Jeden ważny aspekt Nauczanie maszynowe jest ocena modelu. Musisz mieć jakiś mechanizm oceny swojego modelu. W tym miejscu pojawiają się wskaźniki wydajności, które dają nam poczucie, jak dobry jest model. Jeśli znasz niektóre podstawy Nauczanie maszynowe to musiałeś natknąć się na niektóre z tych wskaźników, takie jak dokładność, precyzja, przypominanie, auc-roc itp., które są powszechnie używane do zadań klasyfikacyjnych. W tym artykule szczegółowo zbadamy jeden z takich wskaźników, jakim jest krzywa AUC-ROC.
Spis treści
- Co to jest krzywa AUC-ROC?
- Kluczowe terminy stosowane w krzywych AUC i ROC
- Związek pomiędzy czułością, swoistością, FPR i wartością progową.
- Jak działa AUC-ROC?
- Kiedy powinniśmy stosować metrykę oceny AUC-ROC?
- Spekulacje na temat wydajności modelu
- Zrozumienie krzywej AUC-ROC
- Implementacja z wykorzystaniem dwóch różnych modeli
- Jak używać ROC-AUC dla modelu wieloklasowego?
- Często zadawane pytania dotyczące krzywej AUC ROC w uczeniu maszynowym
Co to jest krzywa AUC-ROC?
Krzywa AUC-ROC, czyli obszar pod krzywą charakterystyki działania odbiornika, jest graficzną reprezentacją wydajności binarnego modelu klasyfikacji przy różnych progach klasyfikacji. Jest powszechnie stosowany w uczeniu maszynowym do oceny zdolności modelu do rozróżnienia dwóch klas, zazwyczaj klasy pozytywnej (np. obecności choroby) i klasy negatywnej (np. braku choroby).
Najpierw zrozumiemy znaczenie tych dwóch terminów ROC I AUC .
- ROC : Charakterystyka działania odbiornika
- AUC : Obszar pod krzywą
Krzywa charakterystyki działania odbiornika (ROC).
ROC oznacza charakterystykę operacyjną odbiornika, a krzywa ROC jest graficzną reprezentacją efektywności binarnego modelu klasyfikacji. Przedstawia wykres prawdziwie dodatniego współczynnika (TPR) w porównaniu do fałszywie dodatniego współczynnika (FPR) przy różnych progach klasyfikacji.
Obszar pod krzywą (AUC) Krzywa:
AUC oznacza obszar pod krzywą, a krzywa AUC reprezentuje obszar pod krzywą ROC. Mierzy ogólną wydajność binarnego modelu klasyfikacji. Ponieważ zarówno TPR, jak i FPR mieszczą się w zakresie od 0 do 1, zatem obszar będzie zawsze mieścić się w przedziale od 0 do 1, a większa wartość AUC oznacza lepszą wydajność modelu. Naszym głównym celem jest maksymalizacja tego obszaru, aby mieć jak najwyższy TPR i najniższy FPR na zadanym progu. AUC mierzy prawdopodobieństwo, że model przypisze losowo wybranemu pozytywnemu wystąpieniu wyższe przewidywane prawdopodobieństwo w porównaniu z losowo wybranym przypadkiem negatywnym.
Reprezentuje prawdopodobieństwo dzięki któremu nasz model może rozróżnić dwie klasy obecne w naszym obiekcie docelowym.
Metryka oceny klasyfikacji ROC-AUC
Kluczowe terminy stosowane w krzywych AUC i ROC
1. TPR i FPR
Jest to najczęstsza definicja, z którą można się spotkać, przeglądając Google AUC-ROC. Zasadniczo krzywa ROC to wykres przedstawiający wydajność modelu klasyfikacyjnego przy wszystkich możliwych progach (próg to konkretna wartość, powyżej której mówi się, że punkt należy do określonej klasy). Krzywa jest wykreślana pomiędzy dwoma parametrami
- TPR – Prawdziwie dodatni wskaźnik
- FPR – Wskaźnik fałszywie dodatni
Zanim zrozumiemy, TPR i FPR, przyjrzyjmy się szybko matryca zamieszania .
