Uczenie maszynowe jest gałęzią Sztuczna inteligencja która koncentruje się na opracowywaniu modeli i algorytmów, które umożliwiają komputerom uczenie się na podstawie danych i doskonalenie na podstawie wcześniejszych doświadczeń, bez konieczności bezpośredniego programowania dla każdego zadania. Krótko mówiąc, ML uczy systemy myśleć i rozumieć jak ludzie, ucząc się na danych.
W tym artykule omówimy różne rodzaje algorytmy uczenia maszynowego które są ważne dla przyszłych wymagań. Nauczanie maszynowe to ogólnie system szkoleniowy, który ma na celu wyciąganie wniosków z przeszłych doświadczeń i poprawę wyników w miarę upływu czasu. Nauczanie maszynowe pomaga przewidzieć ogromne ilości danych. Pomaga dostarczać szybkie i dokładne wyniki, aby uzyskać zyskowne możliwości.
Rodzaje uczenia maszynowego
Istnieje kilka rodzajów uczenia maszynowego, każdy o specjalnych cechach i zastosowaniach. Oto niektóre z głównych typów algorytmów uczenia maszynowego:
- Nadzorowane uczenie maszynowe
- Uczenie maszynowe bez nadzoru
- Częściowo nadzorowane uczenie maszynowe
- Uczenie się przez wzmacnianie
Rodzaje uczenia maszynowego
równa się metoda w Javie
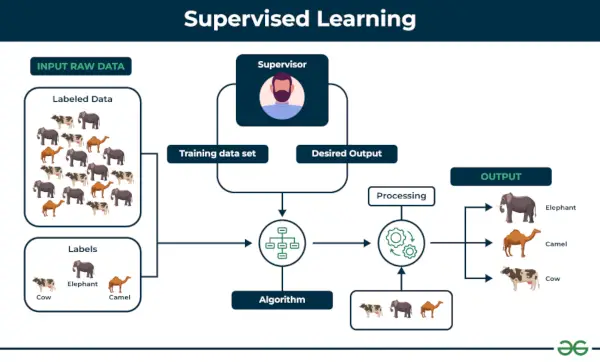
1. Nadzorowane uczenie maszynowe
Nadzorowana nauka definiuje się jako sytuację, w której model jest szkolony na a Oznaczony zbiór danych . Oznaczone zestawy danych mają zarówno parametry wejściowe, jak i wyjściowe. W Nadzorowana nauka Algorytmy uczą się mapować punkty pomiędzy wejściami i prawidłowymi wyjściami. Zawiera zarówno zbiory danych szkoleniowych, jak i walidacyjnych.
Nadzorowana nauka
Zrozummy to na przykładzie.
Przykład: Rozważmy scenariusz, w którym musisz zbudować klasyfikator obrazu, aby rozróżnić koty i psy. Jeśli podasz algorytmowi zbiory danych zawierające obrazy psów i kotów, maszyna nauczy się klasyfikować psa i kota na podstawie tych oznaczonych obrazów. Kiedy wprowadzimy nowe zdjęcia psa lub kota, których nigdy wcześniej nie widział, użyje wyuczonych algorytmów i odgadnie, czy jest to pies czy kot. Oto jak Nadzorowana nauka działa, a jest to w szczególności klasyfikacja obrazu.
Istnieją dwie główne kategorie uczenia się nadzorowanego, które wymieniono poniżej:
- Klasyfikacja
- Regresja
Klasyfikacja
Klasyfikacja zajmuje się przewidywaniem kategoryczny zmienne docelowe, które reprezentują dyskretne klasy lub etykiety. Na przykład klasyfikowanie wiadomości e-mail jako spam lub nie spam lub przewidywanie, czy u pacjenta występuje wysokie ryzyko chorób serca. Algorytmy klasyfikacji uczą się odwzorowywać cechy wejściowe na jedną z predefiniowanych klas.
Oto kilka algorytmów klasyfikacji:
- Regresja logistyczna
- Maszyna wektorów nośnych
- Losowy las
- Drzewo decyzyjne
- K-najbliżsi sąsiedzi (KNN)
- Naiwny Bayes
Regresja
Regresja z drugiej strony zajmuje się przewidywaniem ciągły zmienne docelowe, które reprezentują wartości liczbowe. Na przykład przewidywanie ceny domu na podstawie jego wielkości, lokalizacji i udogodnień lub prognozowanie sprzedaży produktu. Algorytmy regresji uczą się odwzorowywać cechy wejściowe na ciągłą wartość liczbową.
wrzuć obsługę wyjątków Java
Oto kilka algorytmów regresji:
- Regresja liniowa
- Regresja wielomianowa
- Regresja grzbietu
- Regresja Lassa
- Drzewo decyzyjne
- Losowy las
Zalety nadzorowanego uczenia maszynowego
- Nadzorowana nauka modele mogą mieć wysoką dokładność podczas szkolenia oznaczone dane .
