Opiekun zoo to rozproszona usługa koordynacyjna typu open source dla aplikacji rozproszonych. Udostępnia prosty zestaw prymitywów do implementowania usług wyższego poziomu w zakresie synchronizacji, konserwacji konfiguracji oraz grup i nazewnictwa.
W systemie rozproszonym istnieje wiele węzłów lub maszyn, które muszą się ze sobą komunikować i koordynować swoje działania. ZooKeeper zapewnia sposób zapewnienia, że te węzły są sobie wzajemnie świadome i mogą koordynować swoje działania. Czyni to poprzez utrzymywanie hierarchicznego drzewa węzłów danych tzw Znody , które mogą być używane do przechowywania i pobierania danych oraz utrzymywania informacji o stanie. ZooKeeper zapewnia zestaw prymitywów, takich jak blokady, bariery i kolejki, których można używać do koordynowania działań węzłów w systemie rozproszonym. Zapewnia także takie funkcje, jak wybór lidera, przełączanie awaryjne i odzyskiwanie, które mogą pomóc zapewnić odporność systemu na awarie. ZooKeeper jest szeroko stosowany w systemach rozproszonych, takich jak Hadoop, Kafka i HBase, i stał się niezbędnym składnikiem wielu aplikacji rozproszonych.
Dlaczego tego potrzebujemy?
- Usługi koordynacyjne : Integracja/komunikacja usług w środowisku rozproszonym.
- Usługi koordynacyjne są trudne do prawidłowego wykonania. Są szczególnie podatni na błędy, takie jak warunki wyścigowe i impas.
- Warunki wyścigu -Dwa lub więcej systemów próbuje wykonać jakieś zadanie.
- Zakleszczenia – Dwie lub więcej operacji czeka na siebie.
- Aby ułatwić koordynację pomiędzy środowiskami rozproszonymi, programiści wpadli na pomysł zwany zookeeperem, dzięki któremu nie muszą zwalniać aplikacji rozproszonych z odpowiedzialności za wdrażanie usług koordynacyjnych od zera.
Co to jest system rozproszony?
- Wiele systemów komputerowych pracujących nad jednym problemem.
- Jest to sieć składająca się z autonomicznych komputerów połączonych za pomocą rozproszonego oprogramowania pośredniczącego.
- Kluczowe cechy : Współbieżne, współdzielone zasoby, niezależne, globalne, większa odporność na awarie i stosunek ceny do wydajności jest znacznie lepszy.
- Kluczowy cel s: Przejrzystość, Niezawodność, Wydajność, Skalowalność.
- Wyzwania : Bezpieczeństwo, usterka, koordynacja i udostępnianie zasobów.
Wyzwanie koordynacyjne
- Dlaczego koordynacja w systemie rozproszonym jest trudnym problemem?
- Koordynacja lub zarządzanie konfiguracją aplikacji rozproszonej, która ma wiele systemów.
- Węzeł główny, w którym przechowywane są dane klastra.
- Węzły robocze lub węzły podrzędne pobierają dane z tego węzła głównego.
- pojedynczy punkt awarii.
- synchronizacja nie jest łatwa.
- Konieczne jest staranne zaprojektowanie i wdrożenie.
Strażnik Apaczów
Apache Zookeeper to rozproszona usługa koordynacyjna typu open source dla systemów rozproszonych. Zapewnia rozproszonym aplikacjom centralne miejsce do przechowywania danych, wzajemnej komunikacji i koordynowania działań. Zookeeper jest używany w systemach rozproszonych do koordynowania rozproszonych procesów i usług. Zapewnia prosty model danych o strukturze drzewa, prosty interfejs API i rozproszony protokół, aby zapewnić spójność i dostępność danych. Zookeeper został zaprojektowany tak, aby był wysoce niezawodny i odporny na awarie, a także mógł obsługiwać wysoki poziom przepustowości odczytu i zapisu.
Zookeeper jest zaimplementowany w Javie i jest szeroko stosowany w systemach rozproszonych, szczególnie w ekosystemie Hadoop. Jest to projekt Apache Software Foundation i jest udostępniany na licencji Apache 2.0.
Architektura Zookeepera
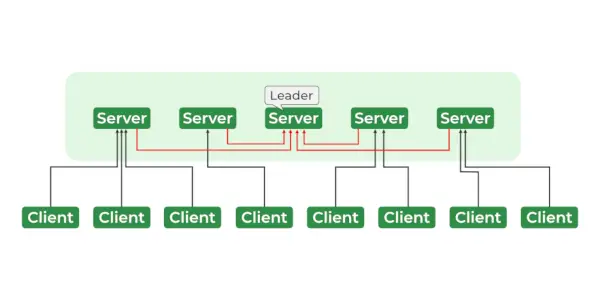
Usługi zoologa
Architektura ZooKeepera składa się z hierarchii węzłów zwanych znodes, zorganizowanych w strukturę przypominającą drzewo. Każdy znode może przechowywać dane i posiada zestaw uprawnień kontrolujących dostęp do znode. Znody są zorganizowane w hierarchiczną przestrzeń nazw, podobną do systemu plików. U podstaw hierarchii znajduje się węzeł główny, a wszystkie pozostałe znody są elementami podrzędnymi znode głównego. Hierarchia jest podobna do hierarchii systemu plików, gdzie każdy znode może mieć dzieci i wnuki, i tak dalej.