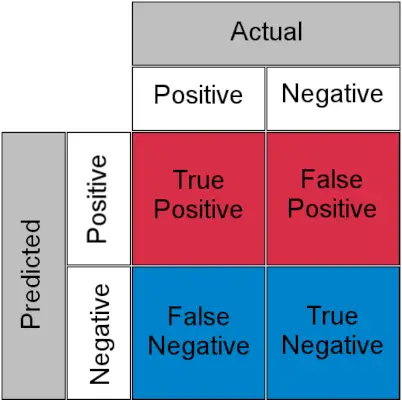
Macierz zamieszania dla zadania klasyfikacyjnego
- Prawdziwie pozytywny : Rzeczywisty wynik pozytywny i przewidywany jako wynik pozytywny
- Prawdziwy negatyw : Rzeczywisty wynik ujemny i przewidywany jako wynik ujemny
- Fałszywie dodatni (błąd typu I) : Rzeczywisty wynik negatywny, ale przewidywany jako pozytywny
- Fałszywie ujemny (błąd typu II) : Rzeczywisty wynik pozytywny, ale przewidywany jako negatywny
Mówiąc najprościej, możesz nazwać fałszywie pozytywnym a fałszywy alarm i fałszywie ujemne a chybić . Przyjrzyjmy się teraz, czym są TPR i FPR.
2. Czułość / Prawdziwie dodatni współczynnik / Przywołanie
Zasadniczo TPR/Recall/Sensitivity to stosunek pozytywnych przykładów, które zostały poprawnie zidentyfikowane. Reprezentuje zdolność modelu do prawidłowej identyfikacji pozytywnych przypadków i jest obliczany w następujący sposób:

Czułość/Przypomnienie/TPR mierzy odsetek rzeczywistych pozytywnych przypadków, które model poprawnie identyfikuje jako pozytywne.
3. Wskaźnik fałszywie dodatni
FPR to stosunek przykładów negatywnych, które zostały nieprawidłowo sklasyfikowane.

4. Specyfika
Specyficzność mierzy odsetek rzeczywistych negatywnych przypadków, które model poprawnie identyfikuje jako negatywne. Reprezentuje zdolność modelu do prawidłowej identyfikacji negatywnych instancji

Jak powiedziano wcześniej, ROC to nic innego jak wykres pomiędzy TPR i FPR dla wszystkich możliwych progów, a AUC to cały obszar poniżej tej krzywej ROC.
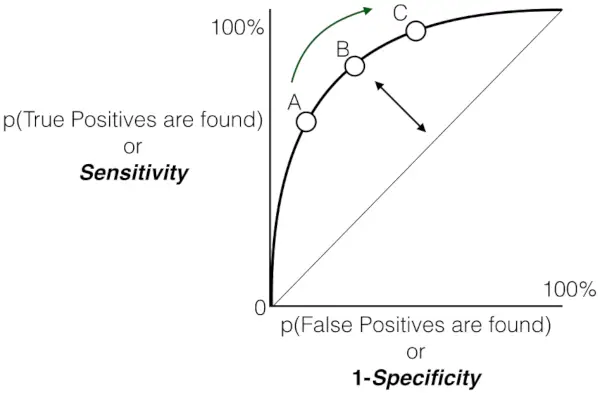
Wykres czułości w funkcji częstości wyników fałszywie dodatnich
Związek pomiędzy czułością, swoistością, FPR i wartością progową .
Czułość i swoistość:
- Odwrotna relacja: czułość i specyficzność mają odwrotną zależność. Kiedy jedno rośnie, drugie ma tendencję do zmniejszania się. Odzwierciedla to nieodłączny kompromis pomiędzy prawdziwie dodatnimi i prawdziwie ujemnymi stopami procentowymi.
- Strojenie poprzez próg: Dostosowując wartość progową, możemy kontrolować równowagę pomiędzy czułością i swoistością. Niższe progi prowadzą do wyższej czułości (więcej wyników prawdziwie pozytywnych) kosztem swoistości (więcej wyników fałszywie pozytywnych). I odwrotnie, podniesienie progu zwiększa swoistość (mniej wyników fałszywie dodatnich), ale poświęca czułość (więcej wyników fałszywie ujemnych).
Wartość progowa i odsetek wyników fałszywie dodatnich (FPR):
- Połączenie FPR i specyfiki: Odsetek wyników fałszywie dodatnich (FPR) jest po prostu uzupełnieniem specyficzności (FPR = 1 – specyficzność). Oznacza to bezpośredni związek między nimi: wyższa specyficzność przekłada się na niższą FPR i odwrotnie.
