Arkusze Excela są bardzo intuicyjne i przyjazne dla użytkownika, co czyni je idealnymi do manipulowania dużymi zbiorami danych nawet dla mniej technicznych osób. Jeśli szukasz miejsc, w których możesz nauczyć się manipulować i automatyzować rzeczy w plikach Excel za pomocą Pyton , nie szukaj dalej. Jesteś we właściwym miejscu.
W tym artykule dowiesz się, jak z niego korzystać Pandy do pracy z arkuszami kalkulacyjnymi Excel. W tym artykule dowiemy się o:
- Czytać Plik Excel używając Pand w Pythonie
- Instalowanie i importowanie Pand
- Czytanie wielu arkuszy Excela za pomocą Pand
- Zastosowanie różnych funkcji Pand
Czytanie pliku Excel przy użyciu Pand w Pythonie
Instalowanie Pand
Aby zainstalować Pandy w Pythonie, możemy użyć następującego polecenia w wierszu poleceń:
konwersja int na string w Javie
pip install pandas>
Aby zainstalować Pandy w Anacondzie, możemy użyć następującego polecenia w terminalu Anaconda:
conda install pandas>
Importowanie Pand
Na początek musimy zaimportować moduł Pandas, co można zrobić wydając komendę:
Python3
import> pandas as pd> |
>
>
Plik wejściowy: Załóżmy, że plik Excel wygląda tak
Arkusz 1:

Arkusz 1
Arkusz 2:
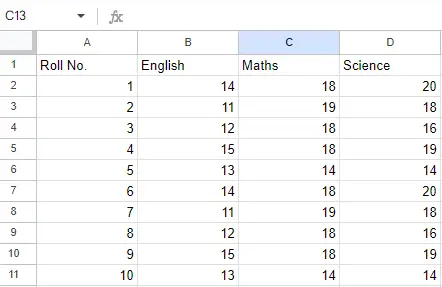
Arkusz 2
Teraz możemy zaimportować plik Excel za pomocą funkcji read_excel w Pandach, aby odczytać plik Excel za pomocą Pand w Pythonie. Druga instrukcja odczytuje dane z Excela i zapisuje je w ramce danych pandy, która jest reprezentowana przez zmienną newData.
Python3
df>=> pd.read_excel(>'Example.xlsx'>)> print>(df)> |
>
>
Wyjście:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20>
Ładowanie wielu arkuszy przy użyciu metody Concat().
Jeśli w skoroszycie programu Excel znajduje się wiele arkuszy, polecenie zaimportuje dane z pierwszego arkusza. Aby utworzyć ramkę danych zawierającą wszystkie arkusze skoroszytu, najprostszą metodą jest oddzielne utworzenie różnych ramek danych, a następnie ich połączenie. Metoda read_excel przyjmuje argument nazwa_arkusza i indeks_kol gdzie możemy określić arkusz z którego ma być wykonana ramka, a indeks_col określa kolumnę tytułową, jak pokazano poniżej:
Przykład:
Trzecia instrukcja łączy oba arkusze. Teraz, aby sprawdzić całą ramkę danych, możemy po prostu uruchomić następujące polecenie:
Python3
file> => 'Example.xlsx'> sheet1>=> pd.read_excel(>file>,> >sheet_name>=> 0>,> >index_col>=> 0>)> sheet2>=> pd.read_excel(>file>,> >sheet_name>=> 1>,> >index_col>=> 0>)> # concatinating both the sheets> newData>=> pd.concat([sheet1, sheet2])> print>(newData)> |
>
>
Wyjście:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Metody Head() i Tail() w Pandach
Aby wyświetlić 5 kolumn od góry i od dołu ramki danych, możemy uruchomić polecenie. Ten głowa() I ogon() Metoda przyjmuje również argumenty jako liczby określające liczbę wyświetlanych kolumn.
Python3
print>(newData.head())> print>(newData.tail())> |
>
>
Wyjście:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Metoda kształtu().
The metoda kształtu(). można użyć do wyświetlenia liczby wierszy i kolumn w ramce danych w następujący sposób:
Python3
newData.shape> |
>
>
Wyjście:
bash długość łańcucha
(20, 3)>
Metoda Sort_values() w Pandach
Jeśli jakakolwiek kolumna zawiera dane liczbowe, możemy posortować tę kolumnę za pomocą sort_values() metoda w pandach w następujący sposób:
Python3
sorted_column>=> newData.sort_values([>'English'>], ascending>=> False>)> |
>
>
Załóżmy teraz, że chcemy 5 pierwszych wartości posortowanej kolumny. Możemy tutaj użyć metody head():
Python3
sorted_column.head(>5>)> |
>
>
Wyjście:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19>
Możemy to zrobić z dowolną kolumną numeryczną ramki danych, jak pokazano poniżej:
Python3
newData[>'Maths'>].head()> |
>
>
Wyjście:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64>
Metoda Pandy Description().
Załóżmy teraz, że nasze dane są głównie liczbowe. Możemy uzyskać informacje statystyczne, takie jak średnia, maksymalna, minimalna, itp. o ramce danych za pomocą opisać() sposób pokazany poniżej:
Python3
newData.describe()> |
>
>
Wyjście:
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000>
Można to również zrobić oddzielnie dla wszystkich kolumn liczbowych za pomocą następującego polecenia:
Python3
newData[>'English'>].mean()> |
>
>
Wyjście:
14.3>
Za pomocą odpowiednich metod można również obliczyć inne informacje statystyczne. Podobnie jak w programie Excel, można również stosować formuły i tworzyć kolumny obliczeniowe w następujący sposób:
Python3
newData[>'Total Marks'>]>=> >newData[>'English'>]>+> newData[>'Maths'>]>+> newData[>'Science'>]> newData[>'Total Marks'>].head()> |
zastąpienie ciągu w Javie
>
>
Wyjście:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64>
Po operacji na danych w ramce danych możemy wyeksportować dane z powrotem do pliku Excel metodą to_excel. W tym celu musimy określić wyjściowy plik Excel, w którym mają zostać zapisane przekształcone dane, jak pokazano poniżej:
Python3
newData.to_excel(>'Output File.xlsx'>)> |
>
>
Wyjście:
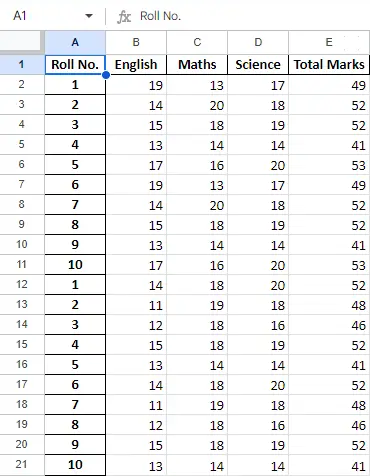
Arkusz końcowy