Ważne komponenty w Zookeeperze
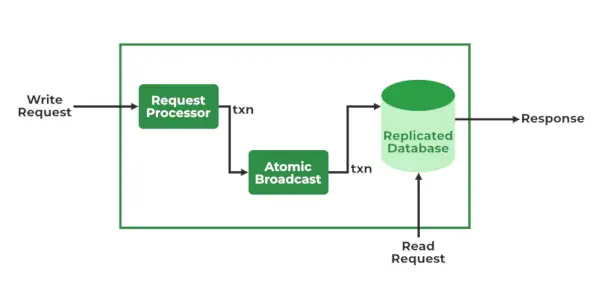
Usługi zookeepera
- Lider i naśladowca
- Procesor żądania – Aktywny w węźle wiodącym i odpowiedzialny za przetwarzanie żądań zapisu. Po przetworzeniu wysyła zmiany do węzłów obserwujących
- Transmisja atomowa – Występuje zarówno w węźle wiodącym, jak i w węzłach podrzędnych. Odpowiada za przesłanie zmian do innych węzłów.
- Bazy danych w pamięci (Replikowane bazy danych) – odpowiada za przechowywanie danych u zookeepera. Każdy węzeł zawiera własne bazy danych. Dane zapisywane są także do systemu plików, zapewniając możliwość ich odzyskania w przypadku problemów z klastrem.
Inne komponenty
- Klient – Jeden z węzłów w naszym rozproszonym klastrze aplikacji. Uzyskaj dostęp do informacji z serwera. Każdy klient wysyła wiadomość do serwera, aby poinformować serwer, że klient żyje.
- serwer – Świadczy wszystkie usługi dla klienta. Daje klientowi potwierdzenie.
- Ensemble – Grupa serwerów Zookeeper. Minimalna liczba węzłów wymaganych do utworzenia zespołu wynosi 3.
Model danych zookeepera
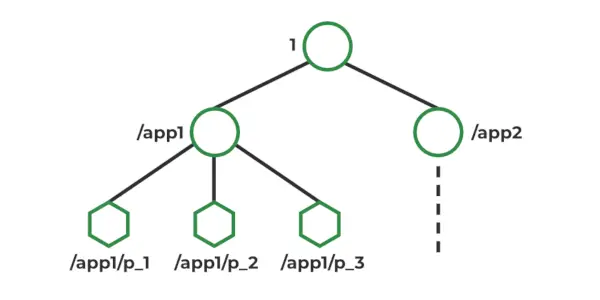
Model danych ZooKeepera
W Zookeeperze dane są przechowywane w hierarchicznej przestrzeni nazw, podobnej do systemu plików. Każdy węzeł w przestrzeni nazw nazywany jest Znode i może przechowywać dane i mieć dzieci. Znody są podobne do plików i katalogów w systemie plików. Zookeeper zapewnia prosty interfejs API do tworzenia, czytania, pisania i usuwania Znode. Zapewnia także mechanizmy wykrywania zmian w danych przechowywanych w Znodes, takich jak zegarki i wyzwalacze. Znodes utrzymuje strukturę statystyk obejmującą: numer wersji, listę ACL, znacznik czasu i długość danych
Rodzaje Znodów :
- Trwałość : Aktywne, dopóki nie zostaną wyraźnie usunięte.
- Efemeryczny : Aktywny do czasu, aż połączenie klienta będzie aktywne.
- Sekwencyjny : Albo trwałe, albo efemeryczne.
Dlaczego potrzebujemy ZooKeepera w Hadoop?
Zookeeper służy do zarządzania i koordynowania węzłów w klastrze Hadoop, w tym NameNode, DataNode i ResourceManager. W klastrze Hadoop Zookeeper pomaga:
- Zachowaj informacje konfiguracyjne: Zookeeper przechowuje informacje konfiguracyjne dla klastra Hadoop, w tym lokalizację NameNode, DataNode i ResourceManager.
- Zarządzaj stanem klastra: Zookeeper śledzi stan węzłów w klastrze Hadoop i może służyć do wykrywania awarii węzła lub jego niedostępności.
- Koordynuj procesy rozproszone: Zookeeper może służyć do koordynowania procesów rozproszonych, takich jak planowanie zadań i alokacja zasobów, między węzłami klastra Hadoop.