- Zmiany FPR w TPR: Podobnie, jak zauważyłeś, True Positive Rate (TPR) i FPR są również powiązane. Wzrost TPR (więcej wyników prawdziwie pozytywnych) zazwyczaj prowadzi do wzrostu FPR (więcej wyników fałszywie pozytywnych). I odwrotnie, spadek TPR (mniej wyników prawdziwie pozytywnych) powoduje spadek FPR (mniej wyników fałszywie pozytywnych)
Jak działa AUC-ROC?
Przyjrzeliśmy się interpretacji geometrycznej, ale myślę, że to wciąż za mało, aby rozwinąć intuicję stojącą za tym, co właściwie oznacza 0,75 AUC, teraz spójrzmy na AUC-ROC z probabilistycznego punktu widzenia. Porozmawiajmy najpierw o tym, co robi AUC, a później zbudujemy na tym nasze zrozumienie
AUC mierzy, jak dobrze model jest w stanie rozróżnić zajęcia.
AUC wynoszące 0,75 w rzeczywistości oznaczałoby, że, powiedzmy, bierzemy dwa punkty danych należące do oddzielnych klas, wtedy istnieje 75% szans, że model będzie w stanie je posegregować lub poprawnie uszeregować, tj. punkt dodatni ma większe prawdopodobieństwo przewidywania niż punkt ujemny klasa. (zakładając, że wyższe prawdopodobieństwo przewidywania oznacza, że punkt w idealnym przypadku należałby do klasy dodatniej). Oto mały przykład, aby wszystko było jaśniejsze.
Indeks | Klasa | Prawdopodobieństwo |
|---|---|---|
P1 | 1 | 0,95 |
P2 | 1 | 0,90 |
P3 | 0 | 0,85 |
P4 | 0 | 0,81 |
P5 | 1 | 0,78 |
P6 | 0 | 0,70 |
Tutaj mamy 6 punktów, gdzie P1, P2 i P5 należą do klasy 1, a P3, P4 i P6 należą do klasy 0 i odpowiadają nam przewidywane prawdopodobieństwa w kolumnie Prawdopodobieństwo, jak powiedzieliśmy, jeśli weźmiemy dwa punkty należące do oddzielnych klas, to jakie jest prawdopodobieństwo, że ranga modelu uporządkuje je poprawnie.
Weźmiemy wszystkie możliwe pary tak, że jeden punkt należy do klasy 1, a drugi do klasy 0. Poniżej będziemy mieli w sumie 9 takich par, wszystkie z tych 9 możliwych par.
Para | jest poprawne |
|---|---|
(P1, P3) | Tak |
(P1, P4) | Tak |
(P1,P6) | Tak |
(P2,P3) | Tak 3 miesiące |
(P2, P4) | Tak |
(P2, P6) | Tak |
(P3, P5) | NIE |
(P4,P5) | NIE |
(P5, P6) | Tak |
Tutaj kolumna Poprawna informuje, czy wspomniana para jest poprawnie uporządkowana według przewidywanego prawdopodobieństwa, tj. punkt klasy 1 ma wyższe prawdopodobieństwo niż punkt klasy 0, w 7 z tych 9 możliwych par klasa 1 jest wyżej oceniana niż klasa 0, lub możemy powiedzieć, że istnieje 77% szans, że jeśli wybierzemy parę punktów należących do odrębnych klas, model będzie w stanie je poprawnie rozróżnić. Myślę, że możesz mieć trochę intuicji stojącej za tą liczbą AUC, aby rozwiać wszelkie dalsze wątpliwości, zweryfikujmy ją za pomocą Scikit uczy się implementacji AUC-ROC.
Python3
import> numpy as np> from> sklearn .metrics>import> roc_auc_score> y_true>=> [>1>,>1>,>0>,>0>,>1>,>0>]> y_pred>=> [>0.95>,>0.90>,>0.85>,>0.81>,>0.78>,>0.70>]> auc>=> np.>round>(roc_auc_score(y_true, y_pred),>3>)> print>(>'Auc for our sample data is {}'>.>format>(auc))> |
>
>
Wyjście:
AUC for our sample data is 0.778>
Kiedy powinniśmy stosować metrykę oceny AUC-ROC?