- Proces podejmowania decyzji w modelach uczenia się pod nadzorem często można interpretować.
- Często można go używać we wstępnie wyszkolonych modelach, co oszczędza czas i zasoby podczas opracowywania nowych modeli od podstaw.
Wady nadzorowanego uczenia maszynowego
- Ma ograniczenia w zakresie rozpoznawania wzorców i może borykać się z niewidocznymi lub nieoczekiwanymi wzorcami, których nie ma w danych szkoleniowych.
- Może to być czasochłonne i kosztowne, ponieważ zależy od tego oznakowane tylko dane.
- Może to prowadzić do słabych uogólnień w oparciu o nowe dane.
Zastosowania uczenia się pod nadzorem
Uczenie się pod nadzorem jest wykorzystywane w wielu różnych zastosowaniach, w tym:
- Klasyfikacja obrazu : Identyfikuj obiekty, twarze i inne cechy na obrazach.
- Przetwarzanie języka naturalnego: Wyodrębnij informacje z tekstu, takie jak tonacja, encje i relacje.
- Rozpoznawanie mowy : Konwertuj język mówiony na tekst.
- Systemy rekomendacji : twórz spersonalizowane rekomendacje dla użytkowników.
- Analityka predykcyjna : Przewiduj wyniki, takie jak sprzedaż, odpływ klientów i ceny akcji.
- Diagnoza medyczna : Wykrywanie chorób i innych schorzeń.
- Wykrywanie oszustw : Identyfikuj fałszywe transakcje.
- Pojazdy autonomiczne : Rozpoznawanie i reagowanie na obiekty w otoczeniu.
- Wykrywanie spamu e-mailowego : klasyfikowanie wiadomości e-mail jako spamu lub nie spamu.
- Kontrola jakości w produkcji : Sprawdź produkty pod kątem wad.
- Punktacja kredytowa : Ocena ryzyka niespłacenia pożyczki przez pożyczkobiorcę.
- Hazard : Rozpoznawaj postacie, analizuj zachowanie graczy i twórz NPC.
- Wsparcie klienta : Automatyzuj zadania obsługi klienta.
- Prognoza pogody : prognozuj temperaturę, opady i inne parametry meteorologiczne.
- Analityka sportowa : Analizuj wydajność graczy, prognozuj gry i optymalizuj strategie.
2. Uczenie maszynowe bez nadzoru
Uczenie się bez nadzoru Uczenie się bez nadzoru to rodzaj techniki uczenia maszynowego, w której algorytm odkrywa wzorce i relacje przy użyciu nieoznaczonych danych. W przeciwieństwie do uczenia się nadzorowanego, uczenie się bez nadzoru nie polega na dostarczaniu algorytmowi oznaczonych docelowych wyników. Podstawowym celem uczenia się bez nadzoru jest często odkrywanie ukrytych wzorców, podobieństw lub klastrów w danych, które można następnie wykorzystać do różnych celów, takich jak eksploracja danych, wizualizacja, redukcja wymiarowości i nie tylko.
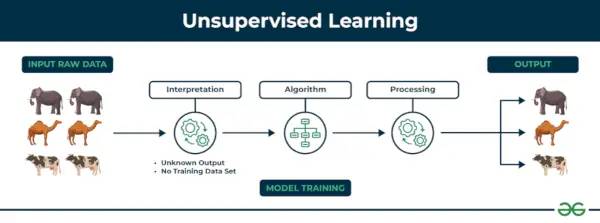
Uczenie się bez nadzoru
Zrozummy to na przykładzie.
Przykład: Weź pod uwagę, że masz zbiór danych zawierający informacje o zakupach dokonanych w sklepie. Dzięki grupowaniu algorytm może grupować te same zachowania zakupowe wśród Ciebie i innych klientów, co ujawnia potencjalnych klientów bez wcześniej zdefiniowanych etykiet. Tego typu informacje mogą pomóc firmom w pozyskiwaniu klientów docelowych, a także identyfikowaniu wartości odstających.
