Wyszukiwanie bez informacji to klasa algorytmów wyszukiwania ogólnego przeznaczenia, które działają w sposób brutalny. Niedoinformowane algorytmy wyszukiwania nie mają dodatkowych informacji o stanie lub przestrzeni poszukiwań innych niż sposób przechodzenia przez drzewo, dlatego nazywa się to również wyszukiwaniem na ślepo.
Poniżej przedstawiono różne typy algorytmów wyszukiwania niedoinformowanego:
1. Wyszukiwanie wszerz:
- Przeszukiwanie wszerz jest najczęstszą strategią wyszukiwania przy przechodzeniu przez drzewo lub wykres. Algorytm ten przeszukuje drzewo lub wykres wszerz, dlatego nazywa się to przeszukiwaniem wszerz.
- Algorytm BFS rozpoczyna wyszukiwanie od węzła głównego drzewa i rozwija wszystkie węzły następcze na bieżącym poziomie przed przejściem do węzłów następnego poziomu.
- Algorytm przeszukiwania wszerz jest przykładem algorytmu przeszukiwania wykresu ogólnego.
- Przeszukiwanie wszerz zaimplementowane przy użyciu struktury danych kolejki FIFO.
Zalety:
- BFS zapewni rozwiązanie, jeśli takie istnieje.
- Jeśli dla danego problemu istnieje więcej niż jedno rozwiązanie, BFS zapewni rozwiązanie minimalne, które wymaga najmniejszej liczby kroków.
Niedogodności:
- Wymaga dużo pamięci, ponieważ każdy poziom drzewa musi zostać zapisany w pamięci, aby móc rozwinąć następny poziom.
- BFS potrzebuje dużo czasu, jeśli rozwiązanie jest daleko od węzła głównego.
Przykład:
W poniższej strukturze drzewa pokazaliśmy przechodzenie drzewa za pomocą algorytmu BFS od węzła głównego S do węzła docelowego K. Algorytm wyszukiwania BFS przemierza warstwy, więc będzie podążał ścieżką pokazaną przez przerywaną strzałkę, a przebyta ścieżka będzie:
S---> A--->B---->C--->D---->G--->H--->E---->F---->I---->K
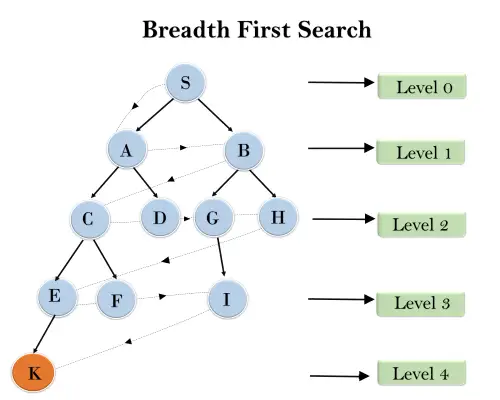
Złożoność czasowa: Złożoność czasową algorytmu BFS można uzyskać na podstawie liczby węzłów przechodzących w BFS aż do najpłytszego węzła. Gdzie d = głębokość najpłytszego rozwiązania, a b jest węzłem w każdym stanie.
T(b) = 1+b2+b3+.......+ bD= O (urD)
Złożoność przestrzeni: Złożoność przestrzenna algorytmu BFS jest określona przez rozmiar pamięci granicy, który wynosi O (bD).
Kompletność: BFS jest ukończony, co oznacza, że jeśli najpłytszy węzeł docelowy znajduje się na skończonej głębokości, wówczas BFS znajdzie rozwiązanie.
aktor Govindy
Optymalność: BFS jest optymalny, jeśli koszt ścieżki jest niemalejącą funkcją głębokości węzła.
2. Przeszukiwanie w głąb
- Przeszukiwanie w głąb jest algorytmem rekurencyjnym służącym do przechodzenia przez strukturę danych w postaci drzewa lub wykresu.
- Nazywa się to przeszukiwaniem w głąb, ponieważ rozpoczyna się od węzła głównego i podąża każdą ścieżką do węzła o największej głębokości, zanim przejdzie do następnej ścieżki.
- DFS do swojej implementacji wykorzystuje strukturę danych stosu.
- Proces algorytmu DFS jest podobny do algorytmu BFS.
Uwaga: Wycofywanie się to technika algorytmiczna służąca do znajdowania wszystkich możliwych rozwiązań za pomocą rekurencji.
Korzyść:
- DFS wymaga bardzo mniej pamięci, ponieważ wystarczy przechowywać stos węzłów na ścieżce od węzła głównego do bieżącego węzła.
- Dotarcie do węzła docelowego zajmuje mniej czasu niż algorytm BFS (jeśli porusza się właściwą ścieżką).
Niekorzyść:
- Istnieje możliwość, że wiele stanów będzie się powtarzać i nie ma gwarancji znalezienia rozwiązania.
- Algorytm DFS szuka głęboko w dół i czasami może przejść do nieskończonej pętli.
Przykład:
W poniższym drzewie wyszukiwania pokazaliśmy przebieg wyszukiwania w głąb i będzie on przebiegał w następującej kolejności:
Węzeł główny --->Węzeł lewy ----> węzeł prawy.
Rozpocznie wyszukiwanie od węzła głównego S i przejdzie przez A, następnie B, potem D i E, po przejściu przez E, cofnie się do drzewa, ponieważ E nie ma innego następcy, a węzeł docelowy nadal nie został znaleziony. Po cofnięciu przejdzie przez węzeł C, a następnie G i tutaj zakończy, gdy znajdzie węzeł docelowy.