Istnieją pewne obszary, w których użycie ROC-AUC może nie być idealne. W przypadkach, gdy zbiór danych jest wysoce niezrównoważony, krzywa ROC może dać zbyt optymistyczną ocenę wydajności modelu . To odchylenie optymistyczne wynika z faktu, że współczynnik wyników fałszywie dodatnich (FPR) krzywej ROC może stać się bardzo mały, gdy liczba rzeczywistych wyników ujemnych jest duża.
Patrząc na wzór FPR,

obserwujemy ,
- Klasa Negatywów jest w większości, w mianowniku FPR dominują Prawdziwie Negatywy, przez co FPR staje się mniej wrażliwa na zmiany przewidywań związanych z klasą mniejszościową (klasą pozytywną).
- Krzywe ROC mogą być odpowiednie, gdy koszt wyników fałszywie dodatnich i fałszywie ujemnych jest zrównoważony, a zbiór danych nie jest silnie niezrównoważony.
W takim przypadku Krzywe precyzji i przypomnienia można zastosować, co zapewnia alternatywną metrykę oceny, która jest bardziej odpowiednia dla niezrównoważonych zbiorów danych, koncentrując się na wydajności klasyfikatora w odniesieniu do klasy pozytywnej (mniejszości).
Spekulacje na temat wydajności modelu
- Wysokie AUC (bliskie 1) wskazuje na doskonałą moc dyskryminacyjną. Oznacza to, że model skutecznie rozróżnia obie klasy, a jego przewidywania są wiarygodne.
- Niskie AUC (bliskie 0) sugeruje słabą wydajność. W tym przypadku model ma trudności z rozróżnieniem klas dodatnich i ujemnych, a jego przewidywania mogą nie być godne zaufania.
- AUC około 0,5 oznacza, że model zasadniczo dokonuje przypadkowych domysłów. Nie wykazuje możliwości oddzielenia klas, co wskazuje, że model nie uczy się żadnych znaczących wzorców z danych.
Zrozumienie krzywej AUC-ROC
Na krzywej ROC oś x zazwyczaj reprezentuje współczynnik fałszywie dodatnich wyników (FPR), a oś y przedstawia współczynnik prawdziwie dodatnich wyników (TPR), znany również jako czułość lub przypomnienie. Zatem wyższa wartość na osi x (w prawo) na krzywej ROC faktycznie wskazuje wyższy odsetek wyników fałszywie dodatnich, a wyższa wartość na osi y (w górę) oznacza wyższy współczynnik prawdziwie dodatnich wyników. Krzywa ROC jest graficzną formą przedstawienie kompromisu pomiędzy stopą prawdziwie dodatnią a stopą fałszywie dodatnią przy różnych progach. Pokazuje wydajność modelu klasyfikacji przy różnych progach klasyfikacji. AUC (obszar pod krzywą) to sumaryczna miara wydajności krzywej ROC. Wybór progu zależy od konkretnych wymagań problemu, który próbujesz rozwiązać, oraz od kompromisu między fałszywymi alarmami i fałszywie negatywnymi, czyli akceptowalne w twoim kontekście.
- Jeśli chcesz priorytetowo potraktować ograniczenie liczby wyników fałszywie dodatnich (minimalizując ryzyko oznaczenia czegoś jako pozytywnego, gdy tak nie jest), możesz wybrać próg, który skutkuje niższym odsetkiem wyników fałszywie dodatnich.
- Jeśli chcesz nadać priorytet zwiększaniu prawdziwie pozytywnych wyników (przechwytywanie jak największej liczby rzeczywistych pozytywnych wyników), możesz wybrać próg, który skutkuje wyższym odsetkiem prawdziwie pozytywnych wyników.
Rozważmy przykład ilustrujący sposób generowania krzywych ROC dla różnych progi oraz w jaki sposób dany próg odpowiada matrycy zamieszania. Załóżmy, że mamy problem klasyfikacji binarnej z modelem przewidującym, czy wiadomość e-mail jest spamem (pozytywna), czy nie spamem (negatywna).