Istnieją dwie główne kategorie uczenia się bez nadzoru, które wymieniono poniżej:
- Grupowanie
- Stowarzyszenie
Grupowanie
Grupowanie to proces grupowania punktów danych w klastry na podstawie ich podobieństwa. Technika ta jest przydatna do identyfikowania wzorców i relacji w danych bez potrzeby stosowania oznaczonych przykładów.
program macierzowy w języku c
Oto niektóre algorytmy grupowania:
- Algorytm grupowania K-średnich
- Algorytm przesunięcia średniego
- Algorytm DBSCAN
- Analiza głównych składowych
- Niezależna analiza komponentów
Stowarzyszenie
Naucz się zasad skojarzeń ing to technika odkrywania relacji między elementami w zbiorze danych. Identyfikuje reguły, które wskazują, że obecność jednego przedmiotu implikuje obecność innego przedmiotu z określonym prawdopodobieństwem.
Oto niektóre algorytmy uczenia się reguł asocjacyjnych:
- Algorytm Aprioriego
- Blask
- Algorytm wzrostu FP
Zalety nienadzorowanego uczenia maszynowego
- Pomaga odkryć ukryte wzorce i różne relacje pomiędzy danymi.
- Używany do zadań takich jak segmentacja klientów, wykrywanie anomalii, I eksploracja danych .
- Nie wymaga etykietowania danych i zmniejsza wysiłek związany z etykietowaniem danych.
Wady nienadzorowanego uczenia maszynowego
- Bez użycia etykiet przewidzenie jakości wyników modelu może być trudne.
- Interpretowalność skupień może nie być jasna i może nie mieć znaczących interpretacji.
- Posiada techniki takie jak autoenkodery I redukcja wymiarowości które można wykorzystać do wyodrębnienia znaczących funkcji z surowych danych.
Zastosowania uczenia się bez nadzoru
Oto kilka typowych zastosowań uczenia się bez nadzoru:
- Grupowanie : Grupuj podobne punkty danych w klastry.
- Wykrywanie anomalii : Identyfikuj wartości odstające lub anomalie w danych.
- Redukcja wymiarowości : Zmniejsz wymiar danych, zachowując jednocześnie istotne informacje.
- Systemy rekomendacji : sugerowanie użytkownikom produktów, filmów lub treści na podstawie ich historycznych zachowań lub preferencji.
- Modelowanie tematyczne : Odkryj ukryte tematy w zbiorze dokumentów.
- Oszacowanie gęstości : Oszacuj funkcję gęstości prawdopodobieństwa danych.
- Kompresja obrazu i wideo : Zmniejsz ilość miejsca wymaganego do przechowywania treści multimedialnych.
- Wstępne przetwarzanie danych : Pomoc przy zadaniach wstępnego przetwarzania danych, takich jak czyszczenie danych, przypisywanie brakujących wartości i skalowanie danych.
- Analiza koszyka rynkowego : Odkryj powiązania między produktami.
- Analiza danych genomowych : Identyfikacja wzorców lub grupowanie genów o podobnych profilach ekspresji.
- Segmentacja obrazu : Podziel obrazy na znaczące regiony.
- Wykrywanie społeczności w sieciach społecznościowych : Zidentyfikuj społeczności lub grupy osób o podobnych zainteresowaniach lub powiązaniach.
- Analiza zachowań klientów : odkryj wzorce i spostrzeżenia, aby uzyskać lepszy marketing i rekomendacje produktów.
- Rekomendacja treści : klasyfikowanie i oznaczanie treści, aby ułatwić polecanie użytkownikom podobnych elementów.
- Eksploracyjna analiza danych (EDA) : Przeglądaj dane i zdobywaj wiedzę przed zdefiniowaniem konkretnych zadań.
3. Uczenie się częściowo nadzorowane
Uczenie się częściowo nadzorowane to algorytm uczenia maszynowego, który działa pomiędzy nadzorowane i bez nadzoru uczy się, więc używa obu oznakowane i nieoznaczone dane. Jest to szczególnie przydatne, gdy uzyskanie oznaczonych etykiet danych jest kosztowne, czasochłonne lub wymagające dużych zasobów. Takie podejście jest przydatne, gdy zbiór danych jest kosztowny i czasochłonny. Uczenie się częściowo nadzorowane wybiera się, gdy oznaczone dane wymagają umiejętności i odpowiednich zasobów, aby móc je szkolić lub się na nich uczyć.