Kompletność: Algorytm wyszukiwania DFS jest kompletny w skończonej przestrzeni stanów, ponieważ rozszerzy każdy węzeł w ograniczonym drzewie wyszukiwania.
Złożoność czasowa: Złożoność czasowa DFS będzie równa węzłowi, przez który przechodzi algorytm. Podaje się go:
T(n)= 1+ n2+ rz3+......+ rzM=O(nM)
Gdzie, m = maksymalna głębokość dowolnego węzła, która może być znacznie większa niż d (najpłytsza głębokość rozwiązania)
Złożoność przestrzeni: Algorytm DFS musi przechowywać tylko jedną ścieżkę z węzła głównego, stąd złożoność przestrzenna DFS jest równa rozmiarowi zbioru prążków, który wynosi O .
Optymalny: Algorytm wyszukiwania DFS nie jest optymalny, ponieważ może generować dużą liczbę kroków lub wysoki koszt dotarcia do węzła docelowego.
3. Algorytm wyszukiwania z ograniczoną głębokością:
Algorytm wyszukiwania z ograniczoną głębokością jest podobny do wyszukiwania w głąb z wcześniej określonym limitem. Wyszukiwanie ograniczone do głębokości może rozwiązać wadę nieskończonej ścieżki w przypadku wyszukiwania w głąb. W tym algorytmie węzeł na granicy głębokości będzie traktowany jako nie ma dalszych węzłów następczych.
Poszukiwania ograniczone w głąb można zakończyć dwoma warunkami niepowodzenia:
- Standardowa wartość niepowodzenia: wskazuje, że problem nie ma rozwiązania.
- Wartość błędu odcięcia: określa brak rozwiązania problemu w ramach danego limitu głębokości.
Zalety:
Wyszukiwanie ograniczone do głębokości oszczędza pamięć.
Niedogodności:
- Wyszukiwanie ograniczone w głąb ma również wadę polegającą na niekompletności.
- Może nie być optymalne, jeśli problem ma więcej niż jedno rozwiązanie.
Przykład:

Kompletność: Algorytm wyszukiwania DLS jest kompletny, jeśli rozwiązanie znajduje się powyżej limitu głębokości.
Złożoność czasowa: Złożoność czasowa algorytmu DLS wynosi O(urℓ) .
Złożoność przestrzeni: Złożoność przestrzenna algorytmu DLS wynosi O (b�ℓ) .
Optymalny: Wyszukiwanie z ograniczoną głębokością można postrzegać jako szczególny przypadek DFS i również nie jest ono optymalne, nawet jeśli ℓ>d.
4. Algorytm wyszukiwania o jednolitym koszcie:
Wyszukiwanie o jednolitych kosztach to algorytm wyszukiwania używany do przechodzenia przez drzewo lub wykres ważony. Algorytm ten ma zastosowanie, gdy dla każdej krawędzi dostępny jest inny koszt. Podstawowym celem wyszukiwania o jednolitych kosztach jest znalezienie ścieżki do węzła docelowego, który ma najniższy skumulowany koszt. Wyszukiwanie o jednakowym koszcie rozszerza węzły zgodnie z kosztami ich ścieżki z węzła głównego. Można go zastosować do rozwiązania dowolnego wykresu/drzewa, gdzie wymagany jest optymalny koszt. Algorytm wyszukiwania o jednolitym koszcie jest implementowany przez kolejkę priorytetową. Daje maksymalny priorytet najniższemu skumulowanemu kosztowi. Jednolite wyszukiwanie kosztów jest równoważne algorytmowi BFS, jeśli koszt ścieżki wszystkich krawędzi jest taki sam.
Zalety:
- Jednolite poszukiwanie kosztów jest optymalne, ponieważ w każdym stanie wybierana jest ścieżka o najmniejszym koszcie.
Niedogodności:
- Nie przejmuje się liczbą kroków związanych z wyszukiwaniem i interesuje się jedynie kosztem ścieżki. Przez co algorytm ten może utknąć w nieskończonej pętli.
Przykład:

