="que.poll();" remove element system.out.print(n+' '); print (int i="0;" < adj[n].size(); iterate through linked and push all neighbors into if (!nodes[a]) only insert nodes they have not been explored already nodes[a]="true;" que.add(a); public static main(string args[]) bfstraversal graph="new" bfstraversal(10); graph.insertedge(0, 1); 2); 3); graph.insertedge(1, graph.insertedge(2, 4); graph.insertedge(3, 5); 6); graph.insertedge(4, 7); graph.insertedge(5, graph.insertedge(6, graph.insertedge(7, 8); system.out.println('breadth first traversal is:'); graph.bfs(2); pre> <p> <strong>Output</strong> </p> <img src="//techcodeview.com/img/ds-tutorial/64/bfs-algorithm-3.webp" alt="Breadth First Search Algorithm"> <h3>Conclusion</h3> <p>In this article, we have discussed the Breadth-first search technique along with its example, complexity, and implementation in java programming language. Here, we have also seen the real-life applications of BFS that show it the important data structure algorithm.</p> <p>So, that's all about the article. Hope, it will be helpful and informative to you.</p> <hr></v;>