Technik tych używamy, gdy mamy do czynienia z danymi, które są trochę oznaczone, a pozostała duża ich część jest nieoznaczona. Możemy użyć technik bez nadzoru do przewidywania etykiet, a następnie przekazać te etykiety technikom nadzorowanym. Technikę tę stosuje się głównie w przypadku zbiorów danych obrazowych, gdzie zazwyczaj nie wszystkie obrazy są opatrzone etykietą.
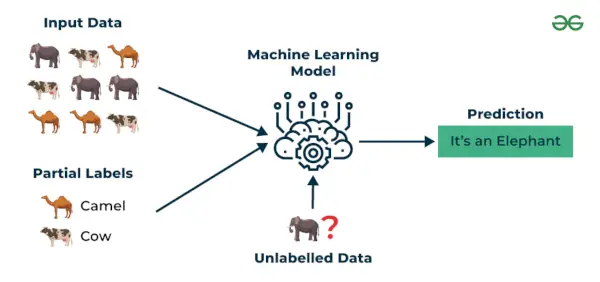
Uczenie się częściowo nadzorowane
Zrozummy to na przykładzie.
Przykład : Weź pod uwagę, że budujemy model tłumaczenia językowego, ponieważ oznaczanie tłumaczeń dla każdej pary zdań może wymagać dużych zasobów. Umożliwia modelom uczenie się na podstawie par zdań oznaczonych i nieoznaczonych, dzięki czemu są one dokładniejsze. Technika ta doprowadziła do znacznej poprawy jakości usług tłumaczeń maszynowych.
Rodzaje metod uczenia się częściowo nadzorowanego
Istnieje wiele różnych metod uczenia się częściowo nadzorowanego, każda z nich ma swoją własną charakterystykę. Niektóre z najczęstszych to:
byki kontra wół
- Uczenie się częściowo nadzorowane w oparciu o grafy: Podejście to wykorzystuje wykres do przedstawienia relacji między punktami danych. Wykres jest następnie używany do propagowania etykiet od oznaczonych punktów danych do nieoznaczonych punktów danych.
- Propagacja etykiety: Podejście to iteracyjnie propaguje etykiety z oznaczonych punktów danych do nieoznaczonych punktów danych w oparciu o podobieństwa między punktami danych.
- Wspólne szkolenie: To podejście szkoli dwa różne modele uczenia maszynowego na różnych podzbiorach danych bez etykiet. Obydwa modele są następnie wykorzystywane do wzajemnego oznaczania przewidywań.
- Samodzielny trening: To podejście szkoli model uczenia maszynowego na danych z etykietą, a następnie wykorzystuje model do przewidywania etykiet dla danych bez etykiet. Następnie model jest ponownie szkolony na danych oznaczonych etykietami i przewidywanych etykietach danych bez etykiet.
- Generacyjne sieci przeciwstawne (GAN) : Sieci GAN to rodzaj algorytmu głębokiego uczenia się, który można wykorzystać do generowania syntetycznych danych. Sieci GAN można wykorzystać do generowania nieoznaczonych danych na potrzeby uczenia się częściowo nadzorowanego poprzez uczenie dwóch sieci neuronowych, generatora i dyskryminatora.
Zalety częściowo nadzorowanego uczenia maszynowego
- Prowadzi to do lepszej generalizacji w porównaniu do Nadzorowana nauka, ponieważ pobiera zarówno dane oznaczone, jak i nieoznaczone.
- Można zastosować do szerokiego zakresu danych.
Wady częściowo nadzorowanego uczenia maszynowego
- Częściowo nadzorowany metody mogą być bardziej złożone we wdrażaniu w porównaniu z innymi podejściami.
- To nadal trochę wymaga oznaczone dane które nie zawsze są dostępne lub łatwe do uzyskania.
- Nieoznaczone dane mogą odpowiednio wpłynąć na wydajność modelu.
Zastosowania uczenia się częściowo nadzorowanego
Oto kilka typowych zastosowań uczenia się częściowo nadzorowanego:
- Klasyfikacja obrazu i rozpoznawanie obiektów : Zwiększ dokładność modeli, łącząc mały zestaw obrazów oznaczonych etykietami z większym zestawem obrazów bez etykiet.
- Przetwarzanie języka naturalnego (NLP) : Zwiększ wydajność modeli językowych i klasyfikatorów, łącząc niewielki zestaw danych tekstowych z etykietami z dużą ilością tekstu bez etykiet.
- Rozpoznawanie mowy: Popraw dokładność rozpoznawania mowy, wykorzystując ograniczoną ilość transkrybowanych danych mowy i bardziej rozbudowany zestaw nieoznaczonych plików audio.