Weźmy pod uwagę dane hipotetyczne,
Prawdziwe etykiety: [1, 0, 1, 0, 1, 1, 0, 0, 1, 0]
Przewidywane prawdopodobieństwa: [0,8, 0,3, 0,6, 0,2, 0,7, 0,9, 0,4, 0,1, 0,75, 0,55]
Przypadek 1: Próg = 0,5
Prawdziwe etykiety | Przewidywane prawdopodobieństwa | Przewidywane etykiety |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matryca zamieszania oparta na powyższych przewidywaniach
| Przewidywanie = 0 | Przewidywanie = 1 |
|---|---|---|
Rzeczywisty = 0 | TP=4 | FN=1 |
Rzeczywisty = 1 logika zdań | FP=0 | TN=5 |
Odpowiednio,
- Prawdziwie dodatni współczynnik (TPR) :
Proporcja rzeczywistych pozytywów poprawnie zidentyfikowanych przez klasyfikator wynosi

- Odsetek wyników fałszywie dodatnich (FPR) :
Odsetek rzeczywistych negatywów błędnie sklasyfikowanych jako pozytywne



Zatem na progu 0,5:
- Prawdziwie dodatni współczynnik (czułość): 0,8
- Wskaźnik wyników fałszywie dodatnich: 0
Interpretacja jest taka, że model przy tym progu poprawnie identyfikuje 80% faktycznie pozytywnych wyników (TPR), ale błędnie klasyfikuje 0% rzeczywistych negatywów jako pozytywne (FPR).
Odpowiednio dla różnych progów otrzymamy,
Przypadek 2: Próg = 0,7
Prawdziwe etykiety | Przewidywane prawdopodobieństwa | Przewidywane etykiety |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 0 |
Matryca zamieszania oparta na powyższych przewidywaniach
| Przewidywanie = 0 | Przewidywanie = 1 |
|---|---|---|
Rzeczywisty = 0 | TP=5 | FN=0 |
Rzeczywisty = 1 | PR=2 | TN=3 |
Odpowiednio,
- Prawdziwie dodatni współczynnik (TPR) :
Proporcja rzeczywistych pozytywów poprawnie zidentyfikowanych przez klasyfikator wynosi

- Odsetek wyników fałszywie dodatnich (FPR) :
Odsetek rzeczywistych negatywów błędnie sklasyfikowanych jako pozytywne



Przypadek 3: Próg = 0,4
Prawdziwe etykiety | Przewidywane prawdopodobieństwa | Przewidywane etykiety |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matryca zamieszania oparta na powyższych przewidywaniach
| Przewidywanie = 0 | Przewidywanie = 1 |
|---|---|---|
Rzeczywisty = 0 | TP=4 | FN=1 |
Rzeczywisty = 1 | FP=0 | TN=5 |
Odpowiednio,
- Prawdziwie dodatni współczynnik (TPR) :
Proporcja rzeczywistych pozytywów poprawnie zidentyfikowanych przez klasyfikator wynosi
- Odsetek wyników fałszywie dodatnich (FPR) :
Odsetek rzeczywistych negatywów błędnie sklasyfikowanych jako pozytywne
Przypadek 4: Próg = 0,2
Prawdziwe etykiety | Przewidywane prawdopodobieństwa | Przewidywane etykiety |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 1 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 1 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matryca zamieszania oparta na powyższych przewidywaniach
| Przewidywanie = 0 | Przewidywanie = 1 |
|---|---|---|
Rzeczywisty = 0 | TP=2 | FN=3 |
Rzeczywisty = 1 | FP=0 | TN=5 |
Odpowiednio,
- Prawdziwie dodatni współczynnik (TPR) :
Proporcja rzeczywistych pozytywów poprawnie zidentyfikowanych przez klasyfikator wynosi

- Odsetek wyników fałszywie dodatnich (FPR) :
Odsetek rzeczywistych negatywów błędnie sklasyfikowanych jako pozytywne

Przypadek 5: Próg = 0,85
Prawdziwe etykiety | Przewidywane prawdopodobieństwa | Przewidywane etykiety |
|---|---|---|
| 1 | 0,8 | 0 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 0 |
| 0 | 0,55 | 0 |
Matryca zamieszania oparta na powyższych przewidywaniach
| Przewidywanie = 0 | Przewidywanie = 1 |
|---|---|---|
Rzeczywisty = 0 | TP=5 | FN=0 |
Rzeczywisty = 1 | PR=4 | TN=1 |
Odpowiednio,
- Prawdziwie dodatni współczynnik (TPR) :
Proporcja rzeczywistych pozytywów poprawnie zidentyfikowanych przez klasyfikator wynosi
- Odsetek wyników fałszywie dodatnich (FPR) :
Odsetek rzeczywistych negatywów błędnie sklasyfikowanych jako pozytywne


Na podstawie powyższego wyniku wykreślimy krzywą ROC
Python3
true_positive_rate>=> [>0.4>,>0.8>,>0.8>,>1.0>,>1>]> false_positive_rate>=> [>0>,>0>,>0>,>0.2>,>0.8>]> plt.plot(false_positive_rate, true_positive_rate,>'o-'>, label>=>'ROC'>)> plt.plot([>0>,>1>], [>0>,>1>],>'--'>, color>=>'grey'>, label>=>'Worst case'>)> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curve'>)> plt.legend()> plt.show()> |
>
>
Wyjście:
Z wykresu wynika, że:
- Szara linia przerywana przedstawia najgorszy scenariusz, w którym przewidywania modelu, tj. TPR wynoszą FPR, są takie same. Tę ukośną linię uważa się za najgorszy scenariusz, wskazujący równe prawdopodobieństwo wyników fałszywie dodatnich i fałszywie ujemnych.