Kompletność:
Wyszukiwanie przy jednolitych kosztach zostało zakończone, tzn. jeśli istnieje rozwiązanie, UCS je znajdzie.
Zamień ciąg JavaScript
Złożoność czasowa:
Niech C* to Koszt optymalnego rozwiązania , I mi to każdy krok prowadzący do zbliżenia się do węzła docelowego. Wtedy liczba kroków wynosi = C*/ε+1. Tutaj wzięliśmy +1, zaczynając od stanu 0 i kończąc na C*/ε.
Dlatego najgorszym przypadkiem jest złożoność czasowa wyszukiwania o jednolitych kosztach O(ur1 + [C*/e])/ .
Złożoność przestrzeni:
Ta sama logika dotyczy złożoności przestrzennej, tak jest w przypadku najgorszego przypadku złożoności przestrzennej wyszukiwania o jednakowych kosztach O(ur1 + [C*/e]) .
Optymalny:
Wyszukiwanie o jednakowych kosztach jest zawsze optymalne, ponieważ wybiera tylko ścieżkę o najniższym koszcie ścieżki.
5. Iteracyjne pogłębianie Wyszukiwanie w głąb:
Iteracyjny algorytm pogłębiania jest kombinacją algorytmów DFS i BFS. Ten algorytm wyszukiwania znajduje najlepszy limit głębokości i robi to poprzez stopniowe zwiększanie limitu, aż do znalezienia celu.
Algorytm ten przeprowadza wyszukiwanie w pierwszej kolejności do pewnego „limitu głębokości” i zwiększa limit głębokości po każdej iteracji, aż do znalezienia węzła docelowego.
Ten algorytm wyszukiwania łączy w sobie zalety szybkiego wyszukiwania wszerz i wydajności pamięci w przypadku wyszukiwania w głąb.
Algorytm wyszukiwania iteracyjnego jest przydatny w wyszukiwaniu bez wiedzy, gdy przestrzeń poszukiwań jest duża, a głębokość węzła docelowego jest nieznana.
Zalety:
- Łączy zalety algorytmu wyszukiwania BFS i DFS w zakresie szybkiego wyszukiwania i wydajności pamięci.
Niedogodności:
- Główną wadą IDDFS jest to, że powtarza całą pracę z poprzedniej fazy.
Przykład:
Poniższa struktura drzewa przedstawia iteracyjne pogłębianie w pierwszej kolejności. Algorytm IDDFS wykonuje różne iteracje, dopóki nie znajdzie węzła docelowego. Iterację wykonywaną przez algorytm podaje się jako:

Pierwsza iteracja -----> A
Druga iteracja ----> A, B, C
Trzecia iteracja------>A, B, D, E, C, F, G
4. iteracja------>A, B, D, H, I, E, C, F, K, G
W czwartej iteracji algorytm znajdzie węzeł docelowy.
Kompletność:
Algorytm ten jest kompletny, jeśli współczynnik rozgałęzienia jest skończony.
Złożoność czasowa:
Java zawiera podciąg
Załóżmy, że b jest czynnikiem rozgałęziającym, a głębokość wynosi d, wtedy mamy do czynienia z najgorszym przypadkiem złożoności czasowej O(urD) .
Złożoność przestrzeni:
Złożoność przestrzenna IDDFS będzie wynosić O(bd) .
Optymalny:
Algorytm IDDFS jest optymalny, jeśli koszt ścieżki jest niemalejącą funkcją głębokości węzła.
6. Algorytm wyszukiwania dwukierunkowego:
Algorytm wyszukiwania dwukierunkowego przeprowadza dwa jednoczesne wyszukiwania, jedno ze stanu początkowego zwane wyszukiwaniem do przodu i drugie od węzła docelowego zwane wyszukiwaniem wstecz, aby znaleźć węzeł docelowy. Wyszukiwanie dwukierunkowe zastępuje jeden wykres wyszukiwania dwoma małymi podgrafami, w których jeden rozpoczyna wyszukiwanie od wierzchołka początkowego, a drugi od wierzchołka docelowego. Wyszukiwanie kończy się, gdy te dwa wykresy przecinają się.
Wyszukiwanie dwukierunkowe może wykorzystywać techniki wyszukiwania, takie jak BFS, DFS, DLS itp.
Zalety:
- Wyszukiwanie dwukierunkowe jest szybkie.
- Wyszukiwanie dwukierunkowe wymaga mniej pamięci
Niedogodności:
- Implementacja drzewa wyszukiwania dwukierunkowego jest trudna.
Przykład:
W poniższym drzewie wyszukiwania zastosowano algorytm wyszukiwania dwukierunkowego. Algorytm ten dzieli jeden wykres/drzewo na dwa podwykresy. Rozpoczyna ruch od węzła 1 w kierunku do przodu i rozpoczyna się od węzła docelowego 16 w kierunku do tyłu.
Algorytm kończy się w węźle 9, gdzie spotykają się dwa wyszukiwania.

Kompletność: Wyszukiwanie dwukierunkowe jest zakończone, jeśli w obu wyszukiwaniach użyjemy BFS.
Złożoność czasowa: Złożoność czasowa wyszukiwania dwukierunkowego przy użyciu BFS wynosi O(urD) .
Złożoność przestrzeni: Złożoność przestrzenna wyszukiwania dwukierunkowego wynosi O(urD) .
Optymalny: Wyszukiwanie dwukierunkowe jest optymalne.