W informatyce, prać to słaba wydajność systemu pamięci wirtualnej (lub systemu stronicowania) podczas wielokrotnego ładowania tych samych stron z powodu braku pamięci głównej do przechowywania ich w pamięci. W zależności od konfiguracji i algorytmu rzeczywista przepustowość systemu może spaść o wiele rzędów wielkości.
W informatyce, lanie występuje, gdy zasoby pamięci wirtualnej komputera są nadużywane, co prowadzi do ciągłego stanu stronicowania i błędów stron, utrudniając większość przetwarzania na poziomie aplikacji. Powoduje to pogorszenie lub załamanie wydajności komputera. Sytuacja może trwać w nieskończoność, dopóki użytkownik nie zamknie niektórych uruchomionych aplikacji lub aktywne procesy nie zwolnią dodatkowych zasobów pamięci wirtualnej.
Aby lepiej poznać pojęcie thrashingu, najpierw musimy poznać błędy stron i zamianę.
Lanie ma miejsce wtedy, gdy błąd strony i zamiana następuje bardzo często i z większą częstotliwością, a wtedy system operacyjny musi spędzać więcej czasu na zamianie tych stron. Ten stan w systemie operacyjnym nazywany jest biciem. Z powodu bicia obciążenie procesora zostanie zmniejszone lub znikome.
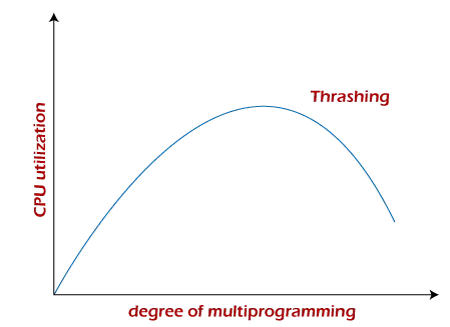
Podstawowa koncepcja jest taka, że jeśli procesowi zostanie przydzielona zbyt mało ramek, wystąpi zbyt wiele i zbyt częste błędy stron. W rezultacie procesor nie wykona żadnej wartościowej pracy, a jego wykorzystanie drastycznie spadnie.
Planista długoterminowy próbowałby następnie poprawić wykorzystanie procesora, ładując więcej procesów do pamięci, zwiększając w ten sposób stopień wieloprogramowości. Niestety, spowodowałoby to dalszy spadek wykorzystania procesora, wywołując reakcję łańcuchową w postaci większych błędów stron, po których następuje wzrost stopnia wieloprogramowości, zwany biciem.
Algorytmy podczas rzucania
Za każdym razem, gdy rozpoczyna się bicie, system operacyjny próbuje zastosować algorytm globalnej zamiany strony lub algorytm lokalnej zamiany strony.
1. Globalna wymiana strony
Ponieważ globalna wymiana stron może spowodować przywrócenie dowolnej strony, za każdym razem, gdy zostanie wykryte bicie, próbuje ona wyświetlić więcej stron. Ale tak naprawdę żaden proces nie otrzyma wystarczającej liczby klatek, w wyniku czego szarpanie będzie coraz większe. Dlatego też globalny algorytm zastępowania stron nie jest odpowiedni w przypadku bicia.
2. Wymiana strony lokalnej
W przeciwieństwie do algorytmu globalnej zamiany stron, lokalna zamiana strony wybierze strony, które należą tylko do tego procesu. Jest więc szansa na ograniczenie bicia. Udowodniono jednak, że korzystanie z lokalnej wymiany stron ma wiele wad. Dlatego lokalna wymiana strony jest po prostu alternatywą dla globalnej wymiany strony w scenariuszu szamotaniny.
Przyczyny bicia
Programy lub obciążenia mogą powodować awarie i skutkować poważnymi problemami z wydajnością, takimi jak:
- Jeżeli obciążenie procesora jest zbyt niskie, zwiększamy stopień wieloprogramowości wprowadzając nowy system. Stosowany jest globalny algorytm zastępowania stron. Harmonogram procesora widzi malejące wykorzystanie procesora i zwiększa stopień wieloprogramowości.
- Wykorzystanie procesora jest wykreślane w funkcji stopnia wieloprogramowości.
- Wraz ze wzrostem stopnia wieloprogramowości wzrasta również wykorzystanie procesora.
- Jeśli stopień wieloprogramowania zostanie jeszcze bardziej zwiększony, zacznie się bicie i wykorzystanie procesora gwałtownie spadnie.
- Zatem w tym momencie, aby zwiększyć wykorzystanie procesora i zaprzestać bicia, musimy zmniejszyć stopień wieloprogramowania.