- Gdy punkty odbiegają od losowej linii domysłów w kierunku lewego górnego rogu, wydajność modelu poprawia się.
- Pole pod krzywą (AUC) jest ilościową miarą zdolności dyskryminacyjnej modelu. Wyższa wartość AUC, bliższa 1,0, wskazuje na lepszą wydajność. Najlepsza możliwa wartość AUC wynosi 1,0, co odpowiada modelowi, który osiąga 100% czułość i 100% swoistość.
Podsumowując, krzywa charakterystyki operacyjnej odbiornika (ROC) służy jako graficzne przedstawienie kompromisu pomiędzy współczynnikiem prawdziwie dodatnim (czułością) modelu klasyfikacji binarnej a współczynnikiem fałszywie dodatnim przy różnych progach decyzyjnych. Gdy krzywa z wdziękiem wznosi się w kierunku lewego górnego rogu, oznacza to godną pochwały zdolność modelu do rozróżniania przypadków pozytywnych i negatywnych w całym zakresie progów ufności. Ta trajektoria wzrostowa wskazuje na lepszą wydajność i wyższą czułość osiągniętą przy jednoczesnej minimalizacji fałszywych alarmów. Progi z adnotacjami, oznaczone jako A, B, C, D i E, zapewniają cenny wgląd w dynamiczne zachowanie modelu na różnych poziomach ufności.
Implementacja z wykorzystaniem dwóch różnych modeli
Instalowanie bibliotek
Python3
import> numpy as np> import> pandas as pd> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> |
>
>
Aby wyszkolić Losowy las I Regresja logistyczna modeli i aby przedstawić ich krzywe ROC z wynikami AUC, algorytm tworzy sztuczne dane klasyfikacji binarnej.
Generowanie danych i dzielenie danych
Python3
# Generate synthetic data for demonstration> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>2>, random_state>=>42>)> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y, test_size>=>0.2>, random_state>=>42>)> |
>
>
Stosując współczynnik podziału 80-20, algorytm tworzy sztuczne dane klasyfikacji binarnej z 20 cechami, dzieli je na zbiory uczące i testowe oraz przypisuje losowe ziarno, aby zapewnić powtarzalność.
Szkolenie różnych modeli
Python3
# Train two different models> logistic_model>=> LogisticRegression(random_state>=>42>)> logistic_model.fit(X_train, y_train)> random_forest_model>=> RandomForestClassifier(n_estimators>=>100>, random_state>=>42>)> random_forest_model.fit(X_train, y_train)> |
>
>
Wykorzystując stały losowy materiał siewny w celu zapewnienia powtarzalności, metoda inicjuje i trenuje model regresji logistycznej na zestawie szkoleniowym. W podobny sposób wykorzystuje dane szkoleniowe i te same losowe nasiona do inicjowania i uczenia modelu losowego lasu ze 100 drzewami.
Prognozy
Python3
# Generate predictions> y_pred_logistic>=> logistic_model.predict_proba(X_test)[:,>1>]> y_pred_rf>=> random_forest_model.predict_proba(X_test)[:,>1>]> |
>
>
Korzystanie z danych testowych i przeszkolony Regresja logistyczna modelu kod przewiduje prawdopodobieństwo klasy dodatniej. W podobny sposób, korzystając z danych testowych, wykorzystuje wyszkolony model Losowego Lasu do wygenerowania przewidywanych prawdopodobieństw dla klasy dodatniej.
Tworzenie ramki danych
Python3
# Create a DataFrame> test_df>=> pd.DataFrame(> >{>'True'>: y_test,>'Logistic'>: y_pred_logistic,>'RandomForest'>: y_pred_rf})> |
>
>
Korzystając z danych testowych, kod tworzy ramkę danych o nazwie test_df z kolumnami oznaczonymi jako True, Logistic i RandomForest, dodając prawdziwe etykiety i przewidywane prawdopodobieństwa z modeli Random Forest i Logistic Regression.
Narysuj krzywą ROC dla modeli
Python3
# Plot ROC curve for each model> plt.figure(figsize>=>(>7>,>5>))> for> model>in> [>'Logistic'>,>'RandomForest'>]:> >fpr, tpr, _>=> roc_curve(test_df[>'True'>], test_df[model])> >roc_auc>=> auc(fpr, tpr)> >plt.plot(fpr, tpr, label>=>f>'{model} (AUC = {roc_auc:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'r--'>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curves for Two Models'>)> plt.legend()> plt.show()> |
>
>
Wyjście:

Kod generuje wykres zawierający cyfry o wymiarach 8 na 6 cali. Oblicza krzywą AUC i ROC dla każdego modelu (las losowy i regresja logistyczna), a następnie wykreśla krzywą ROC. The Krzywa ROC w celu losowego zgadywania jest również reprezentowana przez czerwoną przerywaną linię, a etykiety, tytuł i legenda są ustawione do wizualizacji.
Jak używać ROC-AUC dla modelu wieloklasowego?
W przypadku ustawienia obejmującego wiele klas możemy po prostu zastosować metodologię „jeden na wszystkich” i uzyskamy jedną krzywą ROC dla każdej klasy. Załóżmy, że masz cztery klasy A, B, C i D, wówczas będą krzywe ROC i odpowiadające im wartości AUC dla wszystkich czterech klas, tj. gdy A będzie jedną klasą, a B, C i D łącznie będą innymi klasami podobnie B jest jedną klasą, a A, C i D łącznie tworzą inne klasy itd.
Ogólne kroki stosowania AUC-ROC w kontekście modelu klasyfikacji wieloklasowej są następujące:
Metodologia „jeden na wszystkich”:
- Dla każdej klasy w problemie wieloklasowym traktuj ją jako klasę dodatnią, łącząc wszystkie inne klasy w klasę ujemną.
- Trenuj klasyfikator binarny dla każdej klasy względem pozostałych klas.
Oblicz AUC-ROC dla każdej klasy:
- Tutaj wykreślamy krzywą ROC dla danej klasy w porównaniu z resztą.
- Narysuj krzywe ROC dla każdej klasy na tym samym wykresie. Każda krzywa reprezentuje wydajność dyskryminacji modelu dla określonej klasy.
- Sprawdź wyniki AUC dla każdej klasy. Wyższy wynik AUC wskazuje na lepszą dyskryminację dla tej konkretnej klasy.
Implementacja AUC-ROC w klasyfikacji wieloklasowej
Importowanie bibliotek
Python3
import> numpy as np> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.preprocessing>import> label_binarize> from> sklearn.multiclass>import> OneVsRestClassifier> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> from> itertools>import> cycle> |
>
>
Program tworzy sztuczne dane wieloklasowe, dzieli je na zbiory uczące i testowe, a następnie wykorzystuje Klasyfikator jeden kontra reszta technika uczenia klasyfikatorów zarówno dla losowego lasu, jak i regresji logistycznej. Na koniec wykreśla wieloklasowe krzywe ROC obu modeli, aby pokazać, jak dobrze rozróżniają one różne klasy.
Generowanie danych i dzielenie
Python3
# Generate synthetic multiclass data> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>3>, n_informative>=>10>, random_state>=>42>)> # Binarize the labels> y_bin>=> label_binarize(y, classes>=>np.unique(y))> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y_bin, test_size>=>0.2>, random_state>=>42>)> |
>
>
Trzy klasy i dwadzieścia funkcji tworzą syntetyczne dane wieloklasowe generowane przez kod. Po binaryzacji etykiet dane są dzielone na zbiory uczące i testujące w stosunku 80-20.
Modele szkoleniowe
Python3
# Train two different multiclass models> logistic_model>=> OneVsRestClassifier(LogisticRegression(random_state>=>42>))> logistic_model.fit(X_train, y_train)> rf_model>=> OneVsRestClassifier(> >RandomForestClassifier(n_estimators>=>100>, random_state>=>42>))> rf_model.fit(X_train, y_train)> |
>
>
Program uczy dwa modele wieloklasowe: model Random Forest ze 100 estymatorami oraz model regresji logistycznej z Podejście jeden kontra reszta . Do zestawu szkoleniowego danych dopasowuje się oba modele.
Wykreślanie krzywej AUC-ROC
Python3
# Compute ROC curve and ROC area for each class> fpr>=> dict>()> tpr>=> dict>()> roc_auc>=> dict>()> models>=> [logistic_model, rf_model]> plt.figure(figsize>=>(>6>,>5>))> colors>=> cycle([>'aqua'>,>'darkorange'>])> for> model, color>in> zip>(models, colors):> >for> i>in> range>(model.classes_.shape[>0>]):> >fpr[i], tpr[i], _>=> roc_curve(> >y_test[:, i], model.predict_proba(X_test)[:, i])> >roc_auc[i]>=> auc(fpr[i], tpr[i])> >plt.plot(fpr[i], tpr[i], color>=>color, lw>=>2>,> >label>=>f>'{model.__class__.__name__} - Class {i} (AUC = {roc_auc[i]:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'k--'>, lw>=>2>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'Multiclass ROC Curve with Logistic Regression and Random Forest'>)> plt.legend(loc>=>'lower right'>)> plt.show()> |
>
>
Wyjście:

Krzywe ROC i wyniki AUC modeli Random Forest i Logistic Regression są obliczane za pomocą kodu dla każdej klasy. Następnie wykreśla się wieloklasowe krzywe ROC, pokazując skuteczność dyskryminacji każdej klasy i przedstawiając linię reprezentującą losowe zgadywanie. Powstały wykres umożliwia graficzną ocenę skuteczności klasyfikacji modeli.
Wniosek
W uczeniu maszynowym wydajność modeli klasyfikacji binarnej ocenia się za pomocą kluczowej metryki zwanej obszarem pod charakterystyką operacyjną odbiornika (AUC-ROC). Pokazuje, jak w przypadku różnych progów decyzyjnych zachodzi kompromis między czułością a swoistością. Większą różnicę między przypadkami pozytywnymi i negatywnymi zazwyczaj wykazuje model z wyższym wynikiem AUC. Podczas gdy 0,5 oznacza szansę, 1 oznacza doskonałe wykonanie. Optymalizacja i wybór modelu są wspomagane przez przydatne informacje, jakie oferuje krzywa AUC-ROC na temat zdolności modelu do rozróżniania klas. Podczas pracy z niezrównoważonymi zbiorami danych lub aplikacjami, w których wyniki fałszywie dodatnie i fałszywie ujemne mają różne koszty, jest to szczególnie przydatne jako miara kompleksowa.
Często zadawane pytania dotyczące krzywej AUC ROC w uczeniu maszynowym
1. Co to jest krzywa AUC-ROC?
W przypadku różnych progów klasyfikacji kompromis między częstością wyników prawdziwie dodatnich (czułość) a częstością wyników fałszywie dodatnich (swoistość) przedstawiono graficznie za pomocą krzywej AUC-ROC.
2. Jak wygląda idealna krzywa AUC-ROC?
Obszar 1 na idealnej krzywej AUC-ROC oznaczałby, że model osiąga optymalną czułość i swoistość przy wszystkich progach.
3. Co oznacza wartość AUC wynosząca 0,5?
AUC wynoszące 0,5 wskazuje, że wydajność modelu jest porównywalna z wydajnością losowego przypadku. Sugeruje to brak zdolności rozróżniania.
4. Czy AUC-ROC można wykorzystać do klasyfikacji wieloklasowej?
sortuj listę tablic
AUC-ROC jest często stosowany w kwestiach związanych z klasyfikacją binarną. Przy klasyfikacji wieloklasowej można uwzględnić różnice takie jak makrośrednie lub mikrośrednie AUC.
5. W jaki sposób krzywa AUC-ROC jest przydatna w ocenie modelu?
Zdolność modelu do rozróżniania klas kompleksowo podsumowuje krzywa AUC-ROC. Jest to szczególnie przydatne podczas pracy z niezrównoważonymi zbiorami danych.