Zookeeper pomaga zapewnić dostępność i niezawodność klastra Hadoop, zapewniając centralną usługę koordynacji dla węzłów w klastrze.
Jak działa ZooKeeper w Hadoop?
ZooKeeper działa jako rozproszony system plików i udostępnia prosty zestaw interfejsów API, które umożliwiają klientom odczytywanie i zapisywanie danych w systemie plików. Przechowuje swoje dane w drzewiastej strukturze zwanej znode, którą można traktować jako plik lub katalog w tradycyjnym systemie plików. ZooKeeper wykorzystuje algorytm konsensusu, aby zapewnić, że wszystkie jego serwery mają spójny widok danych przechowywanych w Znodes. Oznacza to, że jeśli klient zapisze dane w znode, dane te zostaną zreplikowane na wszystkich pozostałych serwerach w zestawie ZooKeeper.
Jedną z ważnych cech ZooKeepera jest jego zdolność do wspierania pojęcia zegarka. Zegarek umożliwia klientowi zarejestrowanie się w celu otrzymywania powiadomień w przypadku zmiany danych przechowywanych w znodzie. Może to być przydatne do monitorowania zmian w danych przechowywanych w ZooKeeperze i reagowania na te zmiany w systemie rozproszonym.
W Hadoop ZooKeeper jest używany do różnych celów, w tym:
- Przechowywanie informacji konfiguracyjnych: ZooKeeper służy do przechowywania informacji konfiguracyjnych współdzielonych przez wiele komponentów Hadoop. Na przykład może służyć do przechowywania lokalizacji NameNodes w klastrze Hadoop lub adresów węzłów JobTracker.
- Zapewnienie rozproszonej synchronizacji: ZooKeeper służy do koordynowania działań różnych komponentów Hadoop i zapewnienia ich spójnej współpracy. Na przykład może służyć do zapewnienia, że tylko jeden NameNode będzie aktywny w danym momencie w klastrze Hadoop.
- Utrzymanie nazewnictwa: ZooKeeper służy do utrzymywania scentralizowanej usługi nazewnictwa dla komponentów Hadoop. Może to być przydatne do identyfikowania i lokalizowania zasobów w systemie rozproszonym.
ZooKeeper jest niezbędnym składnikiem Hadoopa i odgrywa kluczową rolę w koordynowaniu działania różnych jego podzespołów.
Czytanie i pisanie w Apache Zookeeper
ZooKeeper zapewnia prosty i niezawodny interfejs do odczytu i zapisu danych. Dane są przechowywane w hierarchicznej przestrzeni nazw, podobnej do systemu plików, z węzłami zwanymi znodes. Każdy znode może przechowywać dane i mieć znody potomne. Klienci ZooKeeper mogą odczytywać i zapisywać dane w tych znodach, używając odpowiednio metod getData() i setData(). Oto przykład odczytu i zapisu danych przy użyciu API ZooKeeper Java:
Jawa
// Connect to the ZooKeeper ensemble> ZooKeeper zk =>new> ZooKeeper(>'localhost:2181'>,>3000>,>null>);> // Write data to the znode '/myZnode'> String path =>'/myZnode'>;> String data =>'hello world'>;> zk.create(path, data.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);> // Read data from the znode '/myZnode'> byte>[] bytes = zk.getData(path,>false>,>null>);> String readData =>new> String(bytes);> // Prints 'hello world'> System.out.println(readData);> // Closing the connection> // to the ZooKeeper ensemble> zk.close();> |
>
>
Python3
from> kazoo.client>import> KazooClient> # Connect to ZooKeeper> zk>=> KazooClient(hosts>=>'localhost:2181'>)> zk.start()> # Create a node with some data> zk.ensure_path(>'/gfg_node'>)> zk.>set>(>'/gfg_node'>, b>'some_data'>)> # Read the data from the node> data, stat>=> zk.get(>'/gfg_node'>)> print>(data)> # Stop the connection to ZooKeeper> zk.stop()> |
>
usuwanie ostatniego zatwierdzenia gi
>
Sesja i zegarki
Sesja
- Żądania w sesji realizowane są w kolejności FIFO.
- Po ustanowieniu sesji następuje identyfikator sesji jest przypisany do klienta.
- Klient wysyła bicie serca aby sesja była ważna
- limit czasu sesji jest zwykle wyrażany w milisekundach
Zegarki
- Zegarki to mechanizmy umożliwiające klientom otrzymywanie powiadomień o zmianach w Zookeeperze
- Klient może oglądać podczas czytania konkretnego znode.
- Zmiany Znode to modyfikacje danych powiązanych z znodes lub zmiany w elementach potomnych znode.
- Zegarki uruchamiane są tylko raz.
- Jeśli sesja wygaśnie, zegarki również zostaną usunięte.