Jak wyeliminować bicie
Thrashing ma negatywny wpływ na stan dysku twardego i wydajność systemu. Dlatego konieczne jest podjęcie pewnych działań, aby tego uniknąć. Aby rozwiązać problem bicia, oto następujące metody, takie jak:
Techniki zapobiegania rzucaniu się
Zastąpienie strony lokalnej jest lepsze niż zastąpienie strony globalnej, ale zastąpienie strony lokalnej ma wiele wad, więc czasami nie jest pomocne. Dlatego poniżej znajdują się inne techniki stosowane do obsługi bicia:
1. Model lokalności
Lokalność to zbiór stron, które są wspólnie aktywnie wykorzystywane. Model lokalności stwierdza, że w trakcie wykonywania proces przemieszcza się z jednej lokalizacji do drugiej. Zatem program składa się zazwyczaj z kilku różnych lokalizacji, które mogą się na siebie nakładać.
Na przykład, gdy funkcja jest wywoływana, definiuje ona nową lokalizację, w której tworzone są odniesienia do pamięci do instrukcji wywołania funkcji, zmiennych lokalnych i globalnych itp. Podobnie, gdy funkcja jest opuszczana, proces opuszcza tę lokalizację.
2. Model zbiorów roboczych
Model ten opiera się na powyższej koncepcji Modelu Lokalności.
Podstawowa zasada głosi, że jeśli przydzielimy procesowi wystarczającą liczbę ramek, aby pomieścić jego bieżącą lokalizację, będzie on powodował błąd tylko za każdym razem, gdy przeniesie się do nowej lokalizacji. Jeśli jednak przydzielone ramki są mniejsze niż rozmiar bieżącej lokalizacji, proces musi się zawiesić.
Według tego modelu, w oparciu o parametr A, zbiór roboczy definiuje się jako zbiór stron w najnowszych odniesieniach do strony „A”. W związku z tym wszystkie aktywnie używane strony zawsze będą częścią zestawu roboczego.
python os listdir
Dokładność zbioru roboczego zależna jest od wartości parametru A. Jeżeli A jest zbyt duże, wówczas zbiory robocze mogą się na siebie nakładać. Z drugiej strony, w przypadku mniejszych wartości A, miejscowość może nie zostać uwzględniona w całości.
Jeżeli D jest całkowitym zapotrzebowaniem na ramki i WSSIjest rozmiarem zbioru roboczego dla procesu i,
D = ⅀ WSSI
Teraz, jeśli „m” jest liczbą ramek dostępnych w pamięci, istnieją dwie możliwości:
- D>m, tj. całkowite zapotrzebowanie przekracza liczbę ramek, nastąpi szarpanie, ponieważ niektóre procesy nie otrzymają wystarczającej liczby ramek.
- D<=m, then there would be no thrashing.< li>
Jeśli jest wystarczająca liczba dodatkowych ramek, wówczas do pamięci można załadować więcej procesów. Z drugiej strony, jeśli suma rozmiarów zbiorów roboczych przekracza dostępność ramek, część procesów należy zawiesić (wymienić pamięć).
Technika ta zapobiega trzepotaniu i zapewnia najwyższy możliwy stopień wieloprogramowania. W ten sposób optymalizuje wykorzystanie procesora.
3. Częstotliwość błędów strony
Bardziej bezpośrednie podejście do radzenia sobie z biciem polega na wykorzystaniu koncepcji częstotliwości błędów stronicowania.

Problemem związanym z biciem jest wysoki wskaźnik błędów stron, dlatego też koncepcja polega na kontrolowaniu współczynnika błędów stron.
Jeśli wskaźnik błędów strony jest zbyt wysoki, oznacza to, że procesowi przydzielono zbyt mało ramek. Wręcz przeciwnie, niski wskaźnik błędów strony wskazuje, że proces ma zbyt wiele ramek.
Można ustalić górną i dolną granicę żądanej częstotliwości błędów strony, jak pokazano na schemacie.
Jeśli częstotliwość błędów strony spadnie poniżej dolnego limitu, ramki można usunąć z procesu. Podobnie, jeśli liczba błędów stron przekracza górną granicę, procesowi można przydzielić więcej ramek.
Innymi słowy, stan graficzny systemu powinien być ograniczony do prostokątnego obszaru utworzonego na danym schemacie.
Jeśli wskaźnik błędów stron jest wysoki i nie ma wolnych ramek, niektóre procesy można zawiesić i przydzielone do nich można ponownie przydzielić innym procesom. Zawieszone procesy można ponownie uruchomić później.