- Systemy rekomendacji : Popraw dokładność spersonalizowanych rekomendacji, uzupełniając rzadki zestaw interakcji użytkownik-element (dane z etykietami) dużą ilością nieoznaczonych danych o zachowaniach użytkowników.
- Opieka zdrowotna i obrazowanie medyczne : Ulepsz analizę obrazów medycznych, wykorzystując mały zestaw oznaczonych obrazów medycznych wraz z większym zestawem obrazów nieoznaczonych.
4. Uczenie maszynowe ze wzmocnieniem
Uczenie maszynowe ze wzmocnieniem Algorytm to metoda uczenia się, która wchodzi w interakcję ze środowiskiem, generując działania i odkrywając błędy. Próba, błąd i opóźnienie to najważniejsze cechy uczenia się przez wzmacnianie. W tej technice model stale zwiększa swoje wyniki, korzystając z informacji zwrotnej opartej na nagrodzie, aby poznać zachowanie lub wzorzec. Algorytmy te są specyficzne dla konkretnego problemu, np. Samochód Google Self Driving, AlphaGo, w którym bot konkuruje z ludźmi, a nawet z samym sobą, aby uzyskać coraz lepsze wyniki w grze Go. Za każdym razem, gdy dostarczamy dane, uczą się i dodają je do swojej wiedzy, która jest danymi szkoleniowymi. Zatem im więcej się uczy, tym lepiej zostaje wyszkolony, a tym samym doświadczony.
Oto niektóre z najpopularniejszych algorytmów uczenia się przez wzmacnianie:
- Q-learning: Q-learning to pozbawiony modelu algorytm RL, który uczy się funkcji Q, która odwzorowuje stany na działania. Funkcja Q szacuje oczekiwaną nagrodę za podjęcie określonej akcji w danym stanie.
- SARSA (stan-akcja-nagroda-stan-akcja): SARSA to kolejny pozbawiony modelu algorytm RL, który uczy się funkcji Q. Jednak w przeciwieństwie do Q-learningu, SARSA aktualizuje funkcję Q pod kątem faktycznie podjętej akcji, a nie działania optymalnego.
- Głębokie Q-learning : Deep Q-learning to połączenie Q-learningu i głębokiego uczenia się. Deep Q-learning wykorzystuje sieć neuronową do reprezentowania funkcji Q, która pozwala mu uczyć się złożonych relacji między stanami i działaniami.
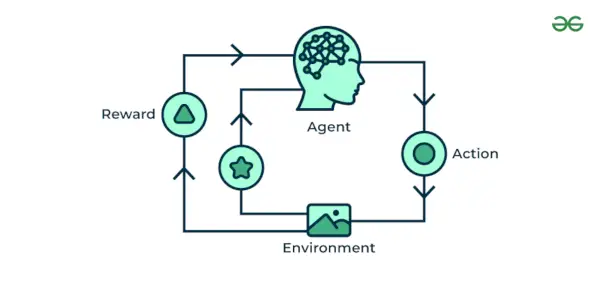
Uczenie maszynowe ze wzmocnieniem
Rozumiemy to na przykładach.
Przykład: Weź pod uwagę, że trenujesz sztuczna inteligencja agenta do gry takiej jak szachy. Agent bada różne ruchy i otrzymuje pozytywną lub negatywną informację zwrotną w zależności od wyniku. Uczenie się przez wzmacnianie znajduje również zastosowania, w których uczą się wykonywać zadania poprzez interakcję z otoczeniem.
Rodzaje uczenia maszynowego ze wzmocnieniem
Istnieją dwa główne typy uczenia się przez wzmacnianie:
Pozytywne wzmocnienie
- Nagradza agenta za podjęcie pożądanego działania.
- Zachęca agenta do powtórzenia zachowania.
- Przykłady: wręczenie psu smakołyku do siedzenia, przyznanie punktu w grze za poprawną odpowiedź.
Negatywne wzmocnienie
- Usuwa niepożądany bodziec, aby zachęcić do pożądanego zachowania.
- Zniechęca agenta do powtarzania danego zachowania.
- Przykłady: wyłączenie głośnego brzęczyka po naciśnięciu dźwigni, uniknięcie kary poprzez wykonanie zadania.
Zalety uczenia maszynowego ze wzmocnieniem
- Posiada autonomiczny proces decyzyjny, który jest dobrze dostosowany do zadań i który może nauczyć się podejmowania sekwencji decyzji, takich jak robotyka i granie w gry.
- Technikę tę preferuje się, aby osiągnąć długotrwałe rezultaty, które są bardzo trudne do osiągnięcia.
- Służy do rozwiązywania złożonych problemów, których nie można rozwiązać konwencjonalnymi technikami.
Wady uczenia maszynowego ze wzmocnieniem
- Szkolenie Wzmocnienie Agenci uczący się mogą być kosztowne obliczeniowo i czasochłonne.
- Uczenie się przez wzmacnianie nie jest lepszym rozwiązaniem niż rozwiązywanie prostych problemów.
- Wymaga dużej ilości danych i obliczeń, co sprawia, że jest niepraktyczne i kosztowne.
Zastosowania uczenia maszynowego ze wzmocnieniem
Oto kilka zastosowań uczenia się przez wzmacnianie:
- Granie w gry : RL może nauczyć agentów grać w gry, nawet te złożone.
- Robotyka : RL może uczyć roboty samodzielnego wykonywania zadań.
- Pojazdy autonomiczne : RL może pomóc samochodom autonomicznym w nawigacji i podejmowaniu decyzji.
- Systemy rekomendacji : RL może ulepszyć algorytmy rekomendacji, ucząc się preferencji użytkownika.
- Opieka zdrowotna : RL można wykorzystać do optymalizacji planów leczenia i odkrywania leków.
- Przetwarzanie języka naturalnego (NLP) : RL może być używany w systemach dialogowych i chatbotach.
- Finanse i handel : RL może być używany do handlu algorytmicznego.
- Zarządzanie łańcuchem dostaw i zapasami : RL można wykorzystać do optymalizacji operacji w łańcuchu dostaw.
- Zarządzanie energią : RL można wykorzystać do optymalizacji zużycia energii.
- Gry AI : RL można wykorzystać do tworzenia bardziej inteligentnych i adaptacyjnych NPC w grach wideo.
- Adaptacyjni asystenci osobiści : RL można wykorzystać do ulepszenia osobistych asystentów.
- Rzeczywistość wirtualna (VR) i rzeczywistość rozszerzona (AR): RL można wykorzystać do tworzenia wciągających i interaktywnych doświadczeń.
- Kontrola przemysłowa : RL można wykorzystać do optymalizacji procesów przemysłowych.
- Edukacja : RL można wykorzystać do tworzenia adaptacyjnych systemów uczenia się.
- Rolnictwo : RL można wykorzystać do optymalizacji działań rolniczych.
Koniecznie sprawdź, nasz szczegółowy artykuł na temat : Algorytmy uczenia maszynowego
pyspark sql
Wniosek
Podsumowując, każdy rodzaj uczenia maszynowego służy swojemu własnemu celowi i przyczynia się do ogólnej roli w rozwoju ulepszonych możliwości przewidywania danych, a także może zmienić różne branże, takie jak Nauka o danych . Pomaga radzić sobie z masową produkcją danych i zarządzaniem zbiorami danych.
Rodzaje uczenia maszynowego – często zadawane pytania
1. Jakie wyzwania stoją przed uczeniem się pod nadzorem?
Niektóre z wyzwań stojących przed uczeniem się pod nadzorem obejmują głównie zajęcie się brakiem równowagi klas, wysokiej jakości oznakowanymi danymi i unikaniem nadmiernego dopasowania, gdy modele słabo radzą sobie z danymi w czasie rzeczywistym.
2. Gdzie możemy zastosować uczenie nadzorowane?
Uczenie nadzorowane jest powszechnie stosowane do zadań takich jak analizowanie wiadomości e-mail ze spamem, rozpoznawanie obrazów i analiza nastrojów.
3. Jak wygląda przyszłość uczenia maszynowego?
Uczenie maszynowe jako perspektywa na przyszłość może sprawdzić się w takich obszarach, jak analiza pogody i klimatu, systemy opieki zdrowotnej i modelowanie autonomiczne.
4. Jakie są różne rodzaje uczenia maszynowego?
Istnieją trzy główne typy uczenia maszynowego:
- Nadzorowana nauka
- Uczenie się bez nadzoru
- Uczenie się przez wzmacnianie
5. Jakie są najpopularniejsze algorytmy uczenia maszynowego?
Do najpopularniejszych algorytmów uczenia maszynowego należą:
- Regresja liniowa
- Regresja logistyczna
- Maszyny wektorów pomocniczych (SVM)
- K-najbliżsi sąsiedzi (KNN)
- Drzewa decyzyjne
- Losowe lasy
- Sztuczne sieci